OpenCV 和 Dlib 人脸识别基础
Posted geoffreygao
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了OpenCV 和 Dlib 人脸识别基础相关的知识,希望对你有一定的参考价值。
00 环境配置
Anaconda 安装
1 下载
https://repo.anaconda.com/archive/
考虑到兼容性问题,推荐下载Anaconda3-5.2.0版本。
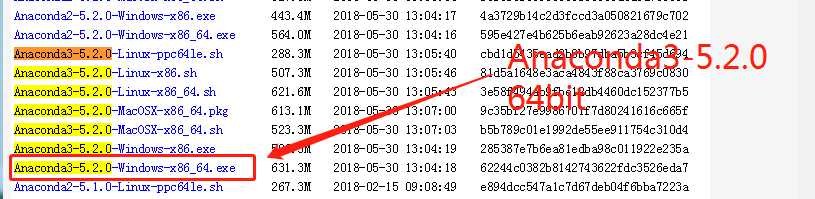
- 2 安装
- 3 测试
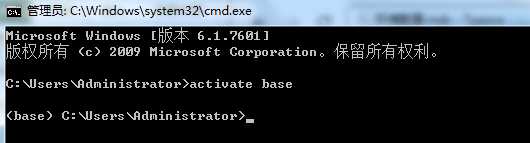
在键盘按 Win + R, 输入 cmd,回车,将会打开cmd窗口,输入 activate base, 如下所示,表明anaconda环境系统变量无误。
IDE PyCharm的安装
自行百度搜索下载并破解。
OpenCV安装
C:UsersAdministrator>activate base
(base) C:UsersAdministrator>pip install opencv-python # [回车]
(base) C:UsersAdministrator>pip install opencv-contrib-python # [回车]pip换源
- Win + R
- %HOMEPATH%
- 新建pip文件夹,在文件夹内新建pip.ini文件,文件内容如下:
[global]
index-url = http://mirrors.aliyun.com/pypi/simple/
[install]
trusted-host = mirrors.aliyun.comDlib 安装
.whl文件下载
推荐下载下面两个之一:

自行搜索.whl文件的安装,注意基于anaconda环境。
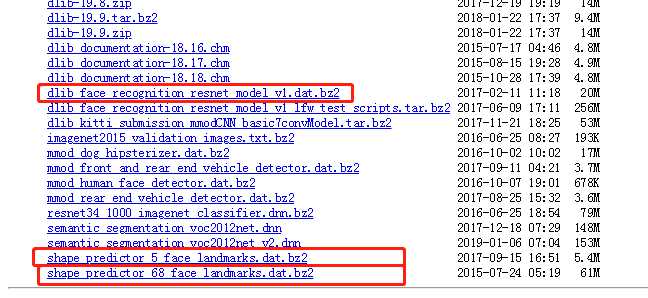
数据集下载准备
下载下面三个数据集。

1 OpenCV 中的 Gui 特性
1.1 图片
本节重点:(image)
- 图片的读入(
cv2.imread()) 图片的显示(
cv2.imshow())- 图片的保存(
cv2.imwrite()) 拓展:matplotlib
1.1.1 图片的读入
cv2.imread()
查看该函数的帮助文档:
>>> import cv2
>>> help(cv2.imread)由帮助文档,我们可以看出,imread() 使用的语法格式如下:
imread(filename[, flags])- filename:图像路径及名称。
- flags:告诉函数应该如何读取这幅图片。
- cv2.IMREAD_COLOR:读入一副彩色图像。图像的透明度会被忽略,默认参数。 --->传递参数:1
- cv2.IMREAD_GRAYSCALE:以灰度模式读入图像 。--->传递参数:0
- cv2.IMREAD_UNCHANGED:读入一幅图像,并且包括图像的 alpha 通道
import numpy as np
import cv2
# 以灰度模式加载图像
# img = cv2.imread('test.jpg', cv2.IMREAD_GRAYSCALE)
img = cv2.imread('test.jpg', 0)此时,打印img,返回一组矩阵值。
注意:就算图像的路径是错的, OpenCV 不会产生任何提醒,但是当print(img)时,得到的结果是None。
1.1.2 图片的显示
cv2.imshow(),其语法格式如下:
imshow(winname, mat)显示图像时,图像会自动调整为图像大小。
- winname:窗口名称
- mat:图像(矩阵)
cv2.imshow('demo', img)
cv2.waitKey(0)
cv2.destroyAllWindows()其中,
cv2.waitKey()- 键盘绑定函数
- 它的时间尺度是毫秒级。函数等待特定的几毫秒,看是否有键盘输入。特定的几毫秒之内,如果按下任意键,这个函数会返回按键的 ASCII 码值,程序将会继续运行。如果没有键盘输入,返回值为 -1,如果我们设置这个函数的参数为 0,那它将会无限期的等待键盘输入。它也可以被用来检测特定键是否被按下,例如按键 a 是否被按下, 后续会讨论。
- 键盘绑定函数
cv2.destroyAllWindows()- 退出任何已建立的窗口。
- 如果退出指定的窗口,可以使用
cv2.destroyWindow([name]),[name]为我们欲退出的窗口名称。
Notes:
一 种 特 殊 的 情 况 是, 你 也 可 以 先 创 建 一 个 窗 口, 之 后再 加 载 图 像。 这 种 情 况 下, 你 可 以 决 定 窗 口 是 否 可 以 调 整大 小。 使 用 到 的 函 数 是 cv2.namedWindow()。 初 始 设 定 函 数标 签 是 cv2.WINDOW_AUTOSIZE。 但 是 如 果 你 把 标 签 改 成cv2.WINDOW_NORMAL,你就可以调整窗口大小了。当图像维度太大,或者要添加轨迹条时,调整窗口大小将会很有用
Demo:
import numpy as np import cv2 img = cv2.imread('demo.jpg') cv2.namedWindow('demo', cv2.WINDOW_NORMAL) cv2.imshow('demo', img) cv2.waitKey(0) cv2.destroyAllWindows()此时,显示出来的图片,我们就可以调整窗口了。
1.1.3 图片的保存
cv2.imwrite(),其语法格式如下:
imwrite(filename, img[, params])- filename:图像要保存的路径及名称。
- img:图像矩阵。
cv2.imwrite('./savetest.png', img)1.1.4 键盘控制窗口
首先,看一个例子:
# import numpy as np
import cv2
img = cv2.imread('demo.jpg', 0)
cv2.imshow('demo', img)
k = cv2.waitKey(0)
if k == ord('q'):
cv2.destroyAllWindows()
elif k == ord('s'):
cv2.imwrite('savetest.jpg', img)
cv2.destroyAllWindows()注意:如果你用的是 64 位系统,你需要将 k = cv2.waitKey(0) 这行改成k = cv2.waitKey(0)&0xFF。
1.1.5 matplotlib的结合
Matplotib 是 python 的一个绘图库,有各种各样的绘图方法。之后会陆续了解到。现在,你可以学习怎样用 Matplotib 显示图像。你可以放大图像,保存它等等。
import numpy as np
import cv2
import matplotlib.pyplot as plt
img = cv2.imread('demo.jpg', 0) # grayimage
plt.imshow(img, cmap='gray', interpolation='bicubic')
plt.axis('off')
plt.show()延伸:
程序中,我们以灰度模式读取图像,尝试其他模式读取图像,看一下最终显示的图像有什么不同。
彩色图像使用 OpenCV 加载时是 BGR 模式。但是 Matplotib 是 RGB模式。所以彩色图像如果已经被 OpenCV 读取,那它将不会被 Matplotib 正确显示。
import cv2
import numpy as np
import matplotlib.pyplot as plt
img = cv2.imread('demo.jpg')
b, g, r = cv2.split(img)
img2 = cv2.merge([r, g, b])
plt.subplot(121);plt.imshow(img) # expects distorted color
plt.subplot(122);plt.imshow(img2) # expect true color
plt.show()
cv2.imshow('bgr image',img) # expects true color
cv2.imshow('rgb image',img2) # expects distorted color
cv2.waitKey(0)
cv2.destroyAllWindows()import cv2
import numpy as np
import matplotlib.pyplot as plt
img = cv2.imread('demo.jpg')
cv2.cvtColor(img, cv2.COLOR_BGR2RGB)
cv2.imshow('RGB image', img)
cv2.waitKey(0)
cv2.destroyAllWindows()1.2 视频
本节重点
- 视频文件读取
- 视频文件显示
- 视频文件保存
- 摄像头获取并显示视频
- 两个函数cv2.VideoCapture()和cv2.VideoWriter()
1.2.1 用摄像头捕获视频
OpenCV为摄像头捕捉实时图像提供了一个十分简单的接口。
现在我们尝试捕捉一段视频,并将其转换为灰度视频并显示出来。
cv2.VideoCapture():视频获取函数。
通过help()命令查看其使用:
help(cv2.VideoCapture)为获取视频,需要创建一个 VideoCapture 对象。其参数可以是设备的索引号,或者是一个视频文件。设备索引号就是指定要使用的摄像头。一般的笔记本电脑都有内置摄像头。所以参数就是 0。你可以通过设置成 1 或者其他的来选择别的摄像头。之后,你就可以一帧一帧的捕获视频了。但是最后,别忘了停止捕获视频。
Demo:
import numpy as np
import cv2
cap = cv2.VideoCapture(0)
if not cap.isOpened():
print("Can't open camera")
exit()
while True:
# 一帧一帧的捕获视频
ret, frame = cap.read()
if not ret:
print("Can't receive frame (stream end?). Exiting...")
