14.容器资源需求资源限制及HeapSter
Posted cmxu
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了14.容器资源需求资源限制及HeapSter相关的知识,希望对你有一定的参考价值。
一、容器资源需求及资源限制:
1、概念
Requests:资源需求,最低保障。
Limits:资源限额,硬限制。限制容器无论怎么运行都不能超过的资源阈值
一般来讲,requests <= limits
CPU:可压缩资源。一颗逻辑CPU,即一核。1=1000,millicores
内存:不可压缩资源。Ei,Pi,Ti,Gi,Mi,Ki ==> 以1024为进制。
2、定义资源需求及限制
资源需求和资源限制都是定义在容器上的。
[root@master ~]# kubectl explain pod.spec.containers.resources
使用方法文档:https://kubernetes.io/docs/concepts/configuration/manage-compute-resources-container/
测试:
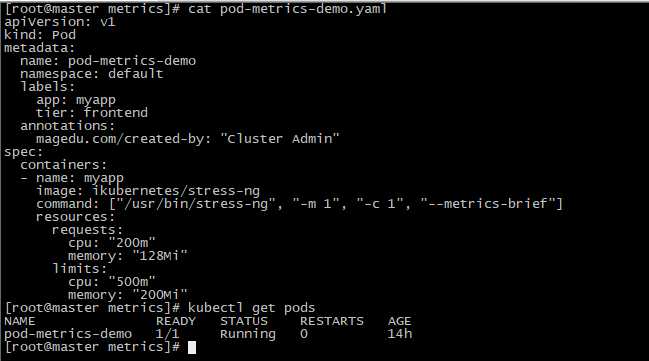
[root@master metrics]# kubectl exec pod-metrics-demo top
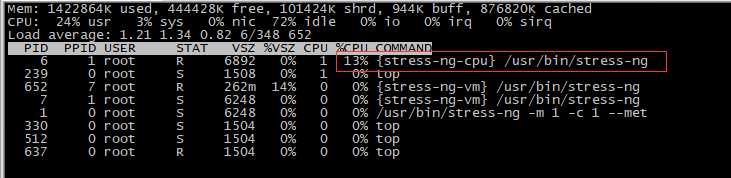
宿主机内核总数是2核,定义的资源limits是0.5m,所以应该是25%,此处13%,原因未明,可能与宿主机是VMVare虚拟机有关。后续再研究。
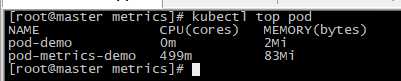
查看,CPU的limit是与定义匹配的,但内存未符合预期,可能压测效果不够。
3、服务质量QoS Class
我们对容器分配了资源限制后,k8s会自动分配一个QoS,叫服务质量
QoS(服务质量)类别(根据设置,自动归类):
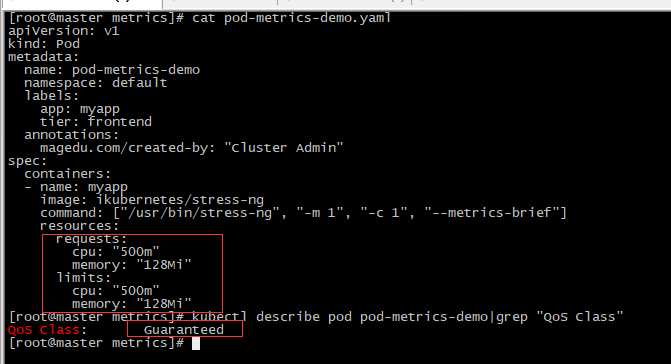
Guranteed:每个容器同时设置了CPU资源,内存资源的requests和limits,并且cpu.limits=cpu.requests和memory.limits=memory.requests
Burstable:至少有一个容器设置了CPU和内存资源的requests属性
BestEffort:没有任何一个容器设置了requests或limits属性。
当资源不够使用时,BestEffort类别的容器会被优先终止;然后还是不够用,就终止Burstable级别的容器(终止是有计算标准的,优先终止已占用量接近limits的容器);
[root@master metrics]# kubectl describe pod pod-metrics-demo|grep "QoS Class"

二、Heapster
目前已经不维护了,此处学习只是帮助理解。目前替代采集工具是metric-server,监控工具是prometheus。
