机器学习- Sklearn (交叉验证和Pipeline)
Posted tangxiaobo199181
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了机器学习- Sklearn (交叉验证和Pipeline)相关的知识,希望对你有一定的参考价值。
前面一节咱们已经介绍了决策树的原理已经在sklearn中的应用。那么这里还有两个数据处理和sklearn应用中的小知识点咱们还没有讲,但是在实践中却会经常要用到的,那就是交叉验证cross_validation和Pipeline。cross_validation是保证了咱们的模型不受数据分布的影响,因为有些数据可能因为数据的分布很不平均,导致咱们训练的模型虽然在咱们的数据集里面的表现很好,但是在实际中却可能是不一样的情况,cross validation的作用是model checking,而不是model building,无论用哪种方式validation,只是验证根据这些数据训练训练出来的模型能不能用而已,可不可以用这些数据来训练模型而已。而pipeline主要是为了能将模型的训练更加格式化而已,也能规范代码的格式,以后所有的的模型从定义到验证的过程都格式化了。接下来咱们细细的来看看他们具体是个什么玩意儿。
- Cross_validation
在解释交叉验证之前,我先上一个图,如下所示
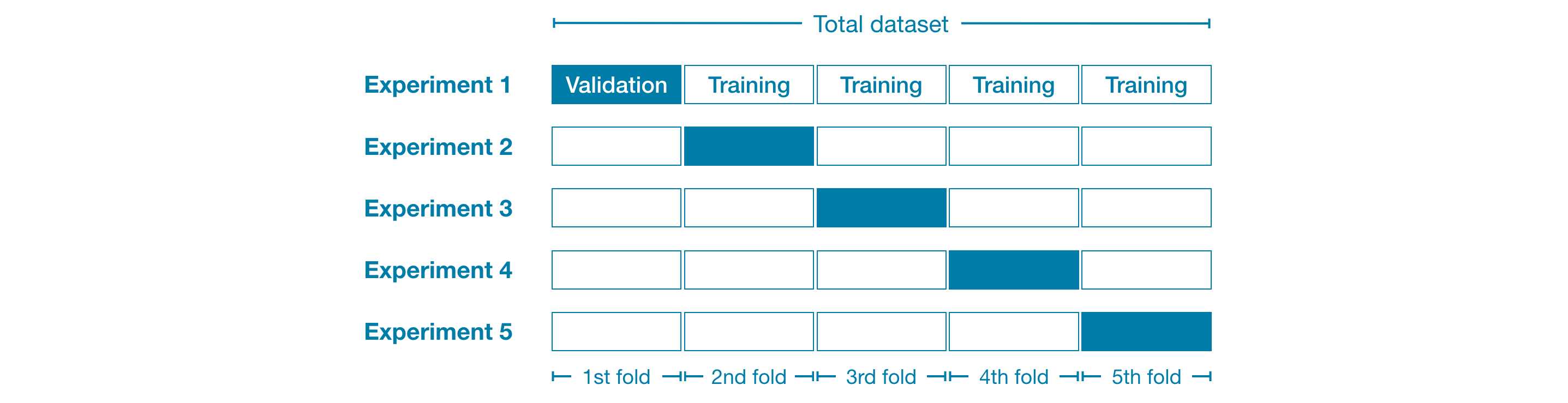
看上面的图,咱们会将咱们的整个dataset分割五次,分别依次将其中的20%的部分作为validation dataset,80%的部分作为training dataset。咱们可以看出咱们会分别训练五个模型,然后分别将各自的validation dataset拿去验证,计算他们的score,然后将这5个score返回装进list中,如果这些list中的元素都差不多的,并且大小都在合理范围之内的话,那么说明这个dataset是整个数据的分布是合理的,并且 可以用这些数据来训练的咱们的模型。记住前面的2个条件缺一不可,如果score的大小都差不多,但是score的数值都很大的话,则说明虽然这个dataset的分布合理,但是这些features并不适合咱们模型,那么咱们就得重新调整模型或者重新feature engineering。如果score的值都不大,在合理范围之内,但是score之间的差值很大,那么就说明咱们这个dataset的数据分布很不合理,训练的模型可能并不具备广发应用的条件,这种情况下咱们得重新permutate咱们的dataset。最后,如果通过cross_validation之后满足了所有的条件,那么咱们最后的最后会用整个dataset来训练咱们的最终模型。所以cross_validation的最终目的还是用来验证咱们的数据和模型的,并不是用来训练模型的。这一点对于刚刚接触交叉验证的同学经常容易混淆。上面像大家展示了什么是cross_validation,那么具体在sklearn中如何应用它呢?麻烦大家直接看下面的代码,一句话解决
from sklearn.model_selection import cross_val_score scores = cross_val_score(estimator=my_pipeline, X=X, y=y, cv=5,scoring = "neg_mean_absolute_error")
这里我来简单解释一下里面的参数,首先它也是来自于sklearn.model_selection这个模块的,estimator代表的是咱们定义的模型(未训练过的),X,y分别代表着training dataset和labels, cv代表的是咱们将这个dataset分成几个部分,最后的scoring是咱们选择哪种计算方式。最后他会返回5个score,并且在scores这个list里面。上面的部分就是cross_validation的解释和具体应用过程。
- Pipeline
咱们前面花了很多的时间讲了feature engineering, 模型训练等等知识,咱们可以看见data preprocess的过程还是很复杂的,例如有missing value handling, categorical data encoding等等这些步骤,然而,每个项目中的数据都是不一样的,这就让咱们的数据进行preprocess的时候会非常复杂,没换一个dataset,咱们就得重新来一遍,非常不方便,这时候聪明的人类就想到了,能不能通过定义一部分参数,来实现把这些繁杂的过程格式化呢???这时候pipeline就出来了。咱们现在先把代码贴出来,然后在一条一条的解释一下pipeline的步骤
#Step1: data preparation import pandas as pd from sklearn.model_selection import train_test_split melb_house_price = pd.read_csv("C:Users angxOneDriveDesktopDATAmelb_data.csv") X = melb_house_price.drop(["Price"],axis = 1) y = melb_house_price.Price X_train_full, X_val_full,y_train,y_val = train_test_split(X,y,train_size=0.8,test_size=0.2,random_state=1) numerical_cols = [col for