Elasticsearch 快速开始
Posted qg000
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了Elasticsearch 快速开始相关的知识,希望对你有一定的参考价值。
Elasticsearch 快速开始
安装
下载文件并解压。
tar -zxvf elasticsearch-7.5.1-linux-x86_64.tar.gz
cd elasticsearch-7.5.1运行程序
bin/elasticsearch注意不能使用root用户启动Elasticsearch
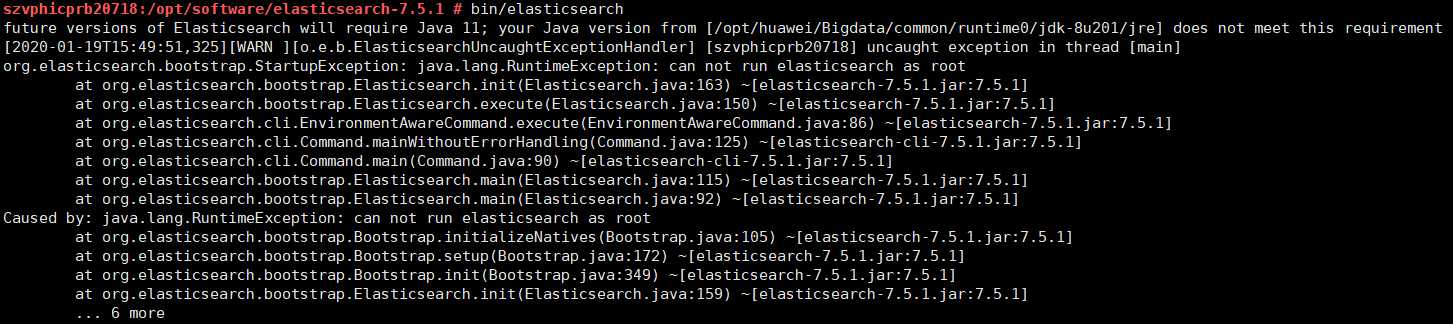
检查Elasticsearch是否正在运行:
curl http://localhost:9200/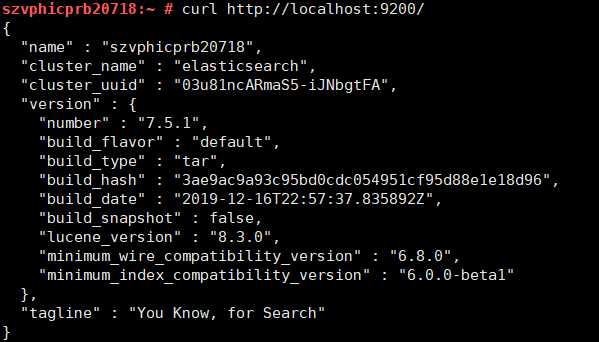
以守护进程来运行
Elasticsearch使用参数 -d 来以守护进程的形式运行, 同时需要使用 -p 参数来记录进程号:
./bin/elasticsearch -d -p pid如果要停止Elasticsearch, 使用kill命令
kill `cat pid`Rest API
集群及索引处理
集群健康
curl -X GET http://localhost:9200/_cat/health?v
集群名称为“elasticsearch”的集群现在是green状态。
