两周自制脚本语言-第7天 添加函数功能
Posted zcwang
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了两周自制脚本语言-第7天 添加函数功能相关的知识,希望对你有一定的参考价值。
第7天 添加函数功能
基本的函数定义与调用执行、引入闭包使Stone语言可以将变量赋值为函数,或将函数作为参数传递给其他函数
有些函数将有返回值的归为函数,没有返回值的归为子程序
7.1 扩充语法规则
函数定义语句的语法规则
此书将函数定义语句称为def语句。def语句仅能用于最外层代码,用户无法在代码块中定义函数
Stone语言将最后执行语句(表达式)的计算结果将作为函数的返回值返回
代码清单 7.1 与函数相关的语法规则
param : IDENTIFIER
params : param { "," param }
param_list : "(" [ params ] ")"
def : "def" IDENTIFIER param_list block
args : expr { "," expr }
postfix : "(" [ args ] ")"
primary : ( "(" expr ")" | NUMBER | IDENTIFIER | STRING ) { postfix }
simple : expr [ args ]
program : [ def | statement ] (";" | EOL)形参param是一种标识符(变量名)。形参序列params至少包含一个param,各个参数之间通过逗号分隔。
param_list可以是以括号括起的params,也可以是空括号对()。
函数定义语句def由def、标识符(函数名)、param_list及block组成。
实参args由若干个通过逗号分隔的expr组成。
postfix可以是以括号括起的args,也可以是省略了args的空括号对
非终结符primary需要在原有基础上增加对表达式中含有的函数调用的支持。因此,本章修改了代码清单5.1中primary的定义。在原先的primary之后增加若干个(可以为0)postfix(后缀)得到的依然是一个primary。这里的postfix是用括号括起的实参序列
此外,表达式语句simple也需要支持函数调用语句。因此,本章修改了之前的定义,使simple不仅能由expr组成,expr后接args的组合也是一种simple语句
与primary不同,simple不支持由括号括起的实参args。也就是说
simple : expr [ "(" [ args ] ")" ]是不正确的,应该使用下面的形式
simple : expr [ args ]代码清单7.2是根据代码清单7.1的语法规则设计的语法分析程序。其中FuncParser类继承于第5章代码清单5.2中的Basicparser类。也就是说,语法分析器的基本部分利用了Basicparser类中已有的代码,FuncParser类仅定义了新增的功能。和之前一样,新定义的非终结符也通过parser库实现。代码清单7.3、代码清单7.4与代码清单7.5是更新后的抽象语法树的节点类
代码清单7.2中,paramList字段与postfix字段的初始化表达式使用了maybe方法。
例如,paramList字段的定义如下所示
Parser paramList = rule().sep("(").maybe(params).sep(")");与option方法一样,maybe方法也用于向模式中添加可省略的非终结符。
paramList字段对应的非终结符param_list实际的语法规则如下所示
param_list : "(" [ params ] ")"省略params创建的子树是一棵以ParameterList对象为根节点的树。根节点是该子树唯一的节点,这棵子树除根节点外没有其他子节点。parameterList(参数列表)对象的子节点原本用于表示参数,params被省略时,根节点的子节点数为0,恰巧能够很好地表示没有参数
即使params被省略,抽象语法树仍将包含一个params的子树来表示这个实际不存在的成分。根据第5章介绍的特殊规定,为了避免创建不必要的节点,与params对应的子树将直接作为与非终结符param_list对应的子树使用
非终结符定义的修改由构造函数完成。构造函数首先需要为reserved添加右括号),以免将它识别为标识符。之后,primary与simple模式的末尾也要添加非终结符,为此需要根据相应的字段调用合适的方法。例如,simp1e字段应调用option方法
simple.option(args)通过这种方式,option方法将在由Basicparser类初始化的simple模式末尾添加一段新的模式。也就是说,BasicParser在进行初始化时,将不再执行下面的语句
Parser simple = rule(PrimaryExpr.class).ast(expr);而执行下面的代码
Parser simple = rule(PrimaryExpr.class).ast(expr).option(args)构造函数的最后一行调用了program字段的insertChoice方法,将用于表示def语句的非终结符def添加到了program中。该方法将把def作为or的分支选项,添加到与program对应的模式之前
通过insertChoice方法添加def之后,program表示的模式将与下面定义等价
Parser program = rule().or(def,statement,rule(NullStmnt.class)).sep(";",Token.EOL)算上def,表达式中or的分支选项增加到了3个。新增的选项和原有的两个一样,都是or方法的直接分支,语法分析器在执行语句时必须首先判断究竞选择哪个分支
代码清单7.2 支持函数功能的语法分析器FuncParser.java
package stone;