break
# 对幁视频进行操作
gray = cv2.cvtColor(frame, cv2.COLOR_BGR2GRAY)
# 显示结果
cv2.imshow('frame', gray)
if cv2.waitKey(1) & 0xff == ord('q'):
break
# 释放捕获
cap.release()
cv2.destroyAllWindows()- cap.read() 返回一个布尔值。
- 如果幁读取正确,则返回True,否则,返回False。
- 可以通过检查其返回值来查看文件是否到了结尾。
cap可能不能成功的初始化摄像头设备。此时,代码会报错。这个时候,可以使用cap.isOpened(),来检查是否成功初始化了。如果返回值为True,说明初始化成功。否则,可以使用函数cap.open()。
你可以使用函数cap.get(propId)来获得视频的一些参数信息。这里propId 可以是 0 到 18 之间的任何整数。每一个数代表视频的一个属性,见下表 cv::VideoCapture::get() ,其中的一些值可以使用 cap.set(propId,value)来修改, value 就是你想要设置成的新值。
例如,我可以使用cap.get(cv.CAP_PROP_FRAME_WIDTH) 和 cap.get(cv.CAP_PROP_FRAME_HEIGHT) (比如cpa.get(3)和cap.get(4) 来查看每一帧的宽和高。默认情况下得到的值是 640X480。但是我们可以使用 ret = cap.set(cv.CAP_PROP_FRAME_WIDTH,320) and ret = cap.set(cv.CAP_PROP_FRAME_HEIGHT,240)(比如ret=cap.set(3,320)和 ret=cap.set(4,240) )来把宽和高改成 320X240。
1.2.2 视频保存
我们捕获视频,逐帧处理,我们希望保存该视频。 对于图像,保存非常简单,只需使用cv.imwrite()。 对于视频的保存,需要做更多的工作。
这次我们创建一个VideoWriter对象。 我们应该指定输出文件名(例如:output.avi)。 然后我们应该指定FourCC编码。 然后,应传递的每秒帧数(fps)和帧大小。 最后一个是isColor标志。 如果是True,则是彩色帧,否则,它适用于灰度帧。
FourCC是一个4字节编码,用于指定视频编解码器。 可在fourcc.org中找到可用代码列表。 它的平台是独立的。 以下编解码器对我来说很好。
- In Fedora: DIVX, XVID, MJPG, X264, WMV1, WMV2. (XVID is more preferable. MJPG results in high size video. X264 gives very small size video)
- In Windows: DIVX (More to be tested and added)
- In OSX: MJPG (.mp4), DIVX (.avi), X264 (.mkv).
FourCC 码以下面的格式传给程序,以 MJPG 为例:
cv2.cv2.FOURCC(‘M‘,‘J‘,‘P‘,‘G‘)或者 cv2.cv2.FOURCC(*‘MJPG‘)。
下面的代码是从摄像头中捕获视频,沿水平方向旋转每一帧并保存它 。
import numpy as np
import cv2
cap = cv2.VideoCapture(0)
# Define the codec and create Videowriter object
fourcc = cv2.VideoWriter_fourcc(*'XVID')
out = cv2.VideoWriter('output.avi', fourcc, 20.0, (640, 480))
while(cap.isOpened()):
ret, frame = cap.read()
if ret == True:
frame = cv2.flip(frame, 0)
# write the flipped frame
out.write(frame)
cv2.imshow('frame', frame)
if cv2.waitKey(1) &0xFF == ord('q'):
break
else:
break
cap.release()
out.release()
cv2.destroyAllWindows()1.2.3 从文件中播放视频
与从摄像头中捕获相同,我们只需要把设备索引号改成视频文件的名字。在播放每一帧时,使用cv2.waitKey()设置适当的持续时间。如果设置的太低,视频会播放的很快。如果设置的太大,视频就是播放的很慢(可用来控制视频的播放速度,通常25ms即可)
import numpy as np
import cv2
cap = cv2.VideoCapture('output.avi')
while cap.isOpened():
ret, frame = cap.read()
# if frame is read correctly ret is True
if not ret:
print("Can't receive frame (stream end?). Exiting...")
break
gray = cv2.cvtColor(frame, cv2.COLOR_BGR2GRAY)
cv2.imshow('frame', gray)
if cv2.waitKey(1) == ord('q'):
break
cap.release()
cv2.destroyAllWindows()1.3 OpenCV中的绘图函数
目标:
- 学会用OpenCV绘制不同的几何形状
- 将要学习的函数:
- cv2.line()
- cv2.circle()
- cv2.rectangle()
- cv2.ellipse()
- cv2.putText()
- etc.
编码约定
涉及的所有绘图函数,设置如下:
?img:你想要绘制图形的图像。
?color:形状的颜色。以 RGB 为例,需要传入一个元组,例如:(255,0,0),代表蓝色。对于灰度图只需要传入灰度值。
?thickness:线条的粗细。如果给一个闭合图形设置参数为 -1,那么这个图形就会被填充。默认值是 1。
?linetype:线条的类型, 8 联通线型,抗锯齿线型等。默认情况是 8 联通线型。 cv2.LINE_AA为抗锯齿线型,这样看起来会非常平滑。
1.3.1 直线绘制
要绘制线条,需要传递线条的起点和终点坐标。
接下里的例子中,我们将创建一个黑色图像,并在其中从左上角到右下角绘制一条蓝线。
import numpy as np
import cv2
# Create a black image
img = np.zeros((512, 512, 3), np.uint8)
# Draw a diagonal blue line with thickness of 5 px
cv2.line(img, (0, 0), (511, 511), (255, 0, 0), 5)
cv2.imshow('bgr', img)
cv2.waitKey(0)
cv2.destroyAllWindows()matplotlib:
import numpy as np
import cv2
import matplotlib.pyplot as plt
# Create a black image
img = np.zeros((512, 512, 3), np.uint8)
# Draw a diagonal blue line with thickness of 5 px
cv2.line(img, (0, 0), (511, 511), (0, 0, 255), 5)
plt.imshow(img, 'gray')
plt.show()1.3.2 矩形绘制
要绘制矩形,您需要指定矩形的左上角和右下角。 这次我们将在图像的右上角绘制一个绿色矩形。
# Draw a green rectangle at the top-right corner of image
cv2.rectangle(img, (384, 0), (510, 128), (0, 255, 0), 3)1.3.3 圆形绘制
要绘制圆,需要其中心坐标和半径。
我们将在上面绘制的矩形内绘制一个圆。
# Draw a circle inside the rectangle drawn above
cv2.circle(img, (447, 63), 63, (0, 0, 255), -1)1.3.4 椭圆绘制
要绘制椭圆,我们需要传递几个参数。 一个参数是中心位置(x,y)。 下一个参数是轴长度(长轴长度,短轴长度)。 角度是椭圆在逆时针方向上的旋转角度。 startAngle和endAngle表示从主轴顺时针方向测量的椭圆弧的起点和终点。 即给出值0和360给出完整的椭圆。 有关更多详细信息,请查看cv.ellipse()的文档。 下面的示例在图像的中心绘制一个半椭圆。
# Draws a half ellipse at the center of the image
cv2.ellipse(img, (255, 256), (100, 50), 0, 0, 180, (0, 0, 255), -1)1.3.5 多边形绘制
要绘制多边形,首先需要顶点坐标。 将这些点组成一个形状为ROWSx1x2的数组,其中ROWS是顶点数,它应该是int32类型。 在这里,我们绘制一个带有四个黄色顶点的小多边形。
# raw a small polygon of with four vertices in yellow color
pts = np.array([[10, 5],
[20, 30],
[70, 20],
[50, 10]],
np.int32)
pts = pts.reshape((-1, 1, 2))
