xpath解析
Posted jnhnsnow
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了xpath解析相关的知识,希望对你有一定的参考价值。
解析原理:
实例化etree对象
加载被解析的页面源码数据到该对象
调用etree中的xpath方法结合xpath表达式实现标签定位和内容获取
pip3 install lxml
from lxml import etree
实例化
- etree.parst(本地html文档路径)
- etree.HTML(page_text) #互联网获取的源码数据
xpath表达式:
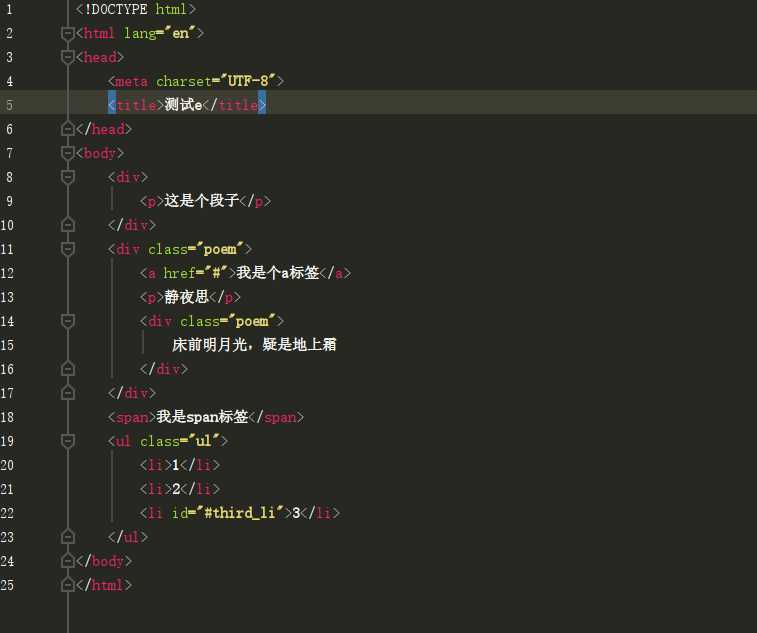