import static Stone.Parser.rule;
import stone.ast.ParameterList;
import stone.ast.Arguments;
import stone.ast.DefStmnt;
public class FuncParser extends BasicParser {
Parser param = rule().identifier(reserved);
Parser params = rule(ParameterList.class)
.ast(param).repeat(rule().sep(",").ast(param));
Parser paramList = rule().sep("(").maybe(params).sep(")");
Parser def = rule(DefStmnt.class)
.sep("def").identifier(reserved).ast(paramList).ast(block);
Parser args = rule(Arguments.class)
.ast(expr).repeat(rule().sep(",").ast(expr));
Parser postfix = rule().sep("(").maybe(args).sep(")");
public FuncParser() {
reserved.add(")");
primary.repeat(postfix);
simple.option(args);
program.insertChoice(def);
}
}代码清单7.3 ParameterList.java
package stone.ast;
import java.util.List;
public class ParameterList extends ASTList {
public ParameterList(List<ASTree> list) {
super(list);
}
public String name(int i) {
return ((ASTLeaf) child(i)).token().getText();
}
public int size() {
return numChildren();
}
}代码清单7.4 DefStmnt.java
package stone.ast;
import java.util.List;
public class DefStmnt extends ASTList {
public DefStmnt(List<ASTree> list) {
super(list);
}
public String name() {
return ((ASTLeaf) child(0)).token().getText();
}
public ParameterList parameters() {
return (ParameterList) child(1);
}
public BlockStmnt body() {
return (BlockStmnt) child(2);
}
public String toString() {
return "(def )" + name() + " " + parameters() + " " + body() + ")";
}
}代码清单7.5 Arguments.java
package stone.ast;
import java.util.List;
public class Arguments extends Postfix {
public Arguments(List<ASTree> c) {
super(c);
}
public int size() {
return numChildren();
}
}7.2 作用域与生存周期
环境是变量名与变量的值的对应关系表。大部分程序设计语言都支持仅在函数内部有效的局部变量。为了让Stone语言也支持局部变量,我们必须重新设计环境
设计环境
作用域(scope)
变量的作用域是指该变量能在程序中有效访问的范围。例如,Java语言中方法的参数只能在方法内部引用。也就是说,一个方法的参数的作用域限定于该方法内部。
生存周期(extent)
变量的生存周期则是该变量存在的时间期限。例如,Java语言中某个方法的参数p的生存周期就是该方法的执行期。换言之,参数p在方法执行过程中将始终有效。如果该方法中途调用了其他方法,就会离开原方法的作用域,新调用的方法无法引用原方法中的参数p。不过,虽然参数p此时无法引用,它仍会继续存在,保存当前值。当程序返回原来的方法后,又回到了参数p的作用域,将能够再次引用参数p。引用参数p得到的自然是它原来的值。方法执行结束后,参数p的生存周期也将一同结束,参数p不再有效,环境中保存的相应名值对也不复存在。事实上,环境也没有必要继续保持该名值对。之后如果程序再次调用该方法,参数p将与新的值(实参)关联
通常,变量的作用域由嵌套结构实现。Stone语言支持在整个程序中都有效的全局变量作用域及仅在函数内部有效的局部变量与函数参数作用域
为表现嵌套结构,我们需要为每一种作用域准备一个单独的环境,并根据需要嵌套环境。在查找变量时,程序将首先查找与最内层作用域对应的环境,如果没有找到,再接着向外逐层查找。目前的Stone语言尚不支持在函数内定义函数,因此仅有两种作用域,即全局变量作用域及局部变量作用域。而在支持函数内定义函数的语言中,可能存在多层环境嵌套
Java等一些语言中,大括号{}括起的代码块也具有独立的作用域。代码块中声明的变量只能在该代码块内部引用。Stone语言目前没有为代码块设计专门的作用域,之后也不会为每个代码块提供单独的作用域。因此,Stone语言将始终仅有两个作用域。
代码清单7.6 NestedEnv.java
package chap7;
import chap6.Environment;
import java.util.HashMap;