集群状态一共分三种: Green、Yellow、Red
- Green : everything is good(一切都很好)(所有功能正常)
- Yellow : 所有数据都是可用的,但有些副本还没有分配(所有功能正常)
- Red : 有些数据不可用(部分功能正常)
从上面的响应中我们可以看到,集群"elasticsearch"总共有1个节点,0个分片因为还没有数据。
下面看一下集群的节点列表:
curl -X GET http://localhost:9200/_cat/nodes?v
可以看到集群中只有一个节点,它的名字是"szvphicprb20718"
查看所有索引
curl -X GET http://localhost:9200/_cat/indices?v
返回意味着集群之中没有索引
创建索引
创建一个名称为"user"的索引
curl -X PUT http://localhost:9200/user?pretty
查看索引
curl -X GET http://localhost:9200/_cat/indices?v
结果的第二行告诉我们,我们现在有叫"user"的索引,并且他有1个主分片和1个副本(默认是1个副本),有0个文档。
"user"索引的健康状态是yellow。yellow意味着一些副本(尚未)被分配。 之所以会出现这种情况,是因为Elasticsearch默认情况下为这个索引创建了一个副本。由于目前我们只有一个节点在运行,所以直到稍后另一个节点加入集群时,才会分配一个副本(对于高可用性)。一旦该副本分配到第二个节点上,该索引的健康状态将变为green。
