AutoAugment
Posted mercuialc
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了AutoAugment相关的知识,希望对你有一定的参考价值。
AutoAugment : Learning Augmentation Strategies from Data
Summary
- 区别与传统数据增强方法。本文提出了一种自动化搜索优化的数据增强策略的方法 AutoAugment
- 实际应用中直接应用于兴趣数据集耗费太大,一般尝试迁移其他数据集的数据增强策略
- 精简ImageNet上学习到的数据增强策略迁移到FGVC的数据集上提升非常显著(可以迁移该增强策略到车辆细粒度分类上)
- AutoAugment学习到的策略在不同的数据集上迁移几乎不会损害模型性能
- 个人认为在相似类型的图片上学习的增强策略迁移后提升效果更加显著。(像论文中所述:CIFAR—10上学习到的策略迁移到SVHN上的精度提升效果没有那么明显)
Research Objective
- 寻找一种对任何数据集均可用的自动化数据增强策略(图像变换操作的选择和顺序)
本文将自动化搜索优化的数据增强策略形式化为离散搜索问题
Problem Statement
- 传统的数据增强的方法往往是针对特定数据集设计的最佳增强策略,本文提出一种数据增强策略原则上对于任何数据集都可以使用,而非针对特定数据集
FGVC的数据集一般都是具有。相对较少的训练样本,同时具有大量的类。
Method(s)
- 对于FGVC的数据集可以通过数据增强技术减少网络的过拟合现象,通过对训练图片进行变换可以得到泛化能力更强的网络,更好的适应应用场景。
- 本文提出了一种自动化数据增强方法,由两部分组成:
- 搜索算法
- 搜索空间
- 本文给出了一种强化学习的搜索算法(!搜索算法可以替换):
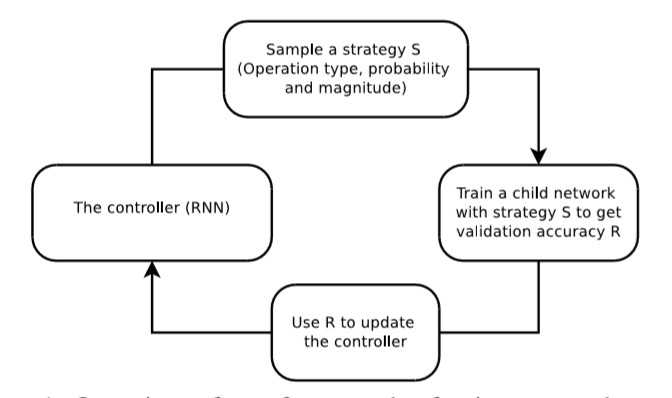
- 实现一个控制器RNN(单层的LSTM)对一个数据增强策略进行采样,具体包括:
- 用哪些图像处理操作
- 每个批处理使用该操作的概率
- 该操作的大小
- 控制器有30个softmax决策(5个子策略,每个子策略2个图像操作,每个操作上述三种属性)
- 数据增强策略S用于训练固定结构的神经网络(子网络),验证精度R发送回用以更新控制器,由于R不可微,更新使用策略梯度法PPO(Proximal Policy Optimization)
- 实现一个控制器RNN(单层的LSTM)对一个数据增强策略进行采样,具体包括:
- 搜索空间
- 一个策略包含五个子策略,每个子策略包含两个图像操作(16种),每个图像操作均包含两个超参数:1.概率2.大小
- 每个策略中的图像操作按照特定顺序

- 强调变换的随机性,一张图片在不同的mini-batches可以被不同的变换,即使使用相同的子策略
- 搜索空间大小(如:16个图像操作,10:大小范围,11:概率范围,5个子策略,每个子策略2个图像操作):
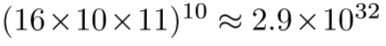
Evaluation
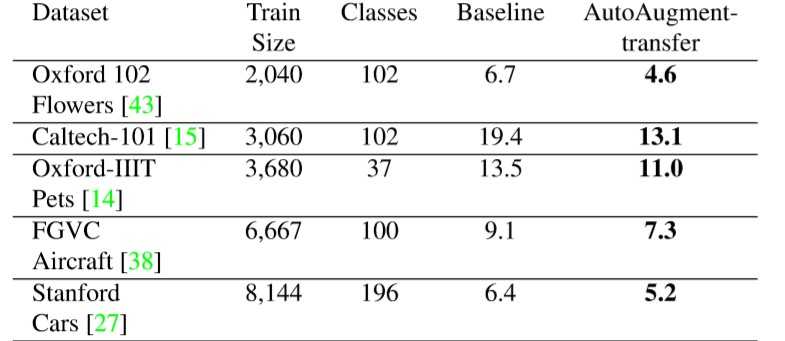
作者在多个FGVC的数据集上进行评估,使用Top-1 错误率进行度量评估,使用Inception v4训练1000个epochs
(使用AutoAugment在ImageNet数据集上得到的增强策略)
Conclusion
- AA可直接应用于兴趣数据集
- AA学习到的策略可以转移到新的数据集(为迁移学习提供一种新的方法)
- 在简化数据集上获得比完整数据集更大的性能改进(性能提升效果随训练集的规模增大,可能降低),同时在不使用任何标注时,达到了与半监督相当的性能。
AA在ImageNet上获得增强策略耗费了15000个gpu hours,显然耗费太大,使用时可以迁移AA在ImageNet上获得的增强策略到FGVC数据集上,效果提升明显(排名第2)
Notes
相似论文:ICML 2019的一篇新论文 基于种群的数据增强算法,降低计算成本的情况下,既能提高学习数据增强策略的速度,又能提升模型整体性能。
以上是关于AutoAugment的主要内容,如果未能解决你的问题,请参考以下文章