import chap7.FuncEvaluator.EnvEx;
public class NestedEnv implements Environment {
protected HashMap<String, Object> values;
protected Environment outer;
public NestedEnv() {
this(null);
}
public NestedEnv(Environment e) {
values = new HashMap<String, Object>();
outer = e;
}
public void setOuter(Environment e) {
outer = e;
}
public void put(String name, Object value) {
Environment e = where(name);
if (e == null)
e = this;
((EnvEx)e).putNew(name,value)
}
public void putNew(String name, Object value) {
values.put(name, value);
}
public Environment where(String name) {
if (values.get(name) != null)
return this;
else if (outer == null)
return null;
return ((EnvEx) outer).where(name);
}
public Object get(String name) {
Object v = values.get(name);
if (v == null && outer != null)
return outer.get(name);
return v;
}
}为了使环境支持嵌套结构,需要重新定义了Environment接口的类实现。代码清单7.6是今后需要使用的NestedEnv类的定义
与BasicEnv类不同,NestedEnv类除了value字段,还有一个outer字段。该字段引用的是与外侧一层作用域对应的环境。此外,get方法也需要做相应的修改,以便查找与外层作用域对应的环境。为确保put方法能够正确更新变量的值,我们也需要对它做修改。如果当前环境中不存在参数指定的变量名称,而外层作用域中含有该名称,put方法应当将值赋给外层作用域中的变量。为此,我们需要使用辅助方法where。该方法将查找包含指定变量名的环境并返回。如果所有环境中都不含该变量名,where方法将返回nul1
NestedEnv类提供了一个putNew方法。该方法的作用与BasicEnv类的put方法相同。它在赋值时不会考虑outer字段引用的外层作用域环境。无论外层作用域对应的环境中是否存在指定的变量名,只要当前环境中没有该变量,putNew方法就会新增一个变量。
此外,为了能让NestedEnv类的方法经由Environment接口访问,我们需要向Environment接口中添加一些新的方法。代码清单7.7定义的FuncEvaluator修改器定义了一个EnvEx修改器,它添加了这些新的方法。
7.3 执行函数
为了让解释器能够执行函数,必须为抽象语法树的节点类添加eva1方法。这由代码清单7.7的FuncEvaluator修改器实现。
函数的执行分为定义与调用两部分。程序在通过def语句定义函数时,将创建用于表示该函数的对象,向环境添加该函数的名称并与该对象关联。也就是说,程序会向环境添加一个变量,它以该对象为变量值,以函数名为变量名。函数由Function对象表示。代码清单7.8定义了Function类。
代码清单7.7的FuncEvaluator修改器包含多个子修改器。其中,DefstmntEX修改器用于向 Defstmnt类添加eva1方法。
PrimaryEx修改器将向PrimaryExpr类添加方法。函数调用表达式的抽象语法树与非终结符primary对应。非终结符primary原本只表示字面量与变量名等最基本的表达式成分,现在,我们修改它的定义,使函数调用表达式也能被判断为一种primary。即primary将涵盖由primary后接括号括起的实参序列构成的表达式,下图是一个例子,它是由函数调用语句fact(9)构成的抽象语法树。为了支持这一修改,我们需要为PrimaryExpr类添加若干新方法。
图 7.1 fact(9)的抽象语法树
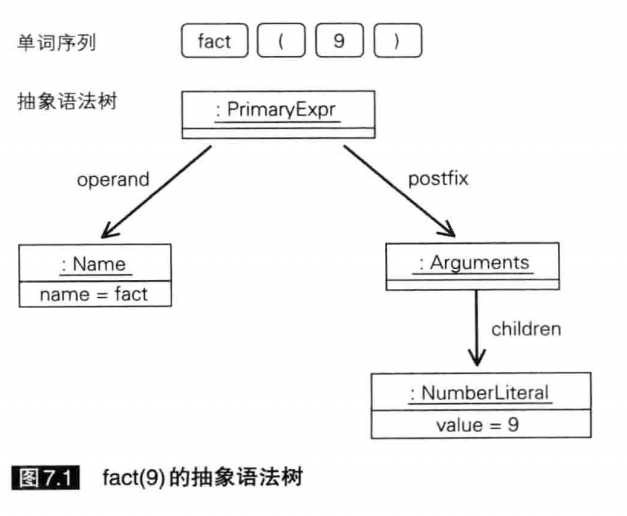
operand方法将返回非终结符primary原先表示的字面量与函数名等内容,或返回函数名称。postfix方法返回的是实参序列(若存在)。eval方法将首先调用operand方法返回的对象的eval方法。如果函数存在实参序列,eval方法将把他们作为参数,进一步调用postfix方法(在上图中即Arguments对象)返回的对象的eval方法
PrimaryExpr类新增的postfix方法的返回值为Postfix类型。Postfix是一个抽象类(代码清单7.9),它的子类Arguments类是一个用于表示实参序列的具体类。ArgumentsEx修改器为Arguments类添加的eva1方法将实现函数的执行功能
Arguments类新增的eval方法是函数调用功能的核心。它的第2个参数value是与函数名对应的抽象语法树的eval方法的调用结果。希望调用的函数的Function对象将作为value参数传递给eval方法。Function对象由def语句创建。函数名与变量名的处理方式相同,因此解释器仅需调用eval方法就能从环境中获取Function对象
之后,解释器将以环境callerEnv为实参计算函数的执行结果。首先,Function对象的parameters 方法将获得形参序列,实参序列则由自身提供iterator方法获取。然后解释器将根据实参的排列顺序依次调用eval并计算求值,将计算结果与相应的形参名成对添加至环境中。ParameterList类新增的eval方法将执行实际的处理