cv2.polylines(img, [pts], True, (0, 255, 255))注意
- 如果第三个参数为False,您将获得连接所有点的折线,而不是闭合形状。
cv2.polylines()可用于绘制多条线。 只需创建要绘制的所有行的列表,然后将其传递给函数。 所有线条都将单独绘制。 绘制一组行比为每行调用cv2.line()要好得多,速度更快。
1.3.6 向图像添加文本:
为了将文本放入图像中,您需要指定以下内容:
- 要写入的文本数据
- 放置位置坐标(即数据开始的左下角)。
- 字体类型(使用
cv2.putText()的帮助文档可以查看OpenCV支持的字体) - 字体缩放(指定字体大小)
- 常规的东西,如颜色,粗细,线型等。为了更好看,建议使用
lineType = cv2.LINE_AA。
我们将在图像上书写白色的"OpenCV"字样。
font = cv2.FONT_HERSHEY_SIMPLEX
cv2.putText(img, 'Hello, OpenCV', (10, 500), font, 2, (255, 255, 255), 2, cv2.LINE_AA)最后,是时候看看我们绘图的最终结果了。
正如之前文章中所研究的那样,显示图像以查看它:
import numpy as np
import cv2
# Create a black image
img = np.zeros((512, 512, 3), np.uint8)
# Draw a diagonal blue line with thickness of 5 px
cv2.line(img, (0, 0), (511, 511), (255, 0, 0), 5)
cv2.rectangle(img, (384, 0), (510, 128), (0, 255, 0), 3)
cv2.circle(img, (447, 63), 63, (0, 0, 255), -1)
cv2.ellipse(img, (255, 256), (100, 50), 0, 0, 180, 255, -1)
pts = np.array([[10, 5],
[20, 30],
[70, 20],
[50, 10]],
np.int32)
pts = pts.reshape((-1, 1, 2))
cv2.polylines(img, [pts], True, (0, 255, 255))
font = cv2.FONT_HERSHEY_SIMPLEX
cv2.putText(img, 'Hello, OpenCV', (10, 500), font, 2, (255, 255, 255), 2, cv2.LINE_AA)
cv2.imshow('bgr', img)
cv2.waitKey(0)
cv2.destroyAllWindows()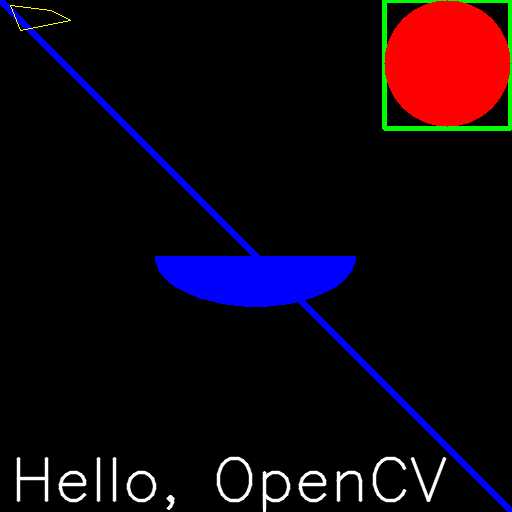
其他资源
椭圆函数中使用的角度不是我们的圆角。 有关更多详细信息,请访问此讨论。
练习
尝试使用OpenCV中提供的绘图功能创建OpenCV的徽标。
# OpenCV徽标绘制
import numpy as np
import cv2
# 创建白色背景画布
img = np.ones((512, 512, 3), np.uint8) * 255
# 绘制3个圆
cv2.circle(img,(256,200),60,(0,0,255),-1)
cv2.circle(img,(256,200),25,(255,255,255),-1)
cv2.circle(img,(181,328),60,(0,255,0),-1)
cv2.circle(img,(181,328),25,(255,255,555),-1)
cv2.circle(img,(331,328),60,(255,0,0),-1)
cv2.circle(img,(331,328),25,(255,255,255),-1)
# 在圆环上叠加三角形,形成缺口圆环的效果
tri1=np.array([256,200,219,264,293,264],np.int32)
tri1=tri1.reshape((-1,1,2))
tri2=np.array([[181,328],[256,328],[218,264]],np.int32)
tri3=np.array([[331,328],[368,264],[293,264]],np.int32)
cv2.fillPoly(img,[tri1,tri2,tri3],(255,255,255)) # 为方便看清,颜色可先设置
# 添加文字
font=cv2.FONT_HERSHEY_SIMPLEX
cv2.putText(img, 'OpenCV', (125,450), font, 2, (0, 0, 0), 10)
cv2.imshow('bgr', img)
cv2.waitKey(0)
cv2.destroyAllWindows()
2 核心操作
在本节中,我们将学习图像的基本操作,如像素编辑,几何变换,代码优化,一些数学工具等。
2.1 图片的基本操作
目标:
- 访问并修改像素值
- 访问图像属性
- 设置感兴趣区域(ROI)
- 拆分和合并图像通道
本节中的几乎所有操作主要与Numpy而不是OpenCV有关。 使用OpenCV编写更好的优化代码需要熟悉Numpy。
(示例将在Python终端中显示,因为大多数只是单行代码)
2.1.1 获取并修改像素值
首先,我们加载一幅彩色图像
>>> import numpy as np
>>> import cv2
>>> img = cv2.imread('demo.jpg')
>>>我们可以通过像素值的行和列坐标来访问像素值。 对于BGR图像,它返回一个蓝色,绿色,红色值的数组。 对于灰度图像,仅返回相应的强度。
>>> px = img[100, 100]
>>> px
array([57, 63, 68], dtype=uint8)
# accessing only blue pixel
>>> blue = img[100, 100, 0]
>>> blue
57
>>>我们可以用同样的方法来修改像素值
>>> img[100, 100] = [255, 255, 255]
>>> img[100, 100]
array([255, 255, 255], dtype=uint8)
>>>警告
Numpy是经过优化了的进行快速矩阵运算的软件包。所以我们不推荐逐个获取像素值并修改,这样会很慢,能有矩阵运算就不要用循环。
注意:
上面提到的方法被用来选取矩阵的一个区域,比如说前 5 行的后 3列。对于获取每一个像素值,也许使用 Numpy 的 array.item() 和 array.itemset() 会更好。但是返回值是标量。如果你想获得所有 B,G,R 的值,你需要使用 array.item() 分割他们。
获取像素值及修改的更好方法。
# accessing RED value
>>> img.item(10, 10, 2)
50
# modifying RED value
>>> img.itemset((10,10,2),100)
>>> img.item(10,10,2)
1002.1.2 获取图像属性
图像属性包括行数,列数和通道数,图像数据类型,像素数等。
- img.shape
- 可以获取图像的形状。 他的返回值是一个包含行数,列数,通道数的元组。(如果图像是彩色的):
注意
如果图像是灰度图像,则返回的元组仅包含行数和列数,因此,过检查这个返回值就可以知道加载的是灰度图还是彩色图。
- img.size
- 返回图像的像素总数
>>> img.size
378000
>>>- img.dtype
- 返回图像的数据类型
>>> img.dtype
dtype('uint8')
>>>注意
img.dtype在调试时非常重要,因为OpenCV-Python代码中的大量错误是由无效的数据类型引起的。
2.1.3 图像的感兴趣区域
有时,我们需要对一幅图像的特定区域进行操作。例如我们要检测一副图像中眼睛的位置,我们首先应该在图像中找到脸,再在脸的区域中找眼睛,而不是直接在一幅图像中搜索。这样会提高程序的准确性和性能。
ROI 也是使用 Numpy 索引来获得的。现在我们选择球的部分并把他拷贝到图像的其他区域。
>>> ball = img[140:170, 165:195]
>>> img[136:166, 50:80] = ball2.1.4 拆分和合并图像通道
有时候我们需要分别处理图像的B,G,R通道,这个时候我们需要将图像拆分为单通道图。还有一些情况,我们需要用单通道图合成BGR图像。
>>> b, g, r = cv2.split(img)
>>> img = cv2.merge((b, g, r))或者
>>> b = img[:, :, 0]假设要将所有红色像素设置为零,则无需先拆分通道。使用 Numpy索引更快:
>>> img[:,:,2] = 0b --- 0;
g --- 1;
r --- 2
注意:
cv.split() 是一个比较耗时的操作。 所以只有在你需要时才这样做。 否则优先使用Numpy索引。
人脸标记
人脸识别原理
? 在检测到人脸并定位面部关键特征点之后,主要的人脸区域就可以被裁剪出来,经过预处理之后,馈入后端的识别算法。识别算法要完成人脸特征的提取,并与库存的已知人脸进行比对,完成最终的分类。
? 人脸识别(Facial Recognition),就是通过视频采集设备获取用户的面部图像,再利用核心的算法对其脸部的五官位置、脸型和角度进行计算分析,进而和自身数据库里已有的范本进行比对,判断出用户的真实身份。
? 作为人脸识别的第一步,人脸检测所进行的工作是将人脸从图像背景中检测出来,由于受图像背景、亮度变化以及人的头部姿势等因素影响使人脸检测成为一项复杂研究内容。
检测定位:检测是判别一幅图像中是否存在人脸,定位则是给出人脸在图像中的位置。
