如何预测股票分析--线性回归
Posted xingnie
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了如何预测股票分析--线性回归相关的知识,希望对你有一定的参考价值。
继续上一篇,接下来是股票分析中使用线性回归
在现实世界中,存在着大量这样的情况:两个变量例如X和Y有一些依赖关系。由X可以部分地决定Y的值,但这种决定往往不很确切。常常用来说明这种依赖关系的最简单、直观的例子是体重与身高,用Y表示他的体重。众所周知,一般说来,当X大时,Y也倾向于大,但由X不能严格地决定Y。又如,城市生活用电量Y与气温X有很大的关系。在夏天气温很高或冬天气温很低时,由于室内空调、冰箱等家用电器的使用,可能用电就高,相反,在春秋季节气温不高也不低,用电量就可能少。但我们不能由气温X准确地决定用电量Y。类似的例子还很多,变量之间的这种关系称为“相关关系”,回归模型就是研究相关关系的一个有力工具。
线性回归模型生成一个确定自变量和因变量之间关系的方程。
线性回归方程可以写成:
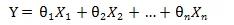 x1, x2, ....xn代表自变量,系数θ1,θ2,....θn代表权重。
x1, x2, ....xn代表自变量,系数θ1,θ2,....θn代表权重。
使用时间(date)列提取特征,如- day, month, year, mon/fri等,然后拟合线性回归模型。
首先按升序对数据集进行排序,然后创建一个单独的数据集,这样创建的任何新特性都不会影响原始数据。
#setting index as date values 以date作为索引
df[‘Date‘] = pd.to_datetime(df.Date,format=‘%Y-%m-%d‘)
df.index = df[‘Date‘]
#sorting 升序排列
data = df.sort_index(ascending=True, axis=0)
#creating a separate dataset 创建一个单独的数据集
new_data = pd.DataFrame(index=range(0,len(df)),columns=[‘Date‘, ‘Close‘])
#将数据中的date和close都放到一个list中
for i in range(0,len(data)):
new_data[‘Date‘][i] = data[‘Date‘][i]
new_data[‘Close‘][i] = data[‘Close‘][i]
#create features 自己添加一些特征,同时第三行删除了一些数据
from fastai.structured import add_datepart
add_datepart(new_data, ‘Date‘)
new_data.drop(‘Elapsed‘, axis=1, inplace=True) #elapsed will be the time stamp
这将创建以下特征:
‘Year’, ‘Month’, ‘Week’, ‘Day’, ‘Dayofweek’, ‘Dayofyear’, ‘Is_month_end’, ‘Is_month_start’, ‘Is_quarter_end’, ‘Is_quarter_start’, ‘Is_year_end’, and ‘Is_year_start’.
注意:我使用了来自fastai库的add_datepart。如果您没有安装它,您可以简单地使用命令pip install fastai。您也可以使用python中的简单for循环来创建这些特性。我在下面展示了一个例子。
除此之外,我们还可以添加自己的一组特性,我们认为这些特性与预测相关。例如,我的假设是,本周的头几天和最后几天对股票收盘价的影响可能远远超过其他日子。因此,我创建了一个特性来识别给定的一天是星期一/星期五还是星期二/星期三/星期四。这可以用以下几行代码来完成:
new_data[‘Dayofweek‘][i] == 0 代表 周日 (因为数组下标标注都是从0开始的)
new_data[‘Dayofweek‘][i] == 4 代表 周一
mon_fri其实就是一个flag,如果是星期日或星期五,列值将为1,否则为0。
new_data[‘mon_fri‘] = 0
for i in range(0,len(new_data)):
if (new_data[‘Dayofweek‘][i] == 0 or new_data[‘Dayofweek‘][i] == 4):
new_data[‘mon_fri‘][i] = 1
else:
new_data[‘mon_fri‘][i] = 0
类似地,您可以创建多个有助于预测股价的特征
现在我们将把数据分成训练集和验证集来检查模型的性能。
#split into train and validation 分成训练集和验证
train = new_data[:987]
valid = new_data[987:]
#这里把训练集和验证集中的close的列剔除
x_train = train.drop(‘Close‘, axis=1)
y_train = train[‘Close‘]
x_valid = valid.drop(‘Close‘, axis=1)
y_valid = valid[‘Close‘]
#implement linear regression 使用sklearn的库函数构建模型
from sklearn.linear_model import LinearRegression
model = LinearRegression()
model.fit(x_train,y_train)
结果
#make predictions and find the rmse模型预测,计算rmse
preds = model.predict(x_valid)
rms=np.sqrt(np.mean(np.power((np.array(y_valid)-np.array(preds)),2)))
#这下面两行是计算结果,可不执行
rms
121.16291596523156
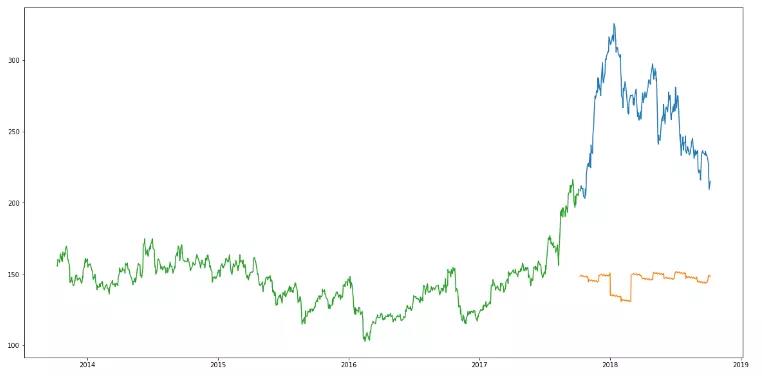
RMSE值高于之前的方法,这清楚地表明线性回归的表现很差。让我们看看这个图,并理解为什么线性回归预测效果不是很好:
#plot 打印绘图
valid[‘Predictions‘] = 0
valid[‘Predictions‘] = preds
#下面这两行颠倒一下会好理解一些,分别取两个数据集的索引
valid.index = new_data[987:].index
train.index = new_data[:987].index
#打印训练集中close的部分(之前训练的时候删除了),打印测试集中close和预测值
plt.plot(train[‘Close‘])
plt.plot(valid[[‘Close‘, ‘Predictions‘]])
推论
线性回归是一种简单的技术,很容易解释,但也有一些明显的缺点。
使用回归算法的一个问题是,模型过度拟合了日期和月份。模型将考虑一个月前相同日期或一年前相同日期/月的值,而不是从预测的角度考虑以前的值。
从上图可以看出,2016年1月和2017年1月,股价出现下跌。该模型预测2018年1月也将如此。
线性回归技术可以很好地解决像大卖场销售这样的问题,在这些问题中,独立的特征对于确定目标值是有用的。
参考:https://www.jiqizhixin.com/articles/2019-01-04-16
以上是关于如何预测股票分析--线性回归的主要内容,如果未能解决你的问题,请参考以下文章