正则表达式
Posted goldsunshine
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了正则表达式相关的知识,希望对你有一定的参考价值。
定义:
正则表达式,又称规则表达式,通常被用来检索、替换那些符合某个模式(规则)的文本。
正则表达式是对字符串操作的一种逻辑公式,就是用事先定义好的一些特定字符、及这些特定字符的组合,组成一个"规则字符串",这个"规则字符串"用来表达对字符串的一种过滤逻辑。
功能:
给定一个正则表达式和另一个字符串,我们可以达到如下的目的:
- 匹配 给定的字符串是否符合正则表达式的过滤逻辑
- 过滤 通过正则表达式,从文本字符串中获取我们想要的特定部分
原理:
单字符匹配
1.最简单匹配:匹配指定字符
所有的字符都可以匹配自身如 abc 能够匹配 abc
import re string = ‘1233abc384‘ pattern = re.compile(‘abc‘) result = pattern.search(string) result >>> result <_sre.SRE_Match object at 0x7fbec85a2578> >>> result.group() ‘abc‘
2. . 匹配换行‘ ‘之外所有字符
import re string = ‘12attc3334axc‘ #将正则表达式编译成对象 pattern = re.compile(‘a.c‘) #使用正则表达式对象匹配字符串 result = pattern.search(string) #查看结果 >>> result <_sre.SRE_Match object at 0x7fbec85a2578> >>> result.group() ‘axc‘
在这个例子中,字符串中看似符合标准的有两个:attc,axc,因为.代表一切字符,所有能够匹配a[]c,又因为.只代表数量上匹配一位,所以只能匹配axc
3.给定范围匹配
使用[],在里面写入需要匹配的字符,作用是在字符串中匹配写入的字符,能够匹配任意一个即可
import re string = ‘12agc3334axc‘ pattern = re.compile(‘a[gx]c‘) result = pattern.findall(string) >>> result [‘agc‘, ‘axc‘]
a[gx]c可以匹配以a开头c结尾,中间一位是g或者x的字符串。在string中有两位,agc和axc,使用findall可以将符合条件的都查找出来。
4.匹配特殊字符
在2中使用.可以匹配除
外所有的字符串,但如果想要匹配.本身呢?如匹配一个qq号12345@qq.com,youdao@163.com,找到是哪一家公司的。可以让特殊符号变成原来的意思。
import re string = ‘12agc3334a.c‘ pattern = re.compile(‘a.c‘) result = pattern.findall(string) >>> result [‘a.c‘]
通配符匹配
字符的类型有很多,字符,数字,点,空格,tab等。对类型复杂的字符,正则表达式提供了多种匹配方式。
d 能够匹配0-9的数字
import re string = ‘12agc3334a.c‘ pattern = re.compile(‘d‘) result = pattern.findall(string) >>> result [‘1‘, ‘2‘, ‘3‘, ‘3‘, ‘3‘, ‘4‘]
可以使用pattern = re.compile([ y
fv])替换。
还有一些方便的匹配字符集,所有的字符集都可以使用[]这种方式实现
D 匹配非数字 [^d] S 匹配非空白字符 [^s] w 匹配单词字符 [A-Za-z0-9_] W 匹配非单词字符 [^w]
多字符匹配
前面所有的匹配都是只能匹配一个字符,往往在工作中需要配多个字符。如23gbhtrev56匹配23和56之间所有的字符。这时不知道是一个字符还是多个字符。所以需要使用数量上的匹配来实现。
0~无限次
*表示匹配无限个字符,包括0个。使用方式:a*代表a可以匹配0-无限次
string=‘23gbhtrev56‘ pattern = re.compile(‘23.*56‘) result = pattern.search(string) result >>> result <_sre.SRE_Match object at 0x7fbec85a2578> >>> result.group() ‘23gbhtrev56‘
.代表所有字符,.*表示匹配所有字符0~无数次
1~无限次
+和*用法相似,唯一不同的是+能够1~无数次,即一定要有一次出现。
string1 = ‘abcd‘ strinng2 = ‘ab12345cd‘ pattern = re.compile(‘ab.+cd‘) >>> one = pattern.search(string1) >>> >>> one >>> two = pattern.search(string2) >>> >>> two.group() ‘ab12345cd‘
string1中ab和cd之间没有数字,所以没有匹配到,而string2中ab和cd之间有12345,所有能够匹配到。这就是+的能力。如果使用*则可以都匹配到。
指定次数
除了匹配无数次这种不确定的次数外,也可以使用{m}匹配指定次数。使用{m}可以匹配一个字符m次。如a{4}这个意思就是匹配字符4次,只有类似xaaaa3244这种出现4次a的字符串才会被匹配到。