https://github.com/kubernetes-retired/heapster
1、介绍
[root@master metrics]# kubectl top pod pod-metrics-demo # 查看节点或pod的资源使用,但是依赖于Heapster去采集数据。
Heapster:统一的资源使用指标的采集和存储工具。
cAdvisor:专门负责收集当前节点上各Pod,各Container,以及节点级资源的情况。属于kubelet的一个子组件,被整合到kubelet中,默认监听端口:4194。
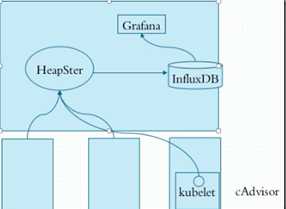
kubelet中的cAdvisor负责收集每个节点上的资源使用情况,然后把信息存储HeapSter中,HeapSter再把数据持久化的存储在数据库InfluxDB中。然后我们再通过Grafana来图形化展示;
一般我们监控的指标包括k8s集群的系统指标、容器指标和应用指标。
默认InfluxDB使用的是存储卷是emptyDir,容器一关数据就没了,所以我们生产要换成glusterfs等存储卷才行。
2、部署
(1)准备工作
wget https://raw.githubusercontent.com/kubernetes-retired/heapster/master/deploy/kube-config/rbac/heapster-rbac.yaml wget https://raw.githubusercontent.com/kubernetes-retired/heapster/master/deploy/kube-config/influxdb/influxdb.yaml wget https://raw.githubusercontent.com/kubernetes-retired/heapster/master/deploy/kube-config/influxdb/heapster.yaml wget https://raw.githubusercontent.com/kubernetes-retired/heapster/master/deploy/kube-config/influxdb/grafana.yaml
[root@master heapster]# sed -i "s/k8s.gcr.io/registry.aliyuncs.com/google_containers/g" * #替换镜像文件
(2)部署influxDB
[root@master heapster]# vim influxdb.yaml
#修改apiVersion为apps/v1 ,因为deployment版本已经属于apps/v1群组。添加selector
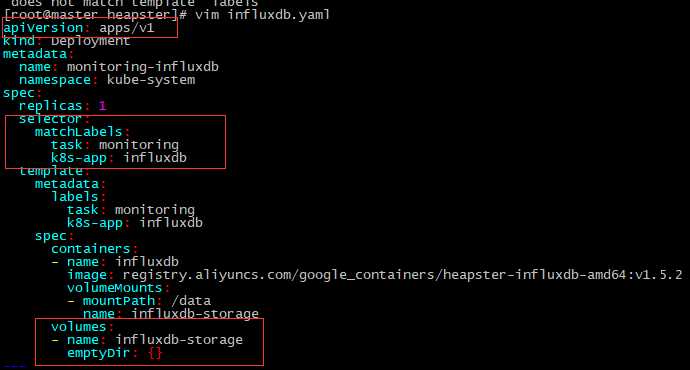
[root@master heapster]# kubectl apply -f influxdb.yaml