索引并查询文档
首先put一些数据到"user"索引:
curl -X PUT http://localhost:9200/user/_doc/1?pretty -H 'Content-Type: application/json' -d '{"name": "Zhang San"}'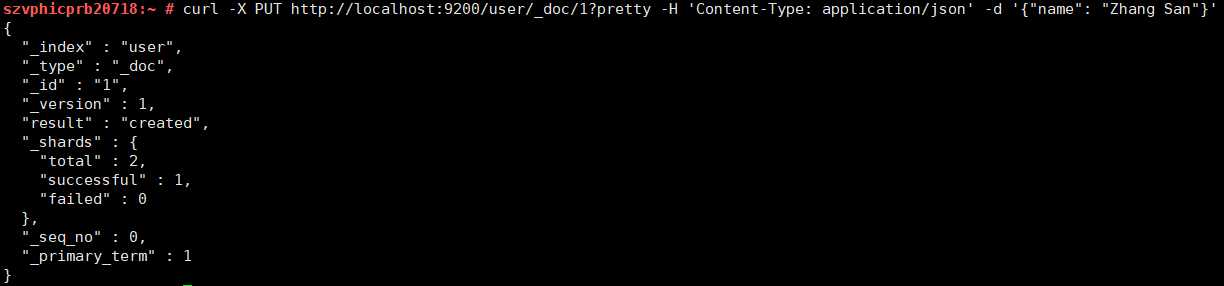
从响应可以看到,我们在"user"索引下成功创建了一个文档。这个文档还有一个内部id为1,这是我们在创建的时候指定的。
需要注意的是,Elasticsearch并不要求你在索引文档之前就先创建索引,然后才能将文档编入索引。在前面的示例中,如果事先不存在"user"索引,Elasticsearch将自动创建"user"索引。
现在重新检索一下这个文档
curl -X GET http://localhost:9200/user/_doc/1?pretty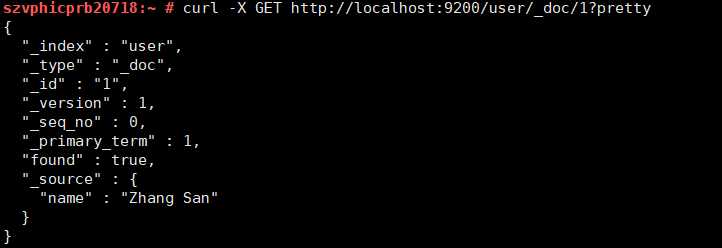
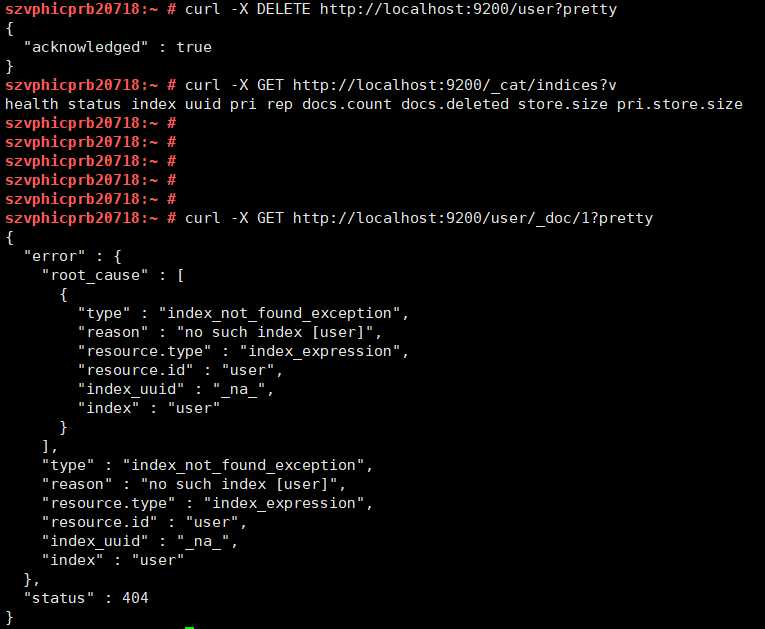
删除索引
curl -X DELETE http://localhost:9200/user?pretty删除索引之后原先索引中的文档也一并删除了
修改数据
更新文档
