NLP的比赛和数据集
Posted xuehuiping
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了NLP的比赛和数据集相关的知识,希望对你有一定的参考价值。
整理了NLP领域的比赛、数据集、模型
| 比赛 | 网站 | 主办方(作者) |
|---|---|---|
| decaNLP | http://decanlp.com/ | Salesforce |
| CLUE | https://github.com/CLUEbenchmark/CLUE | 中文任务基准 |
| GLUE | https://gluebenchmark.com/tasks | |
| BioBERT | https://github.com/dmis-lab/biobert | 生物医学领域的NLP任务 |
| ERNIE | https://github.com/PaddlePaddle/ERNIE | 百度飞桨 |
| ALBERT |
decaNLP
自然语言十项全能多任务挑战
Natural Language Decathlon (decaNLP) 是一个新的基准,要求单独的系统能够完成10项独立的自然语言任务。
- 问答 Stanford Question Answering Dataset (SQuAD 1.1)
- 机器翻译 International Workshop on Spoken Language Translation (IWSLT),
- 自动摘要 CNN/DailyMail (CNN/DM) corpus.
- 自然语言推理 Multi-Genre Natural Language Inference Corpus (MNLI).
- 情感分析 Stanford Sentiment Treebank (SST),
- 语义标签标注 QA-SRL 1.0.
- 关系抽取 QA-ZRE,
- 面向全域的对话 Wizard of Oz (WOZ)
- 语义解析 WikiSQL 【Seq2SQL,https://github.com/salesforce/WikiSQL】
- 常识推理 Modified Winograd Schema Challenge, MWSC)
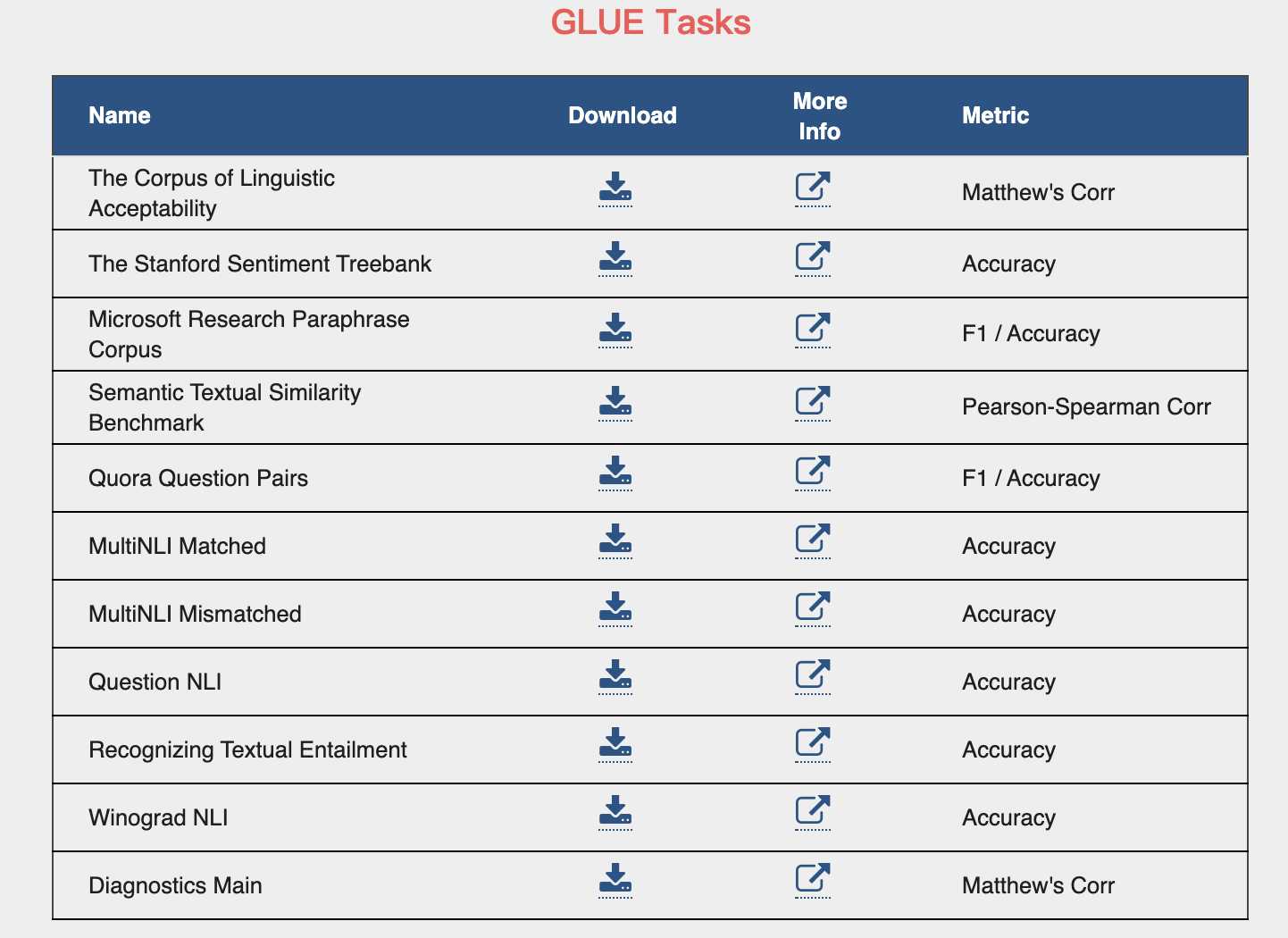
评测-GLUE
CoLA、 SST-2、 MRPC、 STS-B、 QQP、 MNLI-m、 QNLI、 RTE
评测-CLUE
中文任务基准评测CLUE
AFQMC:蚂蚁语义相似度(Acc);
TNEWS:文本分类(Acc);
IFLYTEK:长文本分类(Acc);
CMNLI: 自然语言推理中文版;
COPA: 因果推断;
WSC: Winograd模式挑战中文版;
CSL: 中国科学文献数据集;
模型-BioBERT
https://github.com/dmis-lab/biobert
- NER
命名实体识别 - RE
关系抽取 - QA
问答
模型-ERNIE
https://github.com/PaddlePaddle/ERNIE/blob/develop/README.zh.md
- 自然语言推断 XNLI
- 阅读理解 DuReader、CMRC2018、DRCD
- 命名实体识别 MSRA-NER(SIGHAN2006)
- 情感分析 ChnSentiCorp
- 问答任务 NLPCC2016-DBQA
- 语义相似度 LCQMC、BQ Corpus
模型-ALBERT
模型-TinyBERT
以上是关于NLP的比赛和数据集的主要内容,如果未能解决你的问题,请参考以下文章