influxDB工作正常了。
(3)部署Heapster
[root@master heapster]# kubectl apply -f heapster-rbac.yaml [root@master heapster]# vim heapster.yaml #修改apiVersion为apps/v1 ,因为deployment版本已经属于apps/v1群组。添加selector
[root@master heapster]# kubectl apply -f heapster.yaml
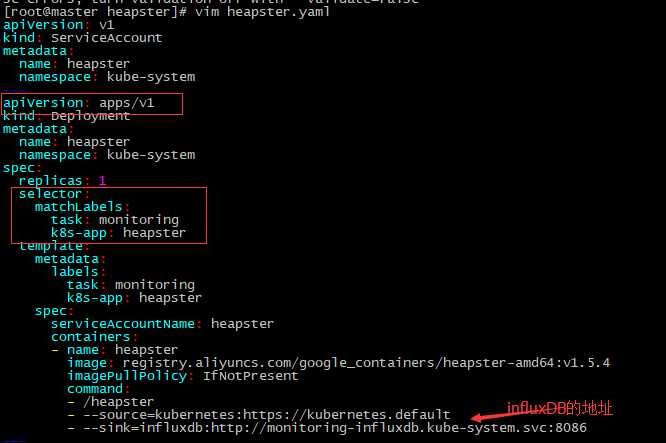
(4)部署grafana
[root@master heapster]# vim grafana.yaml #修改apiVersion为apps/v1 ,因为deployment版本已经属于apps/v1群组。添加selector 。修改Service的类型为NodePort
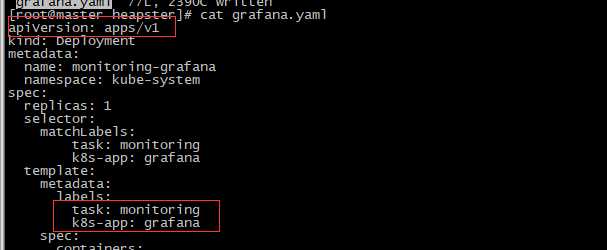
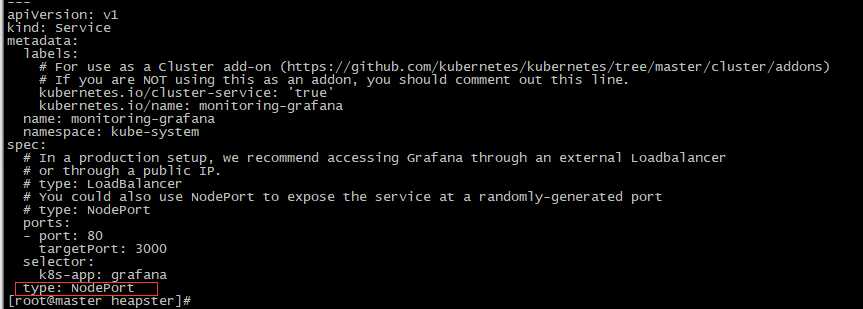
[root@master heapster]# kubectl apply -f grafana.yaml

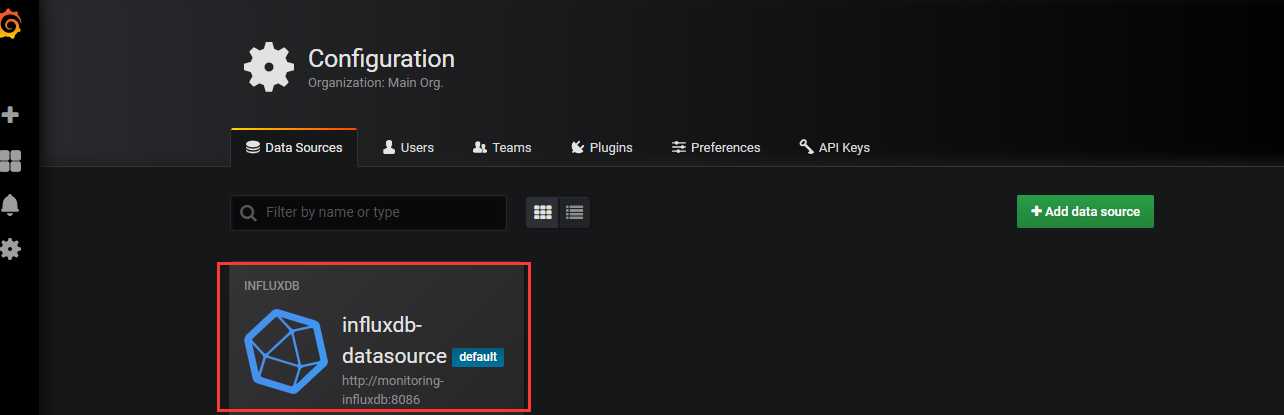
默认使用的数据源就是influxDB,因为部署grafana时是有默认配置的。
3、问题排查
(1)问题一
[root@master heapster]# kubectl top pod

[root@master heapster]# kubectl logs heapster-76467968c9-qpqqf -n kube-system 报错:Error in scraping containers from kubelet:192.168.42.130:10255: failed to get all container stats from Kubelet URL "http://192.168.42.130:10255/stats/container/": Post http://192.168.42.130:10255/stats/container/: dial tcp 192.168.42.130:10255: getsockopt: connection refused

解决方法:
#在heapster.yaml清单文件中进行如下修改:
--source=kubernetes:https://kubernetes.default?kubeletHttps=true&kubeletPort=10250&insecure=true
(2)问题二