实参的值将被添加到新创建的用于执行函数调用的newEnv环境,而非callerEnv环境(表7.1)。newEnv环境表示的作用域为函数内部。如果函数使用了局部变量,它们将被添加到该环境
表7.1 函数调用过程中设计的环境
| environment | mean |
|---|---|
| newEnv | 调用函数时新创建的环境。用于记录函数的参数及函数内部使用的局部变量 |
| newEnv.outer | newEnv的outer字段引用的环境,能够表示函数外层作用域。该环境通常用于记录全局变量 |
| callerEnv | 函数调用语句所处的环境。用于计算实参 |
最后,Arguments类的eval方法将在新创建的环境中执行函数体。函数体可以通过调用Function对象的body方法获得。函数体是def语句中由大括号{}括起的部分,body方法将返回与之对应的抽象语法树。调用返回的对象的eva1方法即可执行该函数
用于调用函数的环境newEnv将在函数被调用时创建,在函数执行结束后舍弃。这与函数的参数及局部变量的生存周期相符。若解释器多次递归调用同一个函数,它将在每次调用时创建新的环境。只有这样才能正确执行函数的递归调用
有时,用于计算实参的环境callerEnv与执行def语句的是同一个环境,但也并非总是如此。callerEnv是用于计算调用了函数的表达式的环境。如果在最外层代码中调用函数,callerEnv环境将同时用于保存全局变量。然而,如果函数由其他函数调用,callerEnv环境则将保存调用该函数的外层函数的局部变量。环境虽然支持嵌套结构,但该结构仅反映了函数定义时的作用域嵌套情况。在函数调用其他函数时,新创建的环境不会出现在这样的嵌套结构中
代码清单7.7 FuncEvaluator.java
package chap7;
import java.util.List;
import javassist.gluonj.*;
import stone.StoneException;
import stone.ast.*;
import chap6.BasicEvaluator;
import chap6.Environment;
import chap6.BasicEvaluator.ASTreeEx;
import chap6.BasicEvaluator.BlockEx;
@Require(BasicEvaluator.class)
@Reviser public class FuncEvaluator {
@Reviser public static interface EnvEx extends Environment {
void putNew(String name, Object value);
Environment where(String name);
void setOuter(Environment e);
}
@Reviser public static class DefStmntEx extends DefStmnt {
public DefStmntEx(List<ASTree> c) { super(c); }
public Object eval(Environment env) {
((EnvEx)env).putNew(name(), new Function(parameters(), body(), env));
return name();
}
}
@Reviser public static class PrimaryEx extends PrimaryExpr {
public PrimaryEx(List<ASTree> c) { super(c); }
public ASTree operand() { return child(0); }
public Postfix postfix(int nest) {
return (Postfix)child(numChildren() - nest - 1);
}
public boolean hasPostfix(int nest) { return numChildren() - nest > 1; }
public Object eval(Environment env) {
return evalSubExpr(env, 0);
}
public Object evalSubExpr(Environment env, int nest) {
if (hasPostfix(nest)) {
Object target = evalSubExpr(env, nest + 1);
return ((PostfixEx)postfix(nest)).eval(env, target);
}
else
return ((ASTreeEx)operand()).eval(env);
}
}
@Reviser public static abstract class PostfixEx extends Postfix {
public PostfixEx(List<ASTree> c) { super(c); }
public abstract Object eval(Environment env, Object value);
}
@Reviser public static class ArgumentsEx extends Arguments {
public ArgumentsEx(List<ASTree> c) { super(c); }
public Object eval(Environment callerEnv, Object value) {
if (!(value instanceof Function))
throw new StoneException("bad function", this);
Function func = (Function)value;
