JVM垃圾回收与一次线上内存泄露问题分析和解决过程
Posted long2050
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了JVM垃圾回收与一次线上内存泄露问题分析和解决过程相关的知识,希望对你有一定的参考价值。
内存泄漏(Memory Leak)是指程序中己动态分配的堆内存由于某种原因程序未释放或无法释放,造成系统内存的浪费,导致程序运行速度减慢甚至系统崩溃等严重后果。
Java是由C++发展来的,抛弃了C++中一些繁琐容易出错的东西,程序员忘记或者错误的内存回收会导致程序或系统的不稳定甚至崩溃,而Java的GC(Garbage Collection)是自动检测不用的对象,达到自动回收,
既然是自动检测回收不用对象,那Java有没有可能出现内存泄露的情况呢?
一、JVM判断垃圾对象方法
Java又是如何知道哪些对象不再使用,需要回收的呢?实际上JVM中对堆内存进行回收时有一套可达性分析算法,该算法的思路就是通过被称为引用链(GC Roots)的对象作为起点,搜索所走过的路径称为引用链(Reference Chain),当一个对象到GC Roots没有任何引用链相连时,则证明此对象是不可用的,最终不可用的对象会被回收。
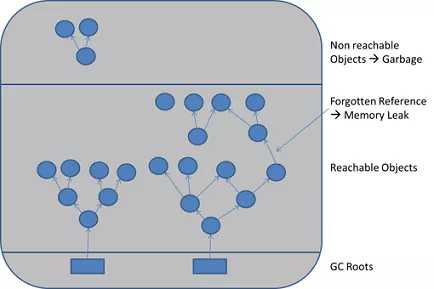
GC Roots对象可归纳为如下几种:
虚拟机栈(栈帧中的本地变量表)中引用的对象;
方法区中类静态属性引用的对象;
方法区中常量引用的对象;
本地方法栈中JNI(即一般说的Native方法)引用的对象;
了解了基本JVM如何判断垃圾对象原则后有助于理解java如何发生内存泄露,由于篇幅有限这里就不对jvm内存空间划分和垃圾回收算法详细的叙述了。
二、 根据现象分析并定位问题
先说说事情的现象吧,本来运行好好的活动项目某一天突然服务报警(当时没有任何上线),客服陆续收到几个用户反馈投诉,查看日志发现有一台服务器各种报超时异常、cpu负载高,服务重启后一切正常,再过一天又是超时异常、cpu负载高。
乍一看现象还有点摸不着头脑,但有前面的内容聪明的你肯定猜到了什么原因,如果没有上述铺垫,我们根据该现象定位问题呢?
我们一般发现问题,都是从现象到本质,逐步递进的,如何从现象中提取有用信息加工并做判断很重要。
1.异常特征分析
特征一、报错范围:看到的是大量业务日志异常,大量操作超时和执行慢,redis超时、数据库执行超时、调用http接口超时
分析:首先排除是某一个db的问题
1.网络问题,ping服务器是通的,无丢包,查看wonder监控后台网络无丢包、网卡无故障 --排除网络问题
2.服务器cpu问题,top命令发现java应用cpu异常高,查看wonder监控后台也发现cpu负载高--这里并不是根本原因,只是现象
特征二、报错普遍性:查看其它服务器是否有相同异常,相同的代码,相同的jvm配置,只有一台服务器有问题,其它服务器正常
分析:跟这一台服务器代码或者系统设置有关系
1.操作系统设置导致 --这台服务器是虚拟机,跟其他虚拟机比较,参数配置一样,排除操作系统设置(当时上来先入为主,就认为是虚拟机配置不一样导致cpu过高,走了弯路)
2.负载均衡流量不均导致 --查看wonder监控后台流量无明显高,可以排除该原因
3.该机器运行与其它机器不一样的业务 --当时认为代码都一样的,忽略了定时任务
特征三、持续性:查看日志,开始报错后持续不断报错,cpu使用率持续高
分析:不是偶发状况
2.查看数据指标
ps: 这里简单说一下我们的业务监控后台,对诊断问题起很大的作用,可以看到cpu、线程、jvm内存等曲线图
使用的是springboot actuator报点 + prometheus收集 + grafana图形展示
springboot 只需要加上这两个包,加上一个配置就行了,零侵入,prometheus定时每10秒一次请求http接口收集数据,也不会对业务产生影响
1. 基于springboot的业务报点gradle配置:
compile ‘org.springframework.boot:spring-boot-starter-actuator‘compile ‘io.micrometer:micrometer-registry-prometheus‘
yml配置文件加上:
management:endpoints:web:exposure:include: health,prometheus默认报点的url:http://ip:port/actuator/prometheus
2. 安装prometheus并配置对应的ip和收集的url
3. 安装grafana,并去grafana官网 dashboards中下载一个叫“Spring Boot 2.1 Statistics”的模板,导入就能看到漂亮的统计界面了
grafana监控后台
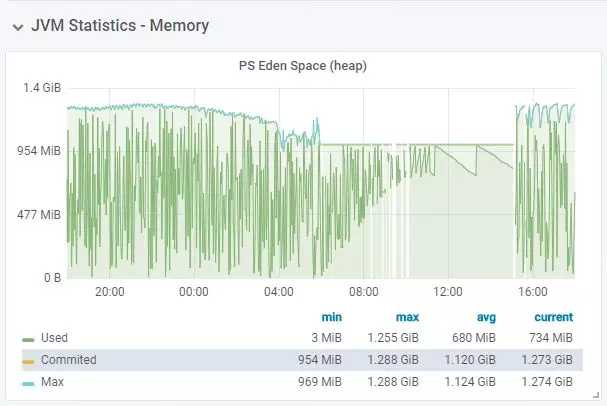
内存泄露-年轻代的eden区的特征:
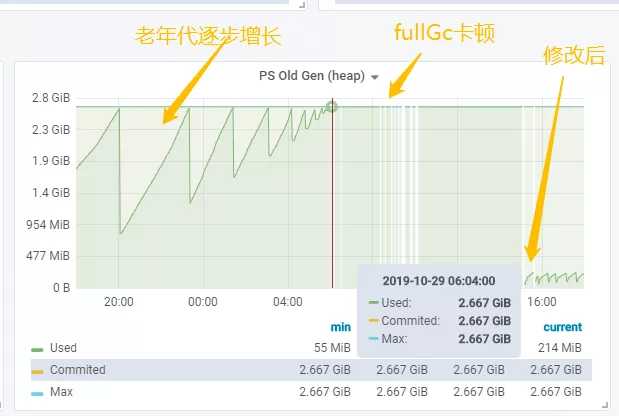
内存泄露-老年代的特征:
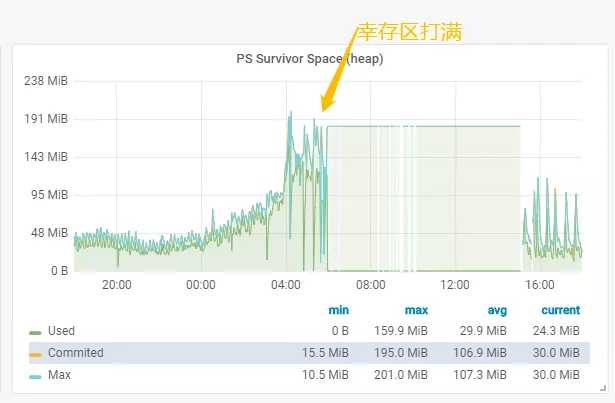
内存泄露-年轻代的survivor区的特征:
内存泄露-gc Stop The World 曲线图:
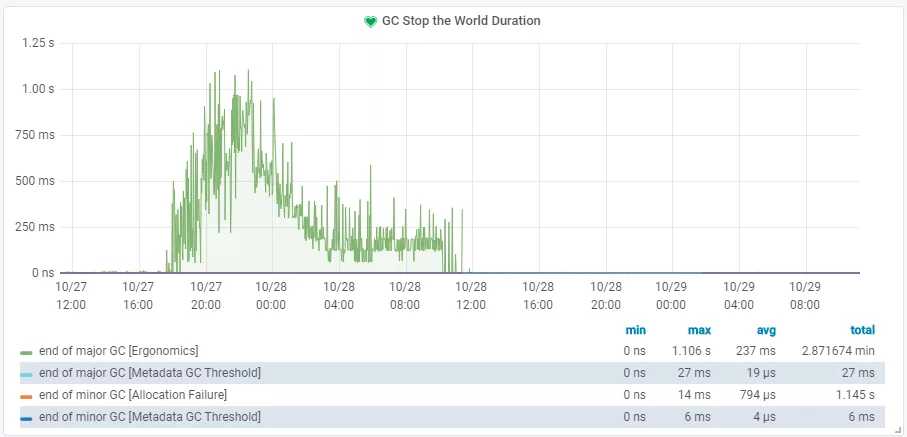
有这个图基本就可以断定为内存泄露,
3.如何定位问题代码
1、查询pid
ps -ef|grep projectName2、dump当前jvm堆内存(注意:要先切换到启动java应用的用户,并且切走流量,因为dump内存会卡住进程)
jmap -dump:live,format=b,file=dump.hprof <pid>3、下载内存分析工具mat (Memory Analyzer Tool)(https://www.eclipse.org/mat/downloads.php),并分析,由于dump下来的内存比较大,建议选择linux版本,直接在linux上分析
//解压
unzip -o MemoryAnalyzer-1.9.1.20190826-linux.gtk.x86_64.zipcd mat
//执行分析命令
./ParseHeapDump.sh <dump文件> org.eclipse.mat.api:suspects org.eclipse.mat.api:overview org.eclipse.mat.api:top_components最后会生成三个zip文件和一堆index索引文件,下载zip文件到本地,重点看这个文件xxx_Leak_Suspects.zip
打开后看到分析图:
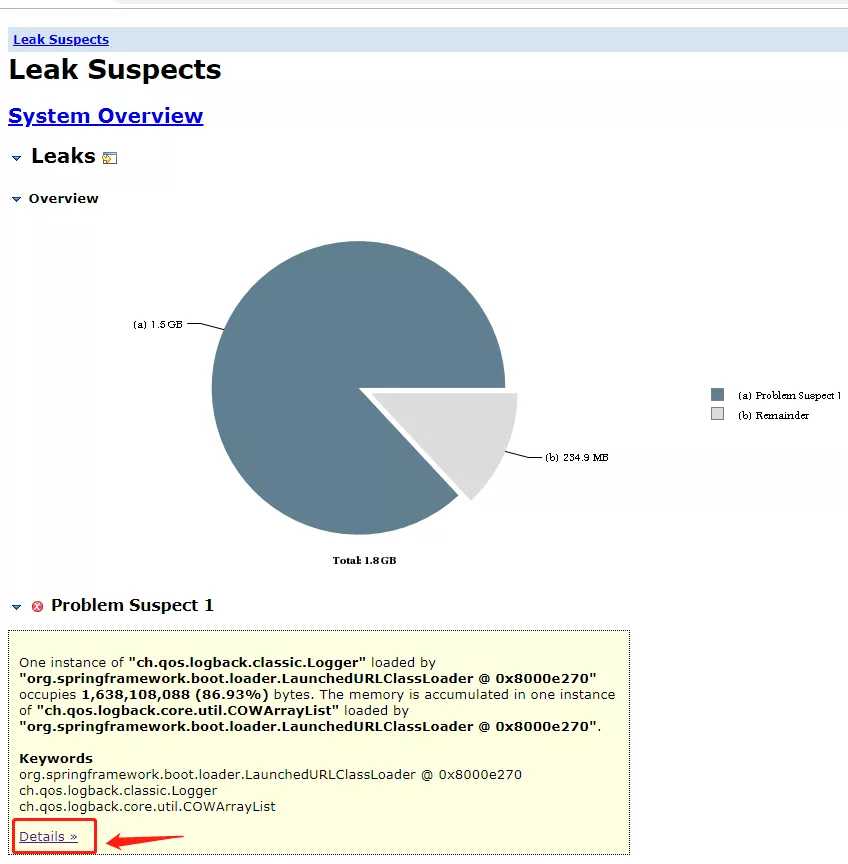
分析结果告诉你哪些类有问题:
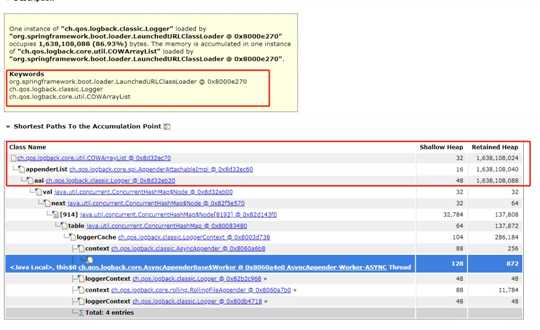
class关系链--ch.qos.logback.core.spi.AppenderAttachableImpl----ch.qos.logback.classic.Logger------org.slf4j.LoggerFactory--------ch.qos.logback.classic.LoggerContext----------org.slf4j.impl.StaticLoggerBinder
我们知道jvm垃圾回收是不会回收gc root对象,StaticLoggerBinder(源码在底部)是单例对象(方法区中的类静态属性引用对象属于gc root对象),与AppenderAttachableImpl有如上图的关系链,而每一次请求都会new ListAppender(),放入到COWArrayList中,COWArrayList中的对象不断增长,直到老年代满,频繁fullGc导致 Stop The World 执行卡顿,cpu负载居高不下。