报错:Error in scraping containers from kubelet:192.168.42.129:10250: failed to get all container stats from Kubelet URL "https://192.168.42.129:10250/stats/container/": request failed - "403 Forbidden", response: "Forbidden (user=system:serviceaccount:kube-system:heapster, verb=create, resource=nodes, subresource=stats)"
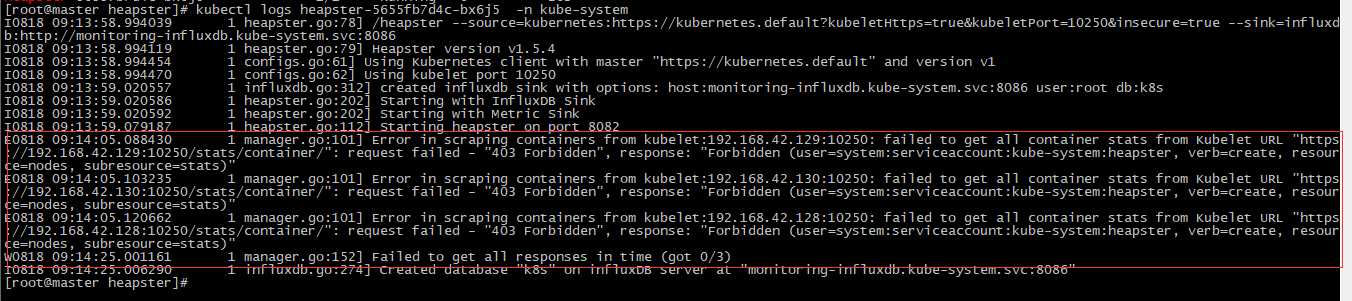
原因分析:
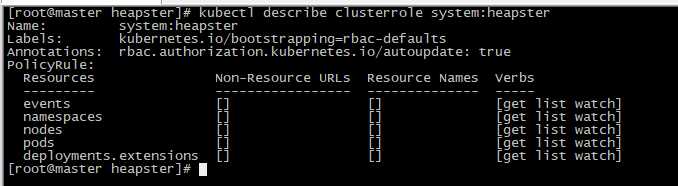
查看ClusterRole: system:heapster的权限,发现的确没有针对Resource: nodes/stats 的create权限
[root@master heapster]# kubectl describe clusterrole system:heapster
[root@master heapster]# kubectl get clusterrole system:heapster -o yaml > heapster_modify.yaml [root@master heapster]# kubectl delete -f heapster_modify.yaml [root@master heapster]# vim heapster_modify.yaml
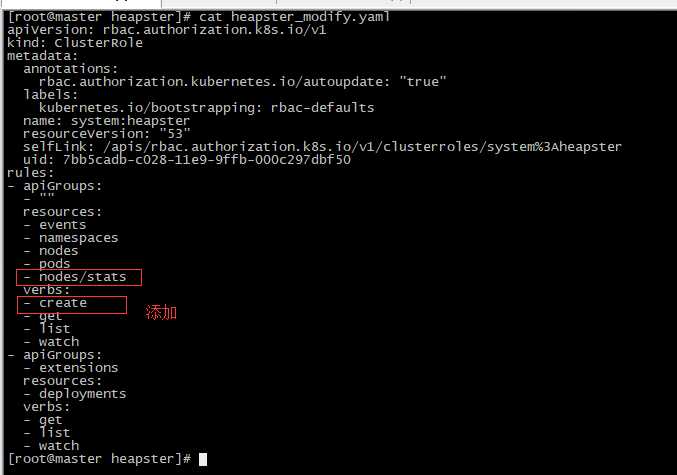
[root@master heapster]# kubectl apply -f heapster_modify.yaml 重新部署Heapster [root@master heapster]# kubectl delete -f heapster.yaml [root@master heapster]# kubectl apply -f heapster.yaml
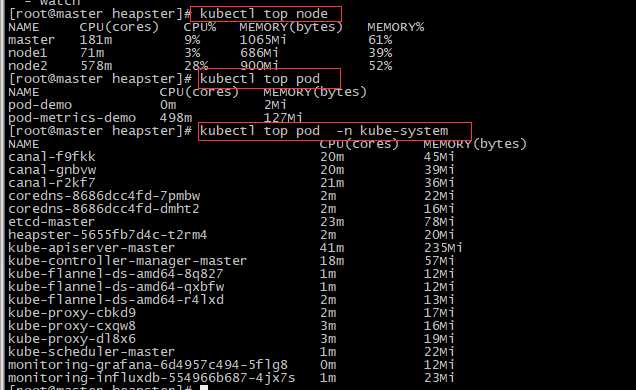
查看Heapster运行日志,没有报错了。Kubectl top也能采集到数据了。
(3)验证
[root@master heapster]# kubectl top node
4、现状
Kubernetes从1.11就废弃了Heapster!!
CPU内存、HPA指标: 改为metrics-server
基础监控:集成到prometheus中,kubelet将metric信息暴露成prometheus需要的格式,使用Prometheus Operator
事件监控:集成到https://github.com/heptiolabs/eventrouter
后续关注基于Heapster的HPA(Horizontal Pod Autoscaling)等操作。
以上是关于14.容器资源需求资源限制及HeapSter的主要内容,如果未能解决你的问题,请参考以下文章