事实上,每当我们执行更新时,Elasticsearch就会删除旧文档,然后索引一个新的文档。
下面这个例子展示了如何更新一个文档(ID为1),改变name字段为"Li Si",同时添加一个age字段:
curl -X POST http://localhost:9200/user/_doc/1/_update?pretty -H 'Content-Type: application/json' -d '{"doc":{"name": "Li Si", "age": 20 }}'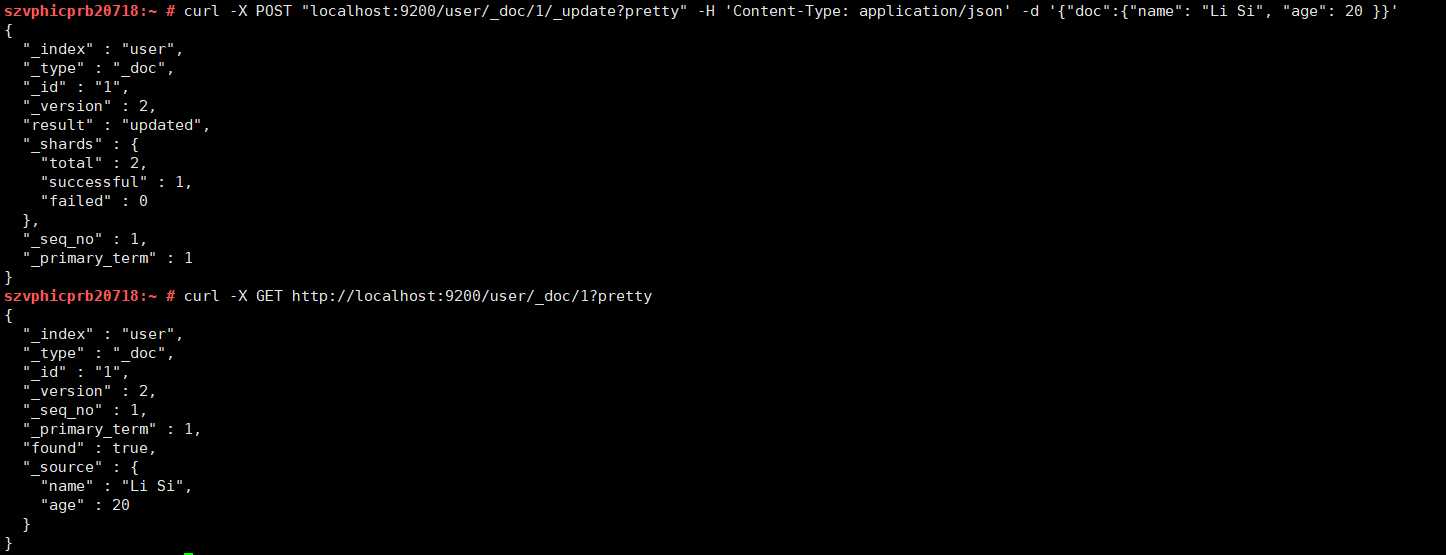
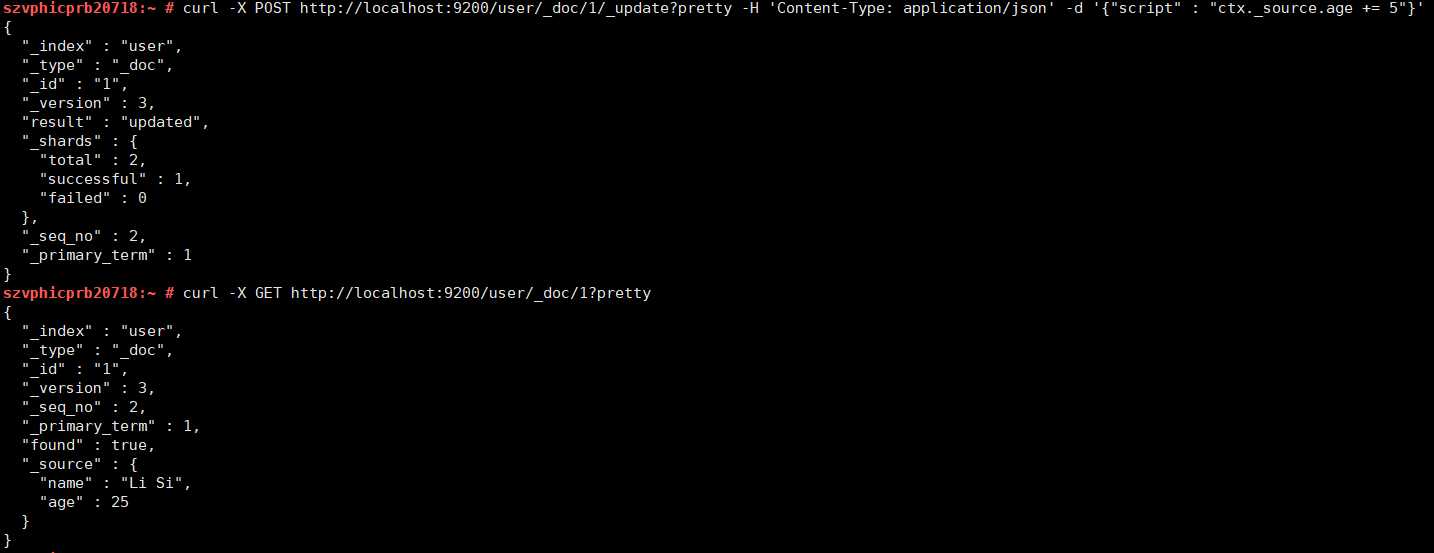
下面这个例子用脚本来将age增加5
curl -X POST http://localhost:9200/user/_doc/1/_update?pretty -H 'Content-Type: application/json' -d '{"script" : "ctx._source.age += 5"}'ctx._source引用的是当前源文档
删除文档
curl -X DELETE http://localhost:9200/user/_doc/1?pretty批处理
除了能够索引、更新和删除单个文档之外,Elasticsearch还可以使用_bulk API批量执行上述任何操作。