? 定位后得到的脸部图像信息是测量空间的模式,要进行识别工作,首先要将测量空间中的数据映射到特征空间中。采用主分量分析方法,原理是将一高维向量,通过一个特殊的特征向量矩阵,投影到一个低维的向量空间中,表征为一个低维向量,并且仅仅损失一些次要信息。
人脸识别系统采用基于特征脸的主成分分析法(PCA),根据一组人脸训练样本构造主元子空间,检测时,将测试图像投影到 主元空间上,得到一组投影系数,再和各已知的人脸图像模式比较,从而得到检测结果。
人脸检测的实现
在搜索“github opencv”,在 “opencv/data/haarcascades” 目录下可以看到各种各样的特征分类器(xml文件),从文件名上可以轻易区分出分类器的用途,如 “haarcascadesfrontalface_default.xml” 是脸部正面特征分类器,它是我们用python实现人脸检测的关键。
图片中人脸的检测
import cv2
#加载图片
img = cv2.imread("./img/img_remark.jpg")
#转换成灰度,提高计算速度
gray=cv2.cvtColor(img, cv2.COLOR_BGR2GRAY)
# 加载Haar特征分类器
face_cascade = cv2.CascadeClassifier("./data/haarcascade_frontalface_default.xml")
#探检测图片中的人脸
faces = face_cascade.detectMultiScale(
gray, # 要检测的图像
scaleFactor=1.15, # 图像尺寸每次缩小的比例
minNeighbors=3, # 一个目标至少要被检测到3次才会被标记为人验
minSize=(5, 5)) # 目标的最小尺寸
# 为每个人脸输制矩形框
for (x, y, w, h) in faces:
cv2.rectangle(img,(x, y),(x+w, y+h), (0, 255, 0), 2)
cv2.imshow('img', img)
cv2.waitKey(0)
cv2.destroyAllWindows()? 上图是python实现人脸检测的完整代码,第1行引入 OpenCV 库;第4行使用 imread() 函数加载待检测的图片,第7行将图片转换成灰度以降低图像运算时间;第10行加载脸部正面特征分类器;第13行调用detectMultiScale( )函数对灰度图像进行面部检测,该函数中除了第一个之外其它参数都是非必需的,这些参数可以用来调节检测的精度;第21行在所有检测出来的所有人脸位置绘制矩形框。
捕获摄像头实时监测人脸:
import cv2
cap = cv2.VideoCapture(0)
face_cascade = cv2.CascadeClassifier('./data/haarcascade_frontalface_default.xml') # 加载人脸特征库
while True:
ret, frame = cap.read() # 读取一帧的图像
# gray = cv2.cvtColor(frame, cv2.COLOR_BGR2GRAY) # 转灰
faces = face_cascade.detectMultiScale(
frame,
scaleFactor=1.15,
minNeighbors=5,
minSize=(5, 5)) # 检测人脸
for(x, y, w, h) in faces:
cv2.rectangle(frame, (x, y), (x+w, y+h), (0, 255, 0), 2) # 用矩形圈出人脸
cv2.imshow('Face Recognition', frame)
if cv2.waitKey(1) & 0xFF == ord('q'):
break
cap.release() # 释放摄像头
cv2.destroyAllWindows()存取视频人脸检测
#读取并且显示视屏,框出检测到的人脸
import cv2
cascPath = "./data/haarcascade_frontalface_default.xml"
faceCascade = cv2.CascadeClassifier(cascPath)
# 打开视频捕获设备
cap = cv2.VideoCapture('./video/output.avi')
while True:
if not cap.isOpened():
print('Unable to load camera.')
sleep(5)
pass
# 读视频帧
ret, frame = cap.read()
# 转为灰度图像
gray = cv2.cvtColor(frame, cv2.COLOR_BGR2GRAY)
print(gray)
# 调用分类器进行检测
faces = faceCascade.detectMultiScale(
gray,
scaleFactor=1.1,
minNeighbors=5,
minSize=(200, 200)
# flags=cv2.CV_HAAR_SCALE_IMAGE
)
# 画矩形框
for (x, y, w, h) in faces:
cv2.rectangle(frame, (x, y), (x+w, y+h), (0, 255, 0), 2)
# 显示视频
cv2.resizeWindow('Video', 500, 500)
cv2.imshow('Video', frame)
if cv2.waitKey(60) & 0xFF == ord('q'):
break
# 关闭摄像头设备
cap.release()
# 关闭所有窗口
cv2.destroyAllWindows()人脸特征点检测
1 Dlib安装
pip install xxx.whl2 基于dlib库人脸特征提取
基于dlib库对人脸特征进行提取,在视频流中抓取人脸特征、并保存为64x64大小的图片文件。
注意的是:因为我们后面会对人脸数据集进行训练识别,因此,这一步非常重要。
- 光线——曝光和黑暗图片因手动剔除
- 摄像头的清晰度也比较重要——在哪台笔记本识别,就要在那台笔记本做数据集采集,我用了同学在其他笔记本采取的数据,因为电脑配置,在后面的训练中出现不能识别或错误识别的情况,因此,尽量同一设备——采取数据集和做人脸识别。
3 Dlib人脸特征检测原理
(1)提取特征点
获取特征数据集
根据数据集,模型----训练----》68个特征数据
- (3)计算特征数据集的欧氏距离作对比
4 人脸识别流程
人脸识别是由一系列的几个相关问题组成的:
- 首先找到一张图片中的所有人脸。
- 对于每一张脸来说,无论光线明暗或面朝别处,它依旧能够识别出是同一个人的脸。
- 能够在每一张脸上找出可用于他人区分的独特之处,比如眼睛多大,脸有多长等等。
- 最后将这张脸的特点与已知所有人脸进行比较,以确定这个人是谁。
(1) 找出所有的面孔
很显然在我们在人脸识别的流程中得首先找到图片中的人脸。我们在使用手机或相机拍照时都会有人像模式,它能轻松的检测出人脸的位置,帮助相机快速对焦。
我们得感谢 保罗·比奥拉(Paul Viola)和迈克尔·琼斯(Michael Jones)在2000年发明了一种能够快速在廉价相机上运行的人脸检测方法,人脸检测在相机上的应用才成为主流。然而现在我们有更可靠的解决方案HOG(Histogram of Oriented Gradients)方向梯度直方图,一种能够检测物体轮廓的算法。
首先,我们把图片灰度化,因为颜色信息对于人脸检测而言没什么用。
我们分析每个像素以及其周围的像素,根据明暗度画一个箭头,箭头的指向代表了像素逐渐变暗的方向,如果我们重复操作每一个像素,最终像素会被箭头取代。这些箭头被称为梯度(gradients),它们能显示出图像从明亮到黑暗流动的过程。
分析每个像素对我们来说有点不划算,因为它太过细节化了,我们可能会迷失在像素的海洋里,我们应该从更高的角度观察明暗的流动。
为此我们将图像分割成16x16像素的小方块。在每个小方块中,计算出每个主方向有多少个剃度(有多少指向上,指向右上,指向右等)。然后用指向性最强的那个方向箭头来代替原来那个小方块。
最终结果,我们把原始图像转换成一个非常简单的HOG表达形式,它可以很轻松的捕获面部的基本结构。
为了在HOG图像中找到脸部,我们需要做的是,与已知的一些HOG图案中,看起来最相似的部分。这些HOG图案都是重其他面部训练数据中提取出来的。
(2) 脸部的不同姿势
我们已经找出了图片中的人脸,那么如何鉴别面朝不同方向的人脸呢?
对于电脑来说朝向不同的人脸是不同的东西,为此我们得适当的调整扭曲图片中的人脸,使得眼睛和嘴总是与被检测者重叠。
为了达到目的我们将使用一种面部特征点估计(face landmark
estimation)的算法。其实还有很多算法都可以做到,但我们这次使用的是由瓦希德·卡奇米(Vahid Kazemi)和约瑟菲娜·沙利文(Josephine
Sullivan)在 2014 年发明的方法。
这一算法的基本思路是找到68个人脸上普遍存在的点(称为特征点, landmark)。

- 下巴轮廓17个点 [0-16]
- 左眉毛5个点 [17-21]
- 右眉毛5个点 [22-26]
- 鼻梁4个点 [27-30]
- 鼻尖5个点 [31-35]
- 左眼6个点 [36-41]
右眼6个点 [42-47] - 外嘴唇12个点 [48-59]
- 内嘴唇8个点 [60-67]
有了这68个点,我们就可以轻松的知道眼睛和嘴巴在哪儿了,后续我们将图片进行旋转,缩放和错切,使得眼睛和嘴巴尽可能的靠近中心。
现在人脸基本上对齐了,这使得下一步更加准确。
(3)给脸部编码
1:1
1:N
我们还有个核心的问题没有解决, 那就是如何区分不同的人脸。
最简单的方法就是把我们第二步中发现的未知人脸与我们已知的人脸作对比。当我们发现未知的面孔与一个以前标注过的面孔看起来相似的时候,就可以认定他们是同一个人。
我们人类能通过眼睛大小,头发颜色等等信息轻松的分辨不同的两张人脸,可是电脑怎么分辨呢?没错,我们得量化它们,测量出他们的不同,那要怎么做呢?
