2020/1/25寒假自学——学习进度报告6
Posted limitcm
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了2020/1/25寒假自学——学习进度报告6相关的知识,希望对你有一定的参考价值。
这篇准备尝试RDD的编程操作。
spark运行用户从文件系统中加载数据、通过并行集合(数组)创建RDD,两种都是很方便的操作方式。
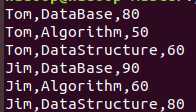
应对实验,我在 创建了一个文本文件。内容包括——
创建了一个文本文件。内容包括——
之后就是尝试创建RDD。
在pyspark中使用——
>>> students=sc.textFile("file:///usr/local/spark/mycode/exp4/chapter5-data1.txt")
处理之后得到——

然后就可以进行我们所需要的操作了,例如统计学生和统计课程——
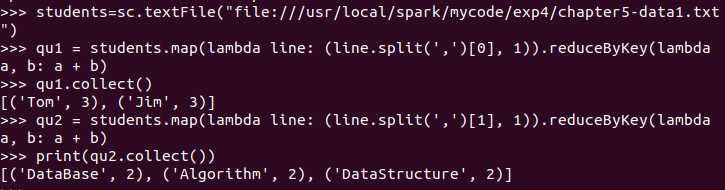
(注意,交互式编程中print只在需要特别打印内容的时候需要,上图可以看到并没有差别,但脚本式编程时需要注意行动操作后需要print)
接下来试试脚本编程。
python的脚本性质使其特别适合这种随用随编的小型应用,这也是我选择先用python来学习spark的原因,也是为了之后机器学习做铺垫。
这种编程方式最好只用集群上的环境,不然会出一大堆问题。想要在集群上编程可以用文本创建python脚本文然后执行,就像教程里面一样。
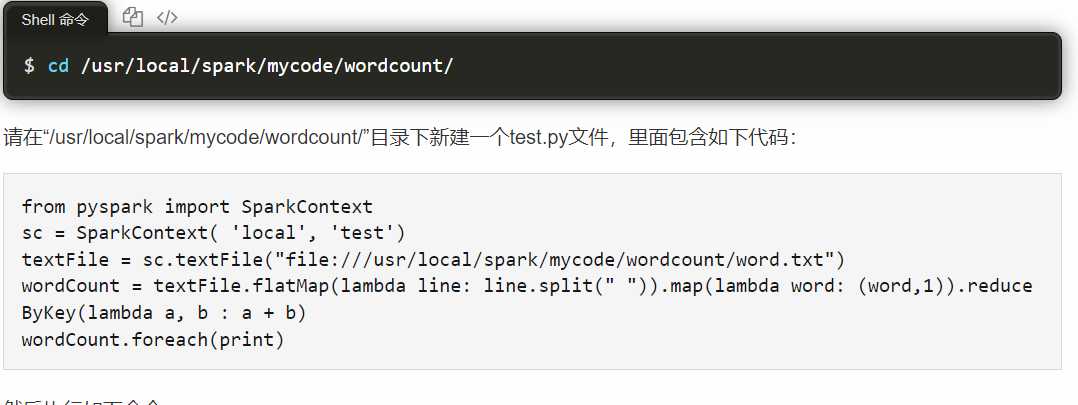
但这样的坏处很明显,缺少IDE的支持很多事情就变得相当麻烦,这样我就用python的虚拟环境把集群里的环境模拟到我的windows里面,这样问题就不会出现了。
于是有了如下代码
from pyspark import SparkContext sc = SparkContext(‘spark://hadoop-master:7077‘, ‘exp4‘) students = sc.textFile(‘file:///usr/local/spark/mycode/exp4/chapter5-data1.txt‘) qu1 = students.map(lambda line: (line.split(‘,‘)[0], 1)).reduceByKey(lambda a, b: a + b) # print(qu1.collect()) qu2 = students.map(lambda line: (line.split(‘,‘)[1], 1)).reduceByKey(lambda a, b: a + b) print(qu2.collect())
运行结果

以上是关于2020/1/25寒假自学——学习进度报告6的主要内容,如果未能解决你的问题,请参考以下文章