kafka-为什么选择kafka
Posted qixing
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了kafka-为什么选择kafka相关的知识,希望对你有一定的参考价值。
作为开发人员,我们在选择一个框架或者工具时,我们都需要考虑些什么,我们不是头脑发热,一拍脑袋就它了,我们首先要认清这个框架或工具的作用是什么,能给我们带来什么样的好处,同时也要考虑带来什么样的负面结果,我们在使用时才能更好的扬其长避其短,kafka大家可能都不陌生,到底我们为什么选择kafka呢?
1.首先kafka是一个消息队列,作为消息队列一般会在很多场景中用到,如:
应用解耦
在系统交互时,有时我们很难一次性就设计出非常完善的接口,可能会随着业务发展,这些交互接口也会不断的变迁,如果我们的系统较多,系统间交互也较多,维护起来可能就是噩梦,这是可能就需要考虑引入一种基于数据的接口层(消息队列),这样各个系统可以独立的扩展或修改自己的处理过程,只要保证他们准守实现设计的数据格式约束。解耦的同时也提高了系统的稳定性(某个组件失效不会影响其他部分正常运行)和扩展性(可以横向扩展系统以增加处理消息的能力)。
异步处理
有时候我们的业务逻辑可能涉及到很多步骤,而且这些步骤可能上下关联性不是很强,如果我们串行执行时,总耗时=每个步骤耗时之和,如果我们让每个步骤并行处理,总耗时< 每个步骤耗时之和,在这里我们就可以引入消息队列,将每个处理步骤发送到消息队列,并且针对每个处理步骤都有对应的线程去监听,这样就能达到串行执行异步化转为并行执行,从而提高系统的的吞吐量。
流量削峰
在秒杀或抢购活动中,一般会因为流量暴增,应用因处理不过来而挂掉,此时一般会引入消息队列,这样流量会先进入消息队列,我们的应用再根据自己的实际处理能力来消费这些消息,从而达到缓解流量暴增对系统构成的压力
日志处理
有时我们需要采集日志,系统运行中会产生大量的日志,尤其是在流量高峰时,而这项日志需要存储在其他地方,一般进行其他的计算或处理,日志在写入磁盘此时,由于磁盘IO速度可能不是很快,会对系统造成压力,这时我们就可以引入比较高性能的消息队列(kafka往往会被用到),消息队列可以起到缓冲作用。
消息通信
消息队列一般都内置了高效的通信机制,有点对点通信,也有发布订阅式通信,因此也可以用在纯的消息通讯。
冗余存储
消息队列一般会把消息存储起来,只有消费完成后,才把消息删除,这样就防止了某些时候因为处理异常,而导致消息丢失的问题
2.在众多的消息中间件中,为什么选择kafka
主要特性
- 快速持久化:可以在O(1)的系统开销下进行消息持久化;
- 高吞吐:在一台普通的服务器上既可以达到10W/s的吞吐速率;
- 完全的分布式系统:Broker、Producer和Consumer都原生自动支持分布式,自动实现负载均衡;
- 支持同步和异步复制两种高可用机制;
- 支持数据批量发送和拉取;
- 零拷贝技术(zero-copy):减少IO操作步骤,提高系统吞吐量;
- 数据迁移、扩容对用户透明;
- 无需停机即可扩展机器;
- 其他特性:丰富的消息拉取模型、高效订阅者水平扩展、实时的消息订阅、亿级的消息堆积能力、定期删除机制;
优点
- 客户端语言丰富:支持Java、.Net、php、Ruby、Python、Go等多种语言;
- 高性能:单机写入TPS约在100万条/秒,消息大小10个字节;
- 提供完全分布式架构,并有replica机制,拥有较高的可用性和可靠性,理论上支持消息无限堆积;
- 支持批量操作;
- 消费者采用Pull方式获取消息。消息有序,通过控制能够保证所有消息被消费且仅被消费一次;
- 有优秀的第三方KafkaWeb管理界面Kafka-Manager;
- 在日志领域比较成熟,被多家公司和多个开源项目使用。
缺点
- Kafka单机超过64个队列/分区时,Load时会发生明显的飙高现象。队列越多,负载越高,发送消息响应时间变长;
- 使用短轮询方式,实时性取决于轮询间隔时间;
- 消费失败不支持重试;
- 支持消息顺序,但是一台代理宕机后,就会产生消息乱序;
- 社区更新较慢。
附和其他MQ速度对比:
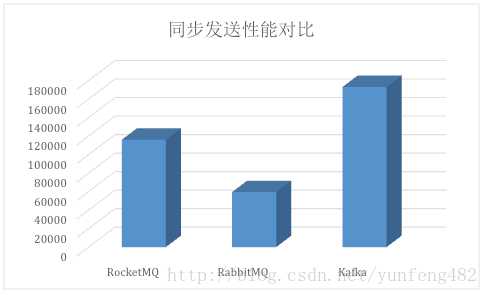
以上是关于kafka-为什么选择kafka的主要内容,如果未能解决你的问题,请参考以下文章