实际上,对于人脸这些信息很容易分辨,可是对于计算机,这些值没什么价值。实际上最准确的方法是让计算机自己找出他要收集的测量值。深度学习比人类更懂得哪些面部测量值比较重要。
所以,解决方案是训练一个深度卷积神经网络,训练让它为脸部生成128个测量值。
为了确保旋转不变性,会以关键点为中心,以关键点的方向建立坐标轴,不是单独考察单一的这个关键点,而是需要一个邻域。邻域中每个小格的方向代表该像素的梯度方向,长度是梯度模大小,在每个4X4的小块上计算8个方向的梯度方向直方图,统计每个方向的累加值,形成一个种子点。David G.Lowe建议对每个关键点使用4X4=16个种子点进行描述,每个种子点包含8个方向信息,所以一个关键点就会产生16X8=128维的信息,形成128维的SIFT特征向量。
每次训练要观察三个不同的脸部图像:
- 加载一张已知的人的面部训练图像
- 加载同一个人的另一张照片
- 加载另外一个人的照片
然后,算法查看它自己为这三个图片生成的测量值。再然后,稍微调整神经网络,以确保第一张和第二张生成的测量值接近,而第二张和第三张生成的测量值略有不同。
我们要不断的调整样本,重复以上步骤百万次,这确实是个巨大的挑战,但是一旦训练完成,它能攻轻松的找出人脸。
庆幸的是 OpenFace 上面的大神已经做完了这些,并且他们发布了几个训练过可以直接使用的网络,我们可以不用部署复杂的机器学习,开箱即用,感谢开源精神。
这128个测量值是什么?
其实我们不用关心,这对我们也不重要。我们关心的是,当看到同一个人的两张不同照片时,我们的网络需要能得到几乎相同的数值。
(4) 从编码中找出人的名字
最后一步实际上是最简单的一步,我们需要做的是找到数据库中与我们的测试图像的测量值最接近的那个人。
如何做呢,我们利用一些现成的数学公式,计算两个128D数值的欧氏距离。
这样我们得到一个欧式距离值,系统将给它一个认为是同一个人欧氏距离的阀值,即超过这个阀值我们就认定他们是 同 (失) 一 (散) 个 (兄) 人 (弟)。
人脸识别就这样实现了,来来我们再回顾下流程:
- 使用HOG找出图片中所有人脸的位置。
- 计算出人脸的68个特征点并适当的调整人脸位置,对齐人脸。
- 把上一步得到的面部图像放入神经网络,得到128个特征测量值,并保存它们。
- 与我们以前保存过的测量值一并计算欧氏距离,得到欧氏距离值,比较数值大小,即可得到是否同一个人。
5 68关键点检测
图片
import dlib
import cv2
# 与人脸检测相同,使用dlib自带的frontal_face_detector作为人脸检测器
detector = dlib.get_frontal_face_detector()
# 使用官方提供的模型构建特征提取器
predictor = dlib.shape_predictor('./dat/shape_predictor_68_face_landmarks.dat')
# cv2读取图片
img = cv2.imread("./img/demo.jpg")
# 与人脸检测程序相同,使用detector进行人脸检测 dets为返回的结果
dets = detector(img, 1)
# 使用enumerate 函数遍历序列中的元素以及它们的下标
# 下标k即为人脸序号
# left:人脸左边距离图片左边界的距离 ;right:人脸右边距离图片左边界的距离
# top:人脸上边距离图片上边界的距离 ;bottom:人脸下边距离图片上边界的距离
for k, d in enumerate(dets):
print("dets{}".format(d))
print("Detection {}: Left: {} Top: {} Right: {} Bottom: {}".format(
k, d.left(), d.top(), d.right(), d.bottom()))
# 使用predictor进行人脸关键点识别 shape为返回的结果
shape = predictor(img, d)
# 获取第一个和第二个点的坐标(相对于图片而不是框出来的人脸)
print("Part 0: {}, Part 1: {} ...".format(shape.part(0), shape.part(1)))
# 绘制特征点
for index, pt in enumerate(shape.parts()):
print('Part {}: {}'.format(index, pt))
pt_pos = (pt.x, pt.y)
cv2.circle(img, pt_pos, 1, (255, 0, 0), 2)
#利用cv2.putText输出1-68
font = cv2.FONT_HERSHEY_SIMPLEX
cv2.putText(img, str(index+1),pt_pos,font, 0.3, (0, 0, 255), 1, cv2.LINE_AA)
cv2.imshow('img', img)
k = cv2.waitKey()
cv2.destroyAllWindows()视频
import cv2
import dlib
predictor_path = "./dat/shape_predictor_68_face_landmarks.dat"
#初始化
predictor = dlib.shape_predictor(predictor_path)
#初始化dlib人脸检测器
detector = dlib.get_frontal_face_detector()
#初始化窗口
win = dlib.image_window()
# cap = cv2.VideoCapture('./vid/demo.mp4')
cap = cv2.VideoCapture(0)
while cap.isOpened():
ok, cv_img = cap.read()
if not ok:
break
img = cv2.cvtColor(cv_img, cv2.COLOR_RGB2BGR)#转灰
dets = detector(img, 0)
shapes =[]
for k, d in enumerate(dets):
print("dets{}".format(d))
print("Detection {}: Left: {} Top: {} Right: {} Bottom: {}".format(
k, d.left(), d.top(), d.right(), d.bottom()))
# 使用predictor进行人脸关键点识别 shape为返回的结果
shape = predictor(img, d)
#shapes.append(shape)
#绘制特征点
for index, pt in enumerate(shape.parts()):
print('Part {}: {}'.format(index, pt))
pt_pos = (pt.x, pt.y)
cv2.circle(img, pt_pos, 1, (0,225, 0), 2)
# 利用cv2.putText输出1-68
font = cv2.FONT_HERSHEY_SIMPLEX
cv2.putText(img, str(index+1),pt_pos,font, 0.3, (0, 0, 255), 1, cv2.LINE_AA)
win.clear_overlay()
win.set_image(img)
if len(shapes)!= 0 :
for i in range(len(shapes)):
win.add_overlay(shapes[i])
# win.add_overlay(dets)
cap.release()摄像头捕获
# cap = cv2.VideoCapture('./vid/demo.mp4')
cap = cv2.VideoCapture(0)6 128特征点
? 为了确保旋转不变性,会以关键点为中心,以关键点的方向建立坐标轴,不是单独考察单一的这个关键点,而是需要一个邻域。邻域中每个小格的方向代表该像素的梯度方向,长度是梯度模大小,在每个4X4的小块上计算8个方向的梯度方向直方图,统计每个方向的累加值,形成一个种子点。David G.Lowe建议对每个关键点使用4X4=16个种子点进行描述,每个种子点包含8个方向信息,所以一个关键点就会产生16X8=128维的信息,形成128维的SIFT特征向量。
摘自:https://blog.csdn.net/vonzhoufz/article/details/45647053
本质上人脸识别就是把图像通过映射函数映射到低维空间,并且这个空间里不同人脸是可以被很好的区分的。而这个映射函数现在大多是通过训练深度网络得到。128D特征向量就这映射后空间的维度.