这个功能非常重要,因为它提供了一种非常有效的机制,可以在尽可能少的网络往返的情况下尽可能快地执行多个操作。
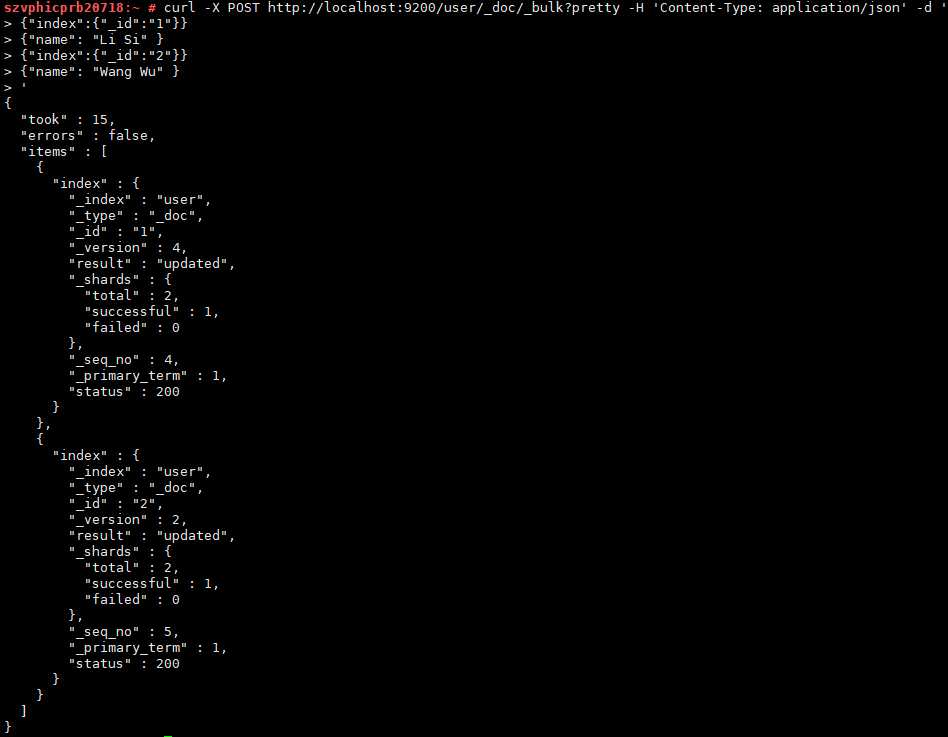
下面的例子,更新两个文档(ID 1 - Li Si 和 ID 2 - Wang Wu)
curl -X POST http://localhost:9200/user/_doc/_bulk?pretty -H 'Content-Type: application/json' -d '
{"index":{"_id":"1"}}
{"name": "Li Si" }
{"index":{"_id":"2"}}
{"name": "Wang Wu" }
'
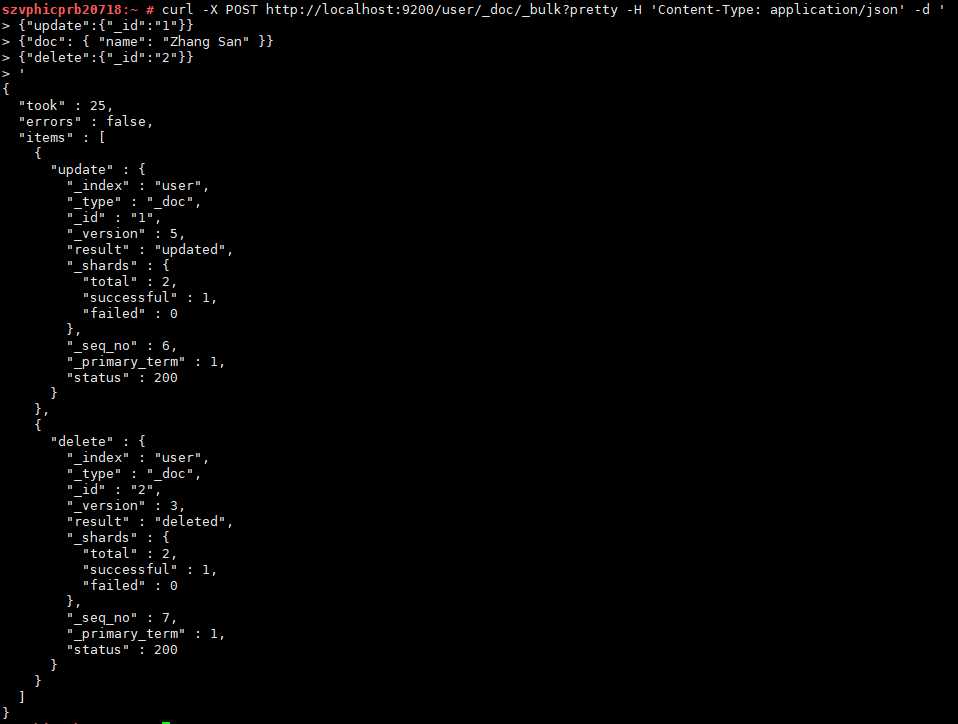
更新第一个文档(ID为1),删除第二个文档(ID为2):
curl -X POST http://localhost:9200/user/_doc/_bulk?pretty -H 'Content-Type: application/json' -d '
{"update":{"_id":"1"}}
{"doc": { "name": "Zhang San" }}
{"delete":{"_id":"2"}}
'
重新查看下文档
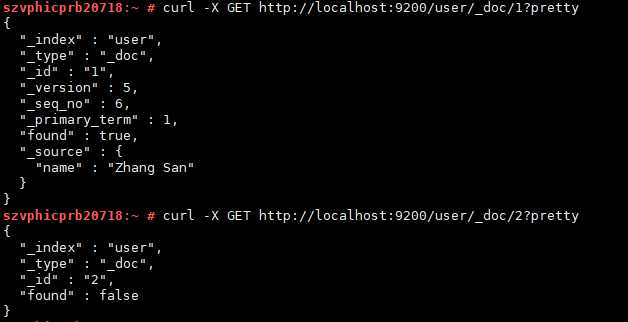
以上是关于Elasticsearch 快速开始的主要内容,如果未能解决你的问题,请参考以下文章