ParameterList params = func.parameters();
if (size() != params.size())
throw new StoneException("bad number of arguments", this);
Environment newEnv = func.makeEnv();
int num = 0;
for (ASTree a: this)
((ParamsEx)params).eval(newEnv, num++,
((ASTreeEx)a).eval(callerEnv));
return ((BlockEx)func.body()).eval(newEnv);
}
}
@Reviser public static class ParamsEx extends ParameterList {
public ParamsEx(List<ASTree> c) { super(c); }
public void eval(Environment env, int index, Object value) {
((EnvEx)env).putNew(name(index), value);
}
}
}代码清单7.8 Function.java
package chap7;
import stone.ast.BlockStmnt;
import stone.ast.ParameterList;
import chap6.Environment;
public class Function {
protected ParameterList parameters;
protected BlockStmnt body;
protected Environment env;
public Function(ParameterList parameters,BlockStmnt body,Environment env) {
this.parameters = parameters;
this.body = body;
this.env = env;
}
public ParameterList parameters() {
return parameters;
}
public BlockStmnt body() {
return body;
}
public Environment makeEnv() {
return new NestedEnv(env);
}
public String toString() {
return "<fun:" + hashCode() + ">";
}
}代码清单7.9 Postfix.java
package stone.ast;
import java.util.List;
public class Postfix extends ASTList {
public Postfix(List<ASTree> list) {
super(list);
}
}7.4 计算斐波那契数
至此,Stone语言已支持函数调用功能。
代码清单7.10是解释器的程序代码,
代码清单7.11是解释器的启动程序。
解释器所处的环境并不是一个BasicEnv对象,而是一个由启动程序创建的NestedEnv对象
下面我们以计算斐波那契数为例测试一下函数调用功能。代码清单7.12是由Stone语言写成的斐波那契数计算程序。程序执行过程中,将首先定义fib函数,并计算fib(10)的值。最后输出如下结果
=> fib
=> 55代码清单7.10 FuncInterpreter.java
package chap6;
import stone.*;
import stone.ast.ASTree;
import stone.ast.NullStmnt;
public class BasicInterpreter {
public static void main(String[] args) throws ParseException {
run(new BasicParser(), new BasicEnv());
}
public static void run(BasicParser bp, Environment env)
throws ParseException
{
Lexer lexer = new Lexer(new CodeDialog());
while (lexer.peek(0) != Token.EOF) {
ASTree t = bp.parse(lexer);
if (!(t instanceof NullStmnt)) {
Object r = ((BasicEvaluator.ASTreeEx)t).eval(env);
System.out.println("=> " + r);
}
}
}
}代码清单7.11 FunRunner.java
package chap7;
import javassist.gluonj.util.Loader;
public class FuncRunner {
public static void main(String[] args) throws Throwable {
Loader.run(FuncInterpreter.class, args, FuncEvaluator.class);
}
}代码清单7.12 计算斐波那契数列的Stone语言程序
def fib(n) {
if n < 2 {
n
} else {
fib(n - 1) + fib(n - 2)
}
}
fib(10)7.5 为闭包提供支持
简单来讲,闭包是一种特殊的函数,它能被赋值给一个变量,作为参数传递至其他函数。闭包既能在最外层代码中定义,也能在其他函数中定义。通常,闭包没有名称
如果Stone语言支持闭包,下面的程序将能正确运行
inc = fun (x) { x + 1 }