图片
import cv2
import dlib
# face recognition model, the object maps human faces into 128D vectors
img = './img/timg.jpg'
facerec = dlib.face_recognition_model_v1("./dat/dlib_face_recognition_resnet_model_v1.dat")
detector = dlib.get_frontal_face_detector()
predictor = dlib.shape_predictor('./dat/shape_predictor_68_face_landmarks.dat')
img = cv2.imread(img)
# dets = detector(img, 1)
dets = detector(img, 0)
shape = predictor(img, dets[0])
face_descriptor = facerec.compute_face_descriptor(img, shape)
print(face_descriptor)视频
https://www.cnblogs.com/AdaminXie/p/9010298.html
OpenCV 中人脸识别算法
人脸识别的编码步骤
- 训练数据集: 收集要识别的人的面部数据(本例中为面部图像)
- 识别器的训练: 将人脸数据(以及每个人脸的相应名称)输入人脸识别器,使其能够学习。
- 识别: 输入这些人的新面孔,看看你刚训练过的人脸识别器是否识别他们
OpenCV带有内置的人脸识别器,我们要做的就是给它输入人脸数据。这很简单,一旦我们完成了编码,它就会看起来很简单。
OpenCV面部识别器
OpenCV有三个内置的人脸识别器,多亏了OpenCV干净的编码,你可以通过改变一行代码来使用它们中的任何一个。下面是这些人脸识别器的名称和它们的OpenCV调用
1.EigenFaces人脸识别器 - cv2.face.EigenFaceRecognizer_create()
2.FisherFaces人脸识别器 - cv2.face.FisherFaceRecognizer_create()
3.局部二值模式直方图(LBPH)人脸识别器 - cv2.face.LBPHFaceRecognizer_create()
现在我们有三个人脸识别器,但是你知道该用哪一个吗?什么时候用吗?或者哪个更好?接下来我们将深入研究每一个识别器。
qyt538
EigenFaces面部识别器
这个算法考虑的事实是,并不是脸的所有部分都同样重要,或同样有用。当你看一个人的时候,你会通过他独特的特征认出他/她,比如眼睛、鼻子、脸颊、前额以及他们之间的差异。所以你实际上关注的是最大变化的区域(数学上说,这个变化是方差)。例如,从眼睛到鼻子有一个显著的变化,从鼻子到嘴也是如此。当你看多张脸的时候你可以通过看脸的这些部分来比较它们因为这些部分是脸最有用和最重要的组成部分。重要的是,它们捕捉到人脸之间的最大变化,这种变化可以帮助你区分不同的人脸,这就是特征人脸识别系统的工作原理。
EignFaces人脸识别器将所有人的训练图像作为一个整体,并试图提取重要和有用的成分(捕捉最大方差/变化的成分),并丢弃其余的成分。这样,它不仅从训练数据中提取重要的组件,而且通过丢弃不重要的组件来节省内存。它提取的这些重要成分被称为主成分。
我所用主成分,方差,高变化区域,可互换的有用特征等术语,它们的性质基本上是一样的东西。
以下是显示从面部列表中提取的主要组件的图像。

你可以看到,主分量实际上表示面的,这些面被称为特征面,也就是算法的名字。
这就是特征面识别器自身的训练方式(通过提取主成分),它还记录了哪个主成分属于哪个人。在上面的图像中需要注意的一点是特征面算法也将光照作为一个重要的组成部分。
在随后的识别过程中,当你向算法输入新图像时,它也会在该图像上重复同样的过程。它从新映像中提取主组件,并将该组件与它在训练期间存储的组件列表进行比较,并找到匹配最好的组件,并返回与该最佳匹配组件关联的person标签。
轻松+容易,对吧? 下一个比这个更容易。
FisherFaces人脸识别器
该算法是改进后的FisherFaces人脸识别算法。FisherFaces人脸识别器同时查看所有人的训练面,并从所有人的训练面中找到主要的组成部分。通过从所有的人脸中捕获主要的组成部分,你并没有把注意力集中在区分一个人和另一个人的特征上,而是集中在代表整个训练数据中所有人的所有面孔的特征上。
这种方法有一个缺点。 例如,考虑下面的面光照变化。
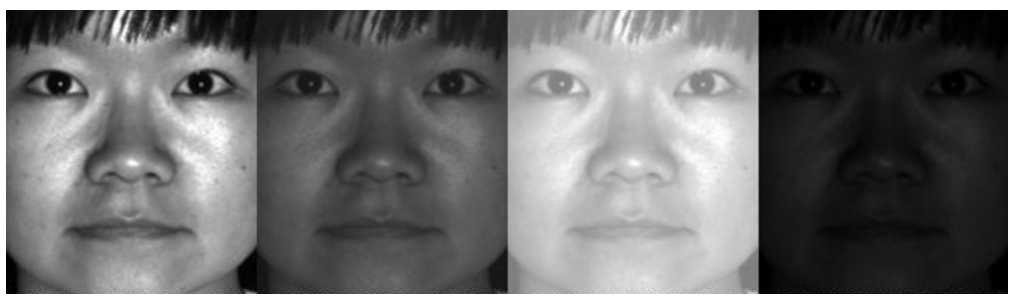
你知道特征面人脸识别器也认为照明是一个重要的组成部分,对吧?想象一个场景,一个人所有的脸都有非常高的亮度变化(非常暗或者非常亮等等)。特征人脸识别者将会考虑这些光照变化非常有用的特征,并且可能会忽略其他人的面部特征,认为这些特征不太有用。现在所提取的特征特征面只代表一个人的面部特征,而不是所有人的面部特征。
如何解决这个问题? 我们可以通过调整EigenFaces人脸识别器来解决这个问题,以便从每个人的脸部分别提取有用的特征,而不是提取所有脸部组合的有用特征。 这样,即使一个人的光照变化很大,也不会影响其他人物特征提取过程。 这正是FisherFaces人脸识别器算法的功能。
Fisherfaces算法不是提取表示所有人员所有面部的有用特征,而是提取可区分一个人和另一个人的有用特征。 通过这种方式,一个人的特征不会占据主导地位(被认为是更有用的特征)而其他人则具有区分一个人和另一个人的特征。
下面是使用Fisherfaces算法提取的特征的图像。
Fisher Faces

你可以看到提取的特征实际上代表了面孔,这些面被称为Fisher faces,因此算法的名称。
这里需要注意的一点是,Fisherfaces人脸识别器只会阻止一个人的特征凌驾于另一个人的特征之上,但它仍然认为光照变化是有用的特征。我们知道光照变化不是一个有用的特征来提取,因为它不是真正的脸的一部分。那么,该怎么摆脱这个照明问题?这就是我们的下一个人脸识别器锁解决的问题。
局部二值模式直方图(LBPH)人脸识别器
我们知道Eigenfaces和Fisherfaces都受光线影响,在现实生活中,我们无法保证完美的光照条件。 LBPH人脸识别器是克服这个缺点的一种改进。
这种想法是不看整个图像,而是查找图像的局部特征。 LBPH算法试图找出图像的局部结构,并通过比较每个像素与其相邻像素来实现。
取一个3x3的窗口,每移动一个图像(图像的每个局部),将中心的像素与相邻像素进行比较。强度值小于或等于中心像素的邻域用1表示,其它邻域用0表示。然后你以顺时针的顺序读取3x3窗口下的0/1值,你会得到一个像11100011这样的二进制模式,这个模式在图像的特定区域是局部的。在整个图像上这样做,就会得到一个局部二进制模式的列表。
LBP标签
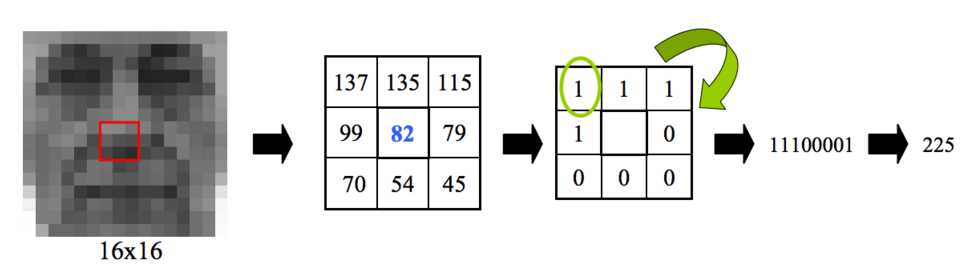
现在你明白为什么这个算法的名字中有局部二进制模式? 因为你得到一个局部二进制模式列表。 现在你可能想知道,LBPH的直方图部分呢? 在获得局部二进制模式列表后,您可以使用二进制到十进制转换将每个二进制模式转换为十进制数(如上图所示),然后对所有这些十进制值进行直方图制作。 样本直方图是像下面这样的。
样本直方图
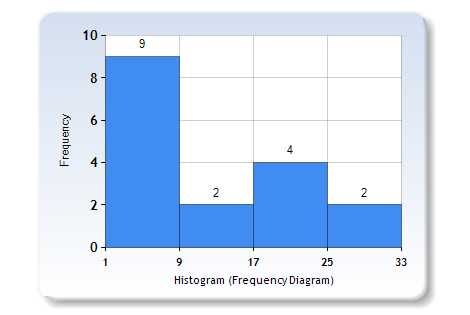
我猜这回答了直方图部分的问题。所以最终你会得到训练数据集中每个人脸图像的一个直方图,这意味着如果训练数据集中有100个图像,那么LBPH会在训练后提取100个直方图,并储存起来以便以后识别。记住,算法也会跟踪哪个直方图属于哪个人。
在识别后期,当您将新图像送入识别器进行识别时,它将生成新图像的直方图,将该直方图与其已有的直方图进行比较,找到最佳匹配直方图并返回与该最佳匹配关联的人员标签 匹配直方图。
下面是一张脸和它们各自的局部二进制模式图像的列表。您可以看到,LBP图像不受光照条件变化的影响。
局部人脸

理论部分已经结束,现在是编码部分!准备好开始编写代码了吗?那我们开始吧。
使用OpenCV编码人脸识别
本教程中的人脸识别过程分为三个步骤。
1、准备训练数据:在这一步中,我们将读取每个人/主体的训练图像及其标签,从每个图像中检测人脸并为每个检测到的人脸分配其所属人员的整数标签。
2、训练人脸识别器:在这一步中,我们将训练OpenCV的LBPH人脸识别器,为其提供我们在步骤1中准备的数据。
3、测试:在这一步中,我们会将一些测试图像传递给人脸识别器,并查看它是否能够正确预测它们
编程工具:
注:Numpy使Python中的计算变得容易。 除此之外,它还包含一个强大的N维数组实现,我们将使用它来将数据作为OpenCV函数的输入。
