多属性决策
Posted h694879357
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了多属性决策相关的知识,希望对你有一定的参考价值。
一、引言
哈喽大家好,今天我们要讲的一个内容叫“多属性决策”。这个东东它在工程设计、经济、管理和军事等诸多领域中有着广泛的应用。比如:投资决策、项目评估、产业部门发展排序和经济效益综合评价等等。那么接下来我们就要开始我们的内容咯。
二、多属性决策
2.1 概念
首先,什么是多属性决策呢,它指的是利用已有的决策信息通过移动的方式对一组(有限个)备选方案进行排序或者择优。它的主要组成部分有如下2种:
- 获取决策信息:属性权重和属性值(实数、区间数和语言)。
- 通过一定的方式对决策信息进行集结并对方案进行排序和择优
现在我们暂时先抛开属性权重和属性值不讲,我们先来讲一讲第二点,也就是如何对决策的信息进行集结。信息集结的方法有很多,包括
- 加权算术平均算子(WAA)
- 加权几何平均算子(WGA)
- 有序加权平均算子(OWA)
在本文中,我们只讲一下加权算术平均算子(WAA),以后有机会再补充剩下两个。
2.2 加权算术平均算子
对于一组给定的数据: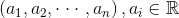 ,有
,有
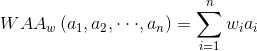
其中,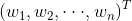 是数据组
是数据组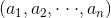 的权重向量,
的权重向量,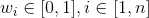 ,则称
,则称
WAA为加权算术平均算子(weighted arithemetic averaging(WAA) operator)。
举例来讲:博主所在的大学大一的统考期末科目有高数、线代、电路、大英(当然还有其他,但是这里就不讲了),其中博主的得分数据组为(95,98,98,90),而这四门科目的学分分别为(5.5,3,2,4),那么可以算出权重向量(每门科目的学分除以总学分)为(0.38,0.21,0.14,0.27)T,那么可以算出博主大一期末的加权平均综合得分为
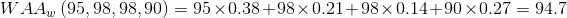
像上述的属性值就是博主的得分数据组,我们知道,得分当然是越高越好,这样的属性值类型也称为效益型;但也有些其他的属性值可能是数值越低越好,这类属性类型称为成本型,比如某公司的某件产品的生产价格;还有一些其他的,都在下面列出:
- 效益型:属性值越大越好(比如利润);
- 成本型:属性值越小越好(比如成本价);
- 固定型:属性值越接近某个固定值α越好(生产标注宽度);
- 偏离型:属性值越偏离某个固定值β越好;
- 区间型:属性值越接近某个固定区间[q1,q2]越好;
- 偏离区间型:属性值越偏离某个固定区间[q1,q2]越好;
那么如果在一堆数据中,可能有些是效益型的,有些是成本型的,这样的数据量纲不同,就会影响到决策的结果,因此,我们需要对属性数据进行规范化处理。具体的处理方案根据不同的属性类型不同,如下:
效益型:属性值越大越好(比如利润):
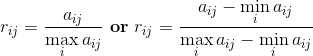
成本型:属性值越小越好(比如成本价):
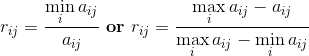
固定型:属性值越接近某个固定值α越好(生产标注宽度):
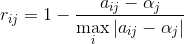
偏离型:属性值越偏离某个固定值β越好:
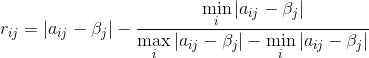
区间型:属性值越接近某个固定区间[q1,q2]越好;
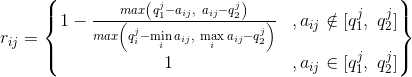
偏离区间型:属性值越偏离某个固定区间[q1,q2]越好;
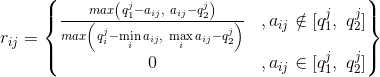
通过将不同属性类型的属性值经过上述公式规范化为统一量纲的数值就,就可以使用我们前面说的加权算术平均算子了。接来来用一个实例来描述多属性决策模型在投资上的应用。
三、建模举例
问题:某投资银行拟对某市4家企业进行投资,抽取下列5项指标进行评估:产值(万元)、投资成本(万元)、销售额(万元)、国家收益币种、环境污染程度。投资银行考查了上年度4家企业的上述指标情况(其中污染程度由环保部门及时检测并量化),所得评估结果如下表所示。在各项指标中,投资成本、环境污染程度为成本型,其他为效益型。属性权重信息完全未知,试确定最佳投资方案。
解法:
1.先写出归一化处理前的决策矩阵(题目已给出的那个表,博主懒得画两遍就在这里显示吧hh),其中x表示企业,u1到u5表示产值(万元)、投资成本(万元)、销售额(万元)、国家收益币种、环境污染程度这5项指标,则
| u1 | u2 | u3 | u4 | u5 | |
| x1 | 8350 | 5300 | 6135 | 0.82 | 0.17 |
| x2 | 7455 | 4952 | 6527 | 0.65 | 0.13 |
| x3 | 11000 | 8001 | 9008 | 0.59 | 0.15 |
| x4 | 9624 | 5000 | 8892 | 0.74 | 0.28 |
2.根据我们前面起到的归一化公式,将上述指标值代入相应的公式,就能得到归一化处理后的决策矩阵,如下:
| u1 | u2 | u3 | u4 | u5 | |
| x1 | 0.7455 | 0.9343 | 0.6811 | 1.0000 | 0.7647 |
| x2 | 0.6777 | 1.0000 | 0.7246 | 0.7926 | 1.0000 |
| x3 | 1.0000 | 0.6189 | 1.0000 | 0.7195 | 0.8667 |
| x4 | 0.8749 | 0.9904 | 0.9871 | 0.9024 | 0.4643 |
3.接下来我们需要应用到上一节用到的知识了,就是构建成对比较矩阵,为什么呢。大家还记得2.1讲的东西吗,其中第一点的决策信息就包括两部分——属性权重和属性值,现在我们已经求出归一化后的属性值了,我们还不知道属性的权重是多少,因此,我们需要通过构建成对比较矩阵,再将成对矩阵输入到我们的MATLAB程序里面,就能求出属性的权重了。为此,我们先写出成对比较矩阵,如下:

将上述矩阵代入我们的matlab代码(上一节层次分析法的代码)里,就能得到u1到u5的权重分别为:[0.4286, 0.1429, 0.1429, 0.1429, 0.1429].
4.现在我们有了属性权重和归一化的属性值了,就可以利用加权算术平均算子了,分别能算出4个企业的加权算术平均值了,如下:
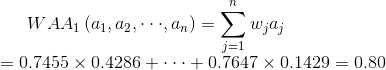
在这里我只算出第一个企业的加权算术平均值,剩下三个大家自己照着公式算一下,如果你算得没错,那么答案应该如下(企业1-4的得分分别为):
0.80 0.79 0.89 0.85
显然,应该投资企业3.
以上是关于多属性决策的主要内容,如果未能解决你的问题,请参考以下文章