inc(3)这段代码将创建一个新的函数,它的作用是返回一个比接收的参数大1的值。该参数将被赋值给变量inc。赋值给变量的就是一个闭包。inc并非函数的名称,事实上,这种函数没有名称。不过,程序能够通过inc(3)的形式,以3为参数调用该函数。读者可以将其理解为,程序从名为inc的变量中获得了一个闭包,并以3为参数调用这个闭包
代码清单7.13是闭包的语法规则。该规则修改了primary,向其中添加了闭包的定义
代码清单7.13 闭包的语法规则
primary : " fun " param_list block | 原本的primary定义7.6 实现闭包
代码清单7.14是支持闭包功能的语法分析器程序。它修改了非终结符primary的定义,使语法分析器能够解析由fun起始的闭包。代码清单7.15的Fun类是用于表示闭包的抽象语法树的节点类。
Fun类的eval方法通过代码清单7.16的ClosureEvaluator修改器增加。与def语句的eval方法一样,它也会创建一个Function对象。Function对象的构造函数需要接收一个env参数,它是定义了该闭包的表达式所处的执行环境。
def语句在创建Function对象后会向环境添加由该对象与函数名组成的键值对,而在创建闭包时,eval方法将直接返回该对象。这样一来,Stone语言就能将函数赋值给某个变量,或将它作为参数传递给另一个函数,实现闭包的语法功能。这时,实际赋值给变量或传递给函数的就是新创建的Function 对象。
代码7.14 支持必爆的语法分析器ClosureParser.java
package Stone;
import static Stone.Parser.rule;
import Stone.ast.Fun;
public class ClosureParser extends FuncParser {
public ClosureParser() {
primary.insertChoice(rule(Fun.class).sep("fun").ast(paramList).ast(block));
}
}代码清单7.15 Fun.java
package Stone.ast;
import java.util.List;
public class Fun extends ASTList {
public Fun(List<ASTree> c) {
super(c);
}
public ParameterList parameters() {
return (ParameterList)child(0);
}
public BlockStmnt body() {
return (BlockStmnt)child(1);
}
public String toString() {
return "(fun " + parameters() + " " + body() + ")";
}
}代码清单7.16 ClosureEvaluator.java
package chap7;
import java.util.List;
import stone.ast.ASTree;
import stone.ast.Fun;
import chap6.Environment;
import javassist.gluonj.*;
@Require(FuncEvaluator.class)
@Reviser public class ClosureEvaluator {
@Reviser public static class FunEx extends Fun {
public FunEx(List<ASTree> c) {
super(c);
}
public Object eval(Environment env) {
return new Function(parameters(),body(),env);
}
}
}代码清单7.17 ClosureInterpreter.java
package chap7;
import stone.ClosureParser;
import stone.ParseException;
import chap6.BasicInterpreter;
public class ClosureInterpreter extends BasicInterpreter {
public static void main(String[] args) throws ParseException {
run(new ClosureParser(),new NestedEnv());
}
}从具体实现的角度来看,整数值有Java语言的Integer对象表现,字符串由String对象表现,而新添加的函数则由Function对象表现。
代码清单7.17是支持闭包功能的Stone语言解释器。代码清单7.18是相应的启动程序
代码清单7.18 ClosureRunner.java
package chap7;
import javassist.gluonj.util.Loader;
public class ClosureRunner {
public static void main(String[] args) throws Throwable {
Loader.run(ClosureInterpreter.class, args, ClosureEvaluator.class);
}
}虽然现在程序已经支持函数何闭包了,Stone语言和其他很多变量无需声明即可使用的语言一样,但如果已经存在某个全局变量,就是无法在创建同名变量,比方说下面的例子
x = 1
def foo (i) {
x = i;
x + 1
}函数foo无法创建名为x的局部变量。函数中的x将引用第一行的全局变量x。如果调用foo(3),全局变量x的值就会是3,这可就麻烦了。想用的是局部变量,实际使用的是全局变量,这里似乎存在大量错误隐患。如果非要区分两者,只要更改定义,让全局变量的变量名必须以$开始就行了
以上是关于两周自制脚本语言-第7天 添加函数功能的主要内容,如果未能解决你的问题,请参考以下文章