导入必需的模块
在开始实际编码之前,我们需要导入所需的编码模块。 所以让我们先导入它们。
cv2:是Python的OpenCV模块,我们将用它来进行人脸检测和人脸识别。
os:我们将使用这个Python模块来读取我们的培训目录和文件名。
numpy:我们将使用此模块将Python列表转换为numpy数组,因为OpenCV人脸识别器接受numpy数组。
#导入OpenCV模块
import cv2
#导入os模块用于读取训练数据目录和路径
import os
# 导入numpy将python列表转换为numpy数组,OpenCV面部识别器需要它
import numpy as np测试数据文件夹包含我们将用于在成功培训完成后测试人脸识别器的图像
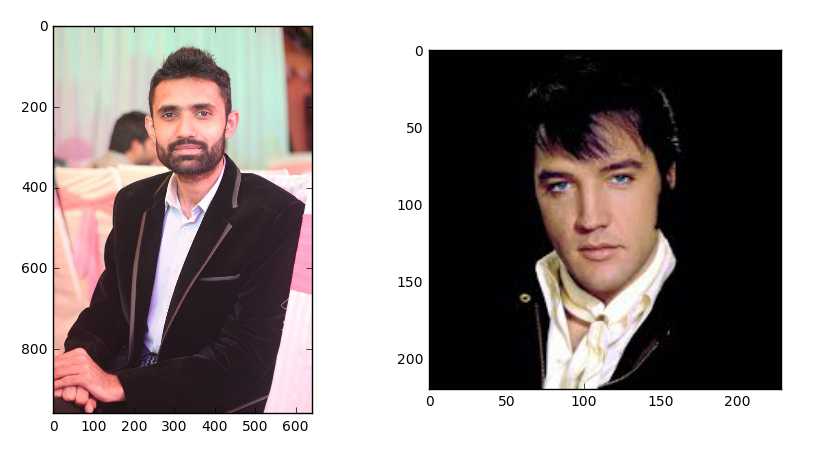
由于OpenCV人脸识别器接受标签为整数,因此我们需要定义整数标签和人物实际名称之间的映射,所以下面我定义了人员整数标签及其各自名称的映射。
注意:由于我们尚未将标签0分配给任何人,因此标签0的映射为空。
#我们的训练数据中没有标签0,因此索引/标签0的主题名称为空
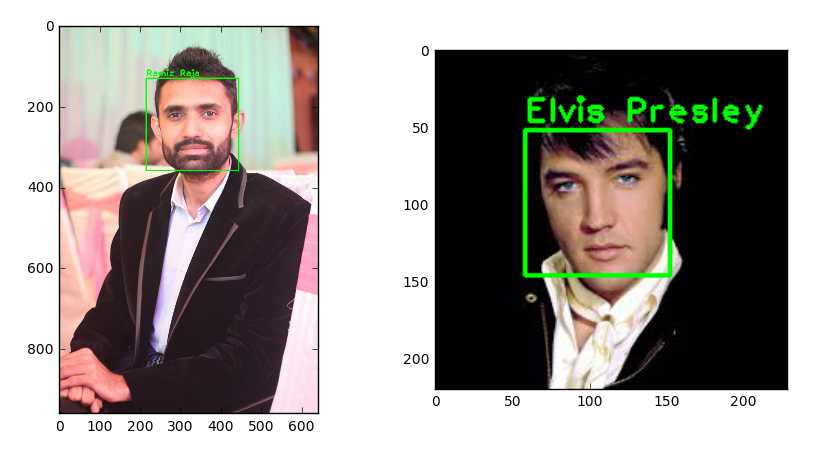
subjects = ["", "Ramiz Raja", "Elvis Presley"]准备训练数据
您可能想知道为什么要进行数据准备,对吗? 那么,OpenCV人脸识别器接受特定格式的数据。 它接受两个矢量,一个矢量是所有人的脸部,第二个矢量是每个脸部的整数标签,因此在处理脸部时,脸部识别器会知道该脸部属于哪个人。
例如,如果我们有两个人和两个图像为每个人。
PERSON-1 PERSON-2
img1 img1
img2 img2然后,准备数据步骤将生成以下面和标签向量。
准备数据步骤可以进一步分为以下子步骤。
1.文件夹中提供的所有主题/人员的文件夹名称。 例如,在本教程中,我们有文件夹名称:s1,s2。
2.对于每个主题,提取标签号码。 文件夹名称遵循格式sLabel,其中Label是一个整数,代表我们已分配给该主题的标签。 因此,例如,文件夹名称s1表示主题具有标签1,s2表示主题标签为2等。 将在此步骤中提取的标签分配给在下一步中检测到的每个面部。
3.阅读主题的所有图像,从每张图像中检测脸部。
4.将添加到标签矢量中的具有相应主题标签(在上述步骤中提取)的每个脸部添加到脸部矢量。
#使用OpenCV用来检测脸部的函数
def detect_face(img):
#将测试图像转换为灰度图像,因为opencv人脸检测器需要灰度图像
gray = cv2.cvtColor(img, cv2.COLOR_BGR2GRAY)
#加载OpenCV人脸检测器,我正在使用的是快速的LBP
#还有一个更准确但缓慢的Haar分类器
face_cascade = cv2.CascadeClassifier('opencv-files/lbpcascade_frontalface.xml')
#让我们检测多尺度(一些图像可能比其他图像更接近相机)图像
#结果是一张脸的列表
faces = face_cascade.detectMultiScale(gray, scaleFactor=1.2, minNeighbors=5);
#如果未检测到面部,则返回原始图像
if (len(faces) == 0):
return None, None
#假设只有一张脸,
#提取面部区域
(x, y, w, h) = faces[0]
#只返回图像的正面部分
return gray[y:y+w, x:x+h], faces[0]我正在使用OpenCV的LBP人脸检测器。 在第4行,我将图像转换为灰度,因为OpenCV中的大多数操作都是以灰度进行的,然后在第8行使用cv2.CascadeClassifier类加载LBP人脸检测器。 在第12行之后,我使用cv2.CascadeClassifier类‘detectMultiScale方法来检测图像中的所有面部。 在第20行中,从检测到的脸部我只挑选第一张脸部,因为在一张图像中只有一张脸部(假设只有一张醒目的脸部)。 由于detectMultiScale方法返回的面实际上是矩形(x,y,宽度,高度),而不是实际的面部图像,所以我们必须从主图像中提取面部图像区域。 所以在第23行我从灰色图像中提取人脸区域并返回人脸图像区域和人脸矩形。
现在您已经有了一个面部检测器,您知道准备数据的4个步骤,那么您准备好编写准备数据步骤了吗?是吗?让我们来做它。
#该功能将读取所有人的训练图像,从每个图像检测人脸
#并将返回两个完全相同大小的列表,一个列表
# 每张脸的脸部和另一列标签
def prepare_training_data(data_folder_path):
#------STEP-1--------
#获取数据文件夹中的目录(每个主题的一个目录)
dirs = os.listdir(data_folder_path)
#列表来保存所有主题的面孔
faces = []
#列表以保存所有主题的标签
labels = []
#让我们浏览每个目录并阅读其中的图像
for dir_name in dirs:
#我们的主题目录以字母's'开头
#如果有的话,忽略任何不相关的目录
if not dir_name.startswith("s"):
continue;
#------STEP-2--------
#从dir_name中提取主题的标签号
#目录名称格式= slabel
#,所以从dir_name中删除字母''会给我们标签
label = int(dir_name.replace("s", ""))
#建立包含当前主题主题图像的目录路径
#sample subject_dir_path = "training-data/s1"
subject_dir_path = data_folder_path + "/" + dir_name
#获取给定主题目录内的图像名称
subject_images_names = os.listdir(subject_dir_path)
#------STEP-3--------
#浏览每个图片的名称,阅读图片,
#检测脸部并将脸部添加到脸部列表
for image_name in subject_images_names:
#忽略.DS_Store之类的系统文件
if image_name.startswith("."):
continue;
#建立图像路径
#sample image path = training-data/s1/1.pgm
image_path = subject_dir_path + "/" + image_name
#阅读图像
image = cv2.imread(image_path)
#显示图像窗口以显示图像
cv2.imshow("Training on image...", image)
cv2.waitKey(100)
#侦测脸部
face, rect = detect_face(image)
#------STEP-4--------
#为了本教程的目的
#我们将忽略未检测到的脸部
if face is not None:
#将脸添加到脸部列表
faces.append(face)
#为这张脸添加标签
labels.append(label)
cv2.destroyAllWindows()
cv2.waitKey(1)
cv2.destroyAllWindows()
return faces, labels我已经定义了一个函数,它将存储培训主题文件夹的路径作为参数。 该功能遵循上述的4个准备数据子步骤。
(step--1)在第8行,我使用os.listdir方法读取存储在传递给函数的路径上的所有文件夹的名称作为参数。 在第10-13行,我定义了标签并面向矢量。
(step--2)之后,我遍历所有主题的文件夹名称以及第27行中每个主题的文件夹名称,我将提取标签信息。 由于文件夹名称遵循sLabel命名约定,所以从文件夹名称中删除字母将给我们分配给该主题的标签。
(step--3)在第34行,我读取了当前被摄体的所有图像名称,并且在第39-66行中我逐一浏览了这些图像。 在53-54行,我使用OpenCV的imshow(window_title,image)和OpenCV的waitKey(interval)方法来显示当前正在传播的图像。 waitKey(interval)方法将代码流暂停给定的时间间隔(毫秒),我以100ms的间隔使用它,以便我们可以查看100ms的图像窗口。 在第57行,我从当前正在遍历的图像中检测出脸部。
(step--4)在第62-66行,我将检测到的面和标签添加到它们各自的向量中。
但是一个函数只能在需要准备的某些数据上调用它时才能做任何事情,对吗? 别担心,我有两张脸的数据。 我相信你至少会认出其中的一个!