最终找到有问题的代码,是新加入没多久的公共分布式cron包(由于cron只会在一台服务器运行,所以只有一台服务器内存泄露):
//com.huajiao.common.cron.service.CronServerService中的业务代码//构造loggerLogger logger = org.slf4j.LoggerFactory.getLogger(cronBean.getClass());//这里为了临时储存日志信息ListAppender<ILoggingEvent> listAppender = new ListAppender<>();((ch.qos.logback.classic.Logger)logger).addAppender(listAppender);listAppender.start();
//ch.qos.logback.classic.Logger中的代码public final class Logger implements org.slf4j.Logger ,... {...transient private AppenderAttachableImpl<ILoggingEvent> aai;public synchronized void addAppender(Appender<ILoggingEvent> newAppender) {if (aai == null) {aai = new AppenderAttachableImpl<ILoggingEvent>();}aai.addAppender(newAppender);}}
//ch.qos.logback.core.spi.AppenderAttachableImpl中的代码public class AppenderAttachableImpl<E> implements AppenderAttachable<E> {final private COWArrayList<Appender<E>> appenderList = new COWArrayList<Appender<E>>(new Appender[0]);/*** Attach an appender. If the appender is already in the list in won‘t be* added again.*/public void addAppender(Appender<E> newAppender) {if (newAppender == null) {throw new IllegalArgumentException("Null argument disallowed");}appenderList.addIfAbsent(newAppender);}...}
//org.slf4j.impl.StaticLoggerBinder中的关键代码public class StaticLoggerBinder implements LoggerFactoryBinder {//...省略部分代码private static StaticLoggerBinder SINGLETON = new StaticLoggerBinder();static {SINGLETON.init();}private boolean initialized = false;private LoggerContext defaultLoggerContext = new LoggerContext();public static StaticLoggerBinder getSingleton() {return SINGLETON;}void init() {try {try {new ContextInitializer(defaultLoggerContext).autoConfig();} catch (JoranException je) {Util.report("Failed to auto configure default logger context", je);}....