col in X_train_full.columns if X_train_full[col].dtype in [‘int64‘,‘float64‘]] categorical_cols = [col for col in X_train_full.columns if X_train_full[col].dtype == ‘object‘ and X_train_full[col].nunique()<10] my_cols = numerical_cols+categorical_cols X_train = X_train_full[my_cols].copy() X_val = X_val_full[my_cols].copy() #Step2: define preprocess steps from sklearn.impute import SimpleImputer from sklearn.pipeline import Pipeline from sklearn.preprocessing import OneHotEncoder from sklearn.compose import ColumnTransformer from sklearn.metrics import mean_absolute_error #2.1 define transformer of numerical data numerical_transformer = SimpleImputer(strategy="mean") #missing value handling #2.2 define transformer of categorical data #(Firstly handle the missing value and then secondly encoding the ) categorical_transformer = Pipeline(steps=[ ("Imputer",SimpleImputer(strategy="most_frequent")), ("Onehot",OneHotEncoder(handle_unknown=‘ignore‘))] ) #2.3 data preprocessor preprocessor = ColumnTransformer( transformers = [ ("num", numerical_transformer, numerical_cols), ("cat",categorical_transformer,categorical_cols)] ) #step2.4: model selection and definition from sklearn.ensemble import RandomForestRegressor model = RandomForestRegressor(n_estimators = 100, random_state = 0) #step2.5: bundle preprocessor and model my_pipeline = Pipeline( steps = [ (‘preprocessor‘, preprocessor), (‘model‘,model)] ) #step3: fitting the model my_pipeline.fit(X_train,y_train) #step4: predicts predictions = my_pipeline.predict(X_val) #step5: evaluate the modle print(mean_absolute_error(y_val,predictions))
根据上面的代码,咱们以后所有的代码几乎都可以用上面的框架,第一步肯定就是将training dataset和validation dataset分离出来;第二步就是咱们pipeline,这里也是咱们的重点,首先就是先定义咱们的transform,这里就是声明如何来处理missing value和categorical data,接下来就是声明这些transforms分别用于那些features,并且返回preprocessor;然后定义模型;最后实例化一个pipeline对象,并且将前面定义的模型和preprocessor传递给这个pipeline。接下来的步骤就是fitting,predict,evaluate啦和其他的都一样。所以咱们在这里的重点其实就是第二步,故而以后所有tabular data都可以用上面的结构来进行数据的处理,非常方便简单,不必一个个的单独处理了,只需要定义transforms和preprocessor就可以了。
- 总结
上面已经展示的交叉验证cross_validation和pipeline的两个知识点的一些基本原理和应用。在这里cross_validation的形式和原理是重点,已经cross_validation的作用和原因要理解,至于应用方面就很简单了,重点关注一下里面的一些参数设置就行了。pipeline能够大大的减少咱们数据处理方面的工作量,相当于把数据的preprocessor打包了,并且结构化,具有很高的复用性,这里重点需要了解pipeline的应用的流程以及为什么是这个流程,然后是每个流程的作用。上面就是这一节补充的2个sklearn应用中的小知识点。
以上是关于机器学习- Sklearn (交叉验证和Pipeline)的主要内容,如果未能解决你的问题,请参考以下文章
在 sklearn 中运行 10 倍交叉验证后如何运行 SVC 分类器?