#让我们先准备好我们的训练数据
#数据将在两个相同大小的列表中
#一个列表将包含所有的面孔
#数据将在两个相同大小的列表中
print("Preparing data...")
faces, labels = prepare_training_data("training-data")
print("Data prepared")
#打印总面和标签
print("Total faces: ", len(faces))
print("Total labels: ", len(labels))Preparing data...
Data prepared
Total faces: 23
Total labels: 23这可能是最无聊的部分,对吧?别担心,接下来会有有趣的事情发生。现在是时候训练我们自己的人脸识别器了,这样一旦训练它就能识别它所训练的人的新面孔了。读吗?那我们来训练我们的人脸识别器。
训练人脸识别器
我们知道,OpenCV配备了三个人脸识别器。
- 1、EigenFaces人脸识别器 - cv2.face.createEigenFaceRecognizer()
- 2、FisherFaces人脸识别器 - cv2.face.createFisherFaceRecognizer()
- 3、局部二值模式直方图(LBPH)人脸识别器 - cv2.face.createLBPHFaceRecognizer()
我将使用LBPH人脸识别器,但您可以使用您选择的任何人脸识别器。 无论您使用哪个OpenCV的脸部识别器,其代码都将保持不变。 您只需更改一行,即下面给出的面部识别器初始化行。
#创建我们的LBPH人脸识别器
face_recognizer = cv2.face.createLBPHFaceRecognizer()
#或者使用EigenFaceRecognizer替换上面的行
#face_recognizer = cv2.face.createEigenFaceRecognizer()
#或者使用FisherFaceRecognizer替换上面的行
#face_recognizer = cv2.face.createFisherFaceRecognizer()现在我们已经初始化了我们的人脸识别器,也准备了我们的训练数据,现在是时候训练人脸识别器了。我们将通过调用人脸识别器的序列(面向量,标签向量)方法来实现这一点。
#训练我们的面部识别器
face_recognizer.train(faces, np.array(labels))
你有没有注意到,不是直接将标签矢量直接传递给人脸识别器,而是先把它转换成numpy数组?这是因为OpenCV希望标签向量是一个numpy数组。
仍然不满意? 想看到一些行动? 下一步是真正的行动,我保证!
预测
现在是我最喜欢的部分,预测部分。 这是我们真正了解我们的算法是否确实能够识别受过训练的对象脸部的地方。 我们将拍摄两张我们的景点的测试图像,从他们每个人身上检测脸部,然后将这些脸部传递给我们训练有素的脸部识别器,看看它们是否识别它们。
下面是一些实用功能,我们将用它来绘制围绕脸部的边界框(矩形)并将边界名称放在边界框附近。
#函数在图像上绘制矩形
#根据给定的(x,y)坐标和
#给定的宽度和高度
def draw_rectangle(img, rect):
(x, y, w, h) = rect
cv2.rectangle(img, (x, y), (x+w, y+h), (0, 255, 0), 2)
#函数在从图像开始绘制文本
#通过(x,y)坐标。
def draw_text(img, text, x, y):
cv2.putText(img, text, (x, y), cv2.FONT_HERSHEY_PLAIN, 1.5, (0, 255, 0), 2)
第一个函数draw_rectangle根据传入的矩形坐标在图像上绘制一个矩形。 它使用OpenCV的内置函数cv2.rectangle(img,topLeftPoint,bottomRightPoint,rgbColor,lineWidth)绘制矩形。 我们将使用它在测试图像中检测到的脸部周围画一个矩形。
第二个函数draw_text使用OpenCV的内置函数cv2.putText(img,text,startPoint,font,fontSize,rgbColor,lineWidth)在图像上绘制文本。
既然我们有绘图功能,我们只需要调用人脸识别器预测(人脸)方法来测试我们的测试图像上的人脸识别器。 以下功能为我们做了预测。
#this function recognizes the person in image passed
#and draws a rectangle around detected face with name of the
#学科
def predict(test_img):
#制作图像的副本,因为我们不想更改原始图像
img = test_img.copy()
#从图像中检测脸部
face, rect = detect_face(img)
#使用我们的脸部识别器预测图像
label= face_recognizer.predict(face)
#获取由人脸识别器返回的相应标签的名称
label_text = subjects[label]
#在检测到的脸部周围画一个矩形
draw_rectangle(img, rect)
#画预计人的名字
draw_text(img, label_text, rect[0], rect[1]-5)
return img
第6行读取测试图像
第7行从测试图像中检测脸部
第11行通过调用面部识别器的预测(面部)方法来识别面部。 该方法将返回一个标签
第12行获取与标签关联的名称
第16行在检测到的脸部周围绘制矩形
第18行绘制预测主体在面部矩形上方的名称
现在我们已经很好地定义了预测函数,下一步就是在我们的测试图像上实际调用这个函数,并显示这些测试图像以查看我们的人脸识别器是否能正确识别它们。 所以让我们来做。 这就是我们一直在等待的。
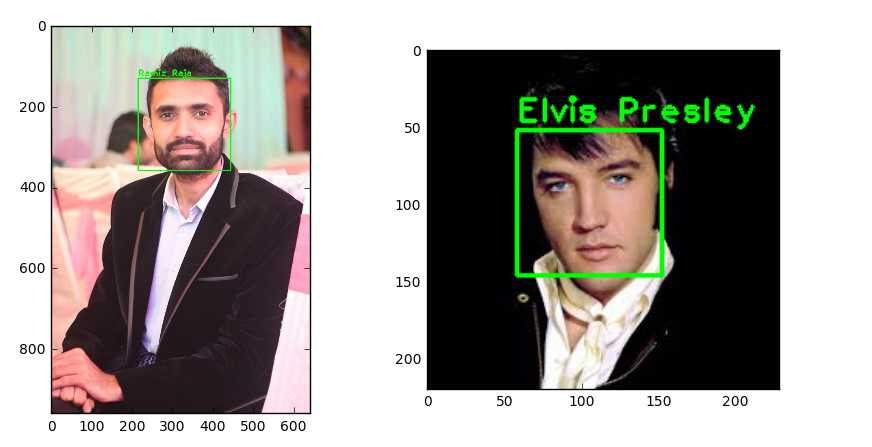
print("Predicting images...")
#加载测试图像
test_img1 = cv2.imread("test-data/test1.jpg")
test_img2 = cv2.imread("test-data/test2.jpg")
#执行预测
predicted_img1 = predict(test_img1)
predicted_img2 = predict(test_img2)
print("Prediction complete")
#显示两个图像
cv2.imshow(subjects[1], predicted_img1)
cv2.imshow(subjects[2], predicted_img2)
cv2.waitKey(0)
cv2.destroyAllWindows()
Predicting images...
Prediction complete
结语
你可以从这个Github下载完整的代码和相关文件 打开GitHub.
人脸识别是一个非常有趣的想法,OpenCV使得它非常简单,易于我们对其进行编码。 只需几行代码即可完成全面工作的人脸识别应用程序,并且我们可以通过一行代码更改在所有三个人脸识别器之间切换。 就这么简单。
尽管EigenFaces,FisherFaces和LBPH人脸识别器都不错,但是使用面向梯度直方图(HOG)和神经网络进行人脸识别还有更好的方法。 因此,更先进的人脸识别算法现在是一个使用OpenCV和机器学习相结合。
以上是关于OpenCV 和 Dlib 人脸识别基础的主要内容,如果未能解决你的问题,请参考以下文章
dlib库包的介绍与使用,opencv+dlib检测人脸框opencv+dlib进行人脸68关键点检测,opencv+dlib实现人脸识别,dlib进行人脸特征聚类dlib视频目标跟踪