同样使用{m,n}可以匹配 小于n次,大于m次的字符。
边界匹配
边界匹配简化了一些匹配表达的填写,这些都可以使用基础表达式完成。
1.匹配以XXX字符开头的字符串
使用^abc可以匹配以abc开头的字符串
string1 = ‘abc098tr‘ >>> >>> string2 = ‘3455vf‘ pattern = re.compile(‘^abc(.*)‘) one = pattern.search(string1) >>> one <_sre.SRE_Match object at 0x7f570da75648> >>> one.group() ‘abc098tr‘ >>> two = pattern.search(string2) >>> two
匹配以xxx字符结尾的字符串
使用$xyz可以匹配以xyz结尾的字符串
匹配以字符串开头
匹配以字符串结尾
逻辑,分组
|代表左右表达式任意匹配一个,先尝试匹配左边的表达式,一旦成功则跳过匹配右边的表达式。如abc|xyz
在使用|时最好用括号包裹匹配条件(abc|xyz),如果 没有包裹它的匹配范围是整个正则表达式。
小场景:匹配出邮箱的公司名在不在qq,163和gmail之间。
邮箱的公司名都要跟在@符号后面
import re pattern = re.compile(‘@(163|qq|gmail)‘) sting1 = ‘123456@qq.com‘ sting2 = ‘youdao@163.com‘ sting3 = ‘huawei@gmail.com‘ one = pattern.search(sting1) >>> one.group() ‘@qq‘ >>> two = pattern.search(sting2) >>> two.group() ‘@163‘ >>> three = pattern.search(sting3) >>> three.group() ‘@gmail‘
匹配范围规则
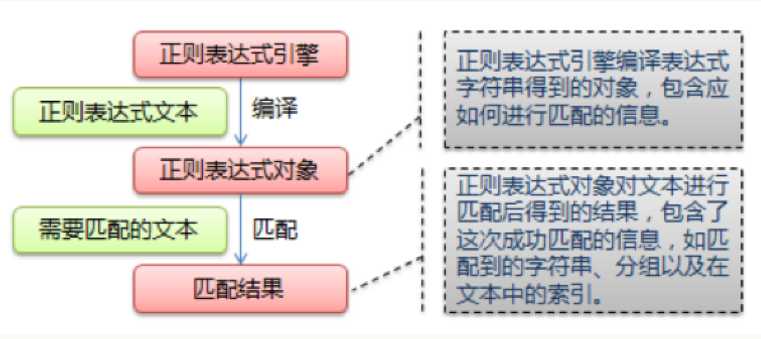
re模块的一般使用步骤如下:
1.使用compile()函数将正则表达式的字符串形式编译为一个Pattern对象
2.通过Pattern对象提供的一系列方法对文本进行匹配查找,获得匹配结果,一个Match对象。
3.最后使用Match 对象提供的属性和方法获得信息,根据需要进行其他的操作
compile 函数
compile 函数用于编译正则表达式,生成一个 Pattern 对象,它的一般使用形式如下:
import re # 将正则表达式编译成 Pattern 对象 pattern = re.compile(r‘d+‘)
在上面,我们已将一个正则表达式编译成Pattern对象,接下来,我们就可以利用pattern的一系列方法对文本进行匹配查找了。
Pattern 对象的一些常用方法主要有:
- match 方法:从起始位置开始查找,一次匹配
- search 方法:从任何位置开始查找,一次匹配
- findall 方法:全部匹配,返回列表
- finditer 方法:全部匹配,返回迭代器
- split 方法:分割字符串,返回列表
- sub 方法:替换
match方法
match 方法用于查找字符串的头部(也可以指定起始位置),它是一次匹配,只要找到了一个匹配的结果就返回,而不是查找所有匹配的结果。
import re pattern = re.compile(r‘d+‘) # 用于匹配至少一个数字 match = pattern.match(‘12twothree34four‘) # 查找头部,匹配
在上面,当匹配成功时返回一个Match对象,其中:
-
group() 方法用于获得一个或多个分组匹配的字符串,当要获得整个匹配的子串时,可直接使用 group() 或 group(0);
-
start() 方法用于获取分组匹配的子串在整个字符串中的起始位置(子串第一个字符的索引),参数默认值为 0;
-
end() 方法用于获取分组匹配的子串在整个字符串中的结束位置(子串最后一个字符的索引+1),参数默认值为 0;
-
span() 方法返回 (start(group), end(group))。
search方法
search 方法用于查找字符串的任何位置,它也是一次匹配,只要找到了一个匹配的结果就返回,而不是查找所有匹配的结果。
findall 方法
上面的 match 和 search 方法都是一次匹配,只要找到了一个匹配的结果就返回。然而,在大多数时候,我们需要搜索整个字符串,获得所有匹配的结果。
findall 以列表形式返回全部能匹配的子串,如果没有匹配,则返回一个空列表。
import re pattern = re.compile(r‘d+‘) # 查找数字 result1 = pattern.findall(‘hello 123456 789‘) result2 = pattern.findall(‘one1two2three3four4‘, 0, 10) print (result1) [‘123456‘, ‘789‘] print (result2) [‘1‘, ‘2‘]
sub 方法
sub 方法用于替换。它的使用形式如下:
sub(repl, string[, count])
使用repl替换string中匹配到的字符
小场景:将字符串中所有数字替换成*号
