7.3 Shuffle过程和排序
Posted bclshuai
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了7.3 Shuffle过程和排序相关的知识,希望对你有一定的参考价值。
1.1 Shuffle和排序
Shuffle:系统执行排序,将map输出作为输入传给reduce的过程称为shuffle。
1.1.1 Map端缓存排序输出
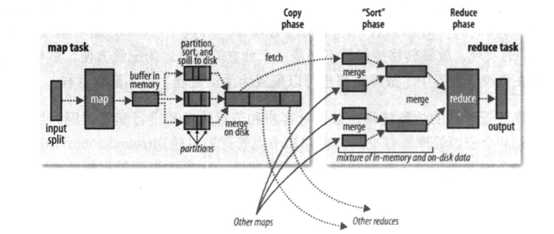
(1) 写入缓冲区:map输出结果先输出到内存缓冲区(默认100M,通过属性mapreduce.Task.io.sort.mb设置)
(2) 分区排序:线程将内存中的数据划分成相应的分区(partion),按键进行预排序;
(3) 溢出文件:combine函数在排序后的输出上运行,直到缓冲器超过80%(属性mapreduce.map.sort.spill.percent),就会新建一个溢出文件,一个后台线程将结果输出到磁盘,缓冲区满了,map会阻塞等待缓冲区写入磁盘。;
(4) 执行Combine函数减小数据量:如果溢出文件数量超出mapreduce.map.combine.minspills属性设置的阈值(默认3),可以对溢出文件再次执行combine函数,以减少写入磁盘的数据。如果溢出文件数量少于3,属于小规模数据,则调用combine函数带来的开销更大,不会执行combine。
(5) 压缩减少数据量:还可以对输出结果进行压缩,以写入磁盘的数据量和传给reduce的数据量。通知属性mapreduce.map.output.compress设置true来开启压缩。
(6) 合并溢出文件:最后将溢出文件合并成易分期且已排序的输出文件,属性mapreduce.task.io.sort.factor控制一次最多合并多少个文件。默认10。
1.1.2 Reduce端
(1) 复制线程复制Map输出作为reduce输入:Map输出文件存在map任务的tasktracker的本地磁盘,复制线程(默认5个,由属性mapreduce.shuffle.parallelcopies属性设置)会复制集群上若干个map输出文件作为输入。Map输出小则复制到reduce任务的JVM内存(缓冲区大小由属性mapreduce.reduce.shuffle.input.buffer.percent属性控制),太大则溢出写入磁盘。
(2) 文件合并输出到reduce:后台线程将多个文件按照合并因子mapreduce.task.io.sort.factor设置的数量值(默认10)进行合并,40个文件4,10,10,10合并为4中间文件写到磁盘,在和剩下的6个文件合并一个到reduce。保证合并次数相同的情况下,写入磁盘的数据量最少。
(3) Reduce函数处理文件:直接输出到文件系统,一般为HDFS。
(4) 清除中间文件:Reuduce任务完成之后,通知application master 删除map输出的中间成果物。
自己开发了一个股票智能分析软件,功能很强大,需要的点击下面的链接获取:
https://www.cnblogs.com/bclshuai/p/11380657.html
以上是关于7.3 Shuffle过程和排序的主要内容,如果未能解决你的问题,请参考以下文章