省略部分代码initialized = true;} catch (Exception t) { // see LOGBACK-1159Util.report("Failed to instantiate [" + LoggerContext.class.getName() + "]", t);}}public ILoggerFactory getLoggerFactory() {if (!initialized) {return defaultLoggerContext;}if (contextSelectorBinder.getContextSelector() == null) {throw new IllegalStateException("contextSelector cannot be null. See also " + NULL_CS_URL);}return contextSelectorBinder.getContextSelector().getLoggerContext();}
修改解决:在finally中删除ListAppender对象
//构造loggerLogger logger = org.slf4j.LoggerFactory.getLogger(cronBean.getClass());//这里为了临时储存日志信息ListAppender<ILoggingEvent> listAppender = new ListAppender<>();((ch.qos.logback.classic.Logger)logger).addAppender(listAppender);listAppender.start();try {....//此处省略部分业务代码}
finally {//删除
((ch.qos.logback.classic.Logger) logger).detachAppender(listAppender);
MDC.remove("tid");}
三、总结
1. 我们经常会听到GC调优,实际不管什么垃圾回收器和回收算法,首先得理解垃圾回收原理,然后保证写出的代码没有问题,不然换垃圾回收器和算法都无法阻止内存溢出问题,加jvm大内存也只不过延迟出现问题时间;
2. 擅于借助工具的使用,如果没有grafana监控后台、hulk的监控wonder后台、java自带工具、mat分析工具很难快速解决问题,在这里还推荐一个阿里的jvm监控工具Arthas,也是一个不错的选择
3. 查看数据指标作为依据,不能凭空猜测和先入为主(由于当时先入为主,认为是服务器系统的问题而走了弯路,导致解决问题的时间延长),定位问题,还必须要知道java常见的问题和对应的数据指标现象,综合分析便能迅速找到原因。
例如:
内存泄露:应用占用cpu高,运行一段时间,频繁fullGC,但不马上抛内存溢出;
死锁:应用占用cpu高,gc无明显异常,jstack 命令可以发现deadlock
OOM: 这个看日志就能看出来,线程过多unable to create Thread,堆溢出:java heap space
某线程占用cpu高: 通过top命令查找java线程占用cpu最高的, jstack命令分析线程栈信息
后话
是否有开源的内存泄露静态分析工具呢?但遗憾的是经调查几个知名的静态代码分析工具findbugs 、SonarQube、Checkstyle等都不能实现内存泄露检测,只能对编码规范和部分潜在的bug提前报告,相信将来会有更好的检测手段对内存泄露防范于未然。
参考链接:
https://www.dynatrace.com/resources/ebooks/javabook/how-garbage-collection-works/
以上是关于JVM垃圾回收与一次线上内存泄露问题分析和解决过程的主要内容,如果未能解决你的问题,请参考以下文章