import re pattern = re.compile(‘d‘) string = ‘abc123def456hij78xyz‘ match = pattern.sub(‘*‘,string) >>> match ‘abc***def***hij**xyz‘
贪婪模式与非贪婪模式
- 贪婪模式:在整个表达式匹配成功的前提下,尽可能多的匹配 ( * );
- 非贪婪模式:在整个表达式匹配成功的前提下,尽可能少的匹配 ( ? );
- Python里数量词默认是贪婪的。
示例一 : 源字符串:abbbc
-
使用贪婪的数量词的正则表达式
ab*,匹配结果:abbb。
决定了尽可能多匹配 b,所以a后面所有的 b 都出现了。 -
使用非贪婪的数量词的正则表达式
ab*?,匹配结果:a。
即使前面有 *,但是 ? 决定了尽可能少匹配 b,所以没有 b。
示例二 : 源字符串:aa<div>test1</div>bb<div>test2</div>cc
使用贪婪的数量词的正则表达式:<div>.*</div>
匹配结果:<div>test1</div>bb<div>test2</div>
这里采用的是贪婪模式。在匹配到第一个""时已经可以使整个表达式匹配成功,但是由于采用的是贪婪模式,所以仍然要向右尝试匹配,查看是否还有更长的可以成功匹配的子串。匹配到第二个""后,向右再没有可以成功匹配的子串,匹配结束,匹配结果为<div>test1</div>bb<div>test2</div>
使用非贪婪的数量词的正则表达式:<div>.*?</div>
匹配结果:<div>test1</div>
正则表达式二采用的是非贪婪模式,在匹配到第一个""时使整个表达式匹配成功,由于采用的是非贪婪模式,所以结束匹配,不再向右尝试,匹配结果为<div>test1</div>。
非贪婪模式在匹配html结构化数据时非常有效,可以将最小html结构匹配出来
爬取网站,并使用正则匹配完成html解析
#coding:utf-8 import urllib.request import os import re user_agent = ‘Mozilla/4.0 (compatible; MSIE 5.5; Windows NT)‘ headers = { ‘User-Agent‘ : user_agent } url = ‘https://baijiahao.baidu.com/s?id=1653631010620369314&wfr=spider&for=pc‘ req = urllib.request.Request(url,headers=headers) response = urllib.request.urlopen(req) the_page = response.read().decode() pattern = re.compile(r‘<p>(.*?)</p>‘,re.S) t = pattern.findall(the_page) # pattern_two = re.compile(r‘<span class="bjh-strong">.*</span>‘) # t_two = pattern_two.findall() file = open(‘baidu.txt‘,‘w+‘) for x in t[0:7]: print(‘-------------------‘) # print(x) pattern_two = re.compile(r‘<span class="bjh-p">(.*)</span>‘) t_two = pattern_two.findall(x) print(t_two) pattern_three = re.compile(r‘<span class="bjh-strong">(.*?)</span>‘,re.S) t_three = pattern_three.sub(‘ ‘,t_two[0]) pattern_four = re.compile(r‘<span class="bjh-br">(.*?)</span>‘,re.S) t_four = pattern_four.sub(‘ ‘,t_three) print(t_four) file.write(t_four+‘ ‘) # print(‘-----------------------two‘) # print(len(t)) # print(t)
最后写入到文本中的内容
老婆躺我怀里问:你要是有100亿,你想做的第一件事是什么?我脱口而出:把你休了。(当时没过脑,说完感觉要坏事)老婆微怒:那第二件事呢?“把你娶回来”“为什么?”“以前娶你时办得太简单,所以要再办一次,让你嫁的风光点。”老婆一脸感动。当时,我对自己说:我真是太机智了!
今天同学问我:为什么冬天那么冷,女的要上装穿棉袄,下穿丝袜呢?这时旁边那位来了一句:鲜奶要保温,火腿要冷藏……
去超市购物,一位美丽的少妇突然跟我打招呼。我很是吃惊,因为我想不起在哪里见过她了。
于是我问:“请问我认识你吗?”少妇回答:“我觉得我有个孩子的父亲是你。”
我顿时五雷轰顶,想起了自己一生中唯一一次对妻子不忠的那一刻,连忙否认道:不可能的,我当时明明采取了安全措施!
少妇疑惑地说:什么意思?我是想跟你谈谈你儿子的作业。原来她是我儿子的班主任老师。
高中时喜欢一个女孩,却没勇气表白,所以我决定每天写一篇日记,笔记本写完之时就是我表白之日!有一天,我正写着日记,她却突然向我走来,拿起我的日记本看了一眼,然后把后面空白的纸全都撕了!那一刻,我就静静地看着她,仿佛做梦一般,就在我站起来准备大声表白时她却捂着肚子跑去了厕所!
以上是关于正则表达式的主要内容,如果未能解决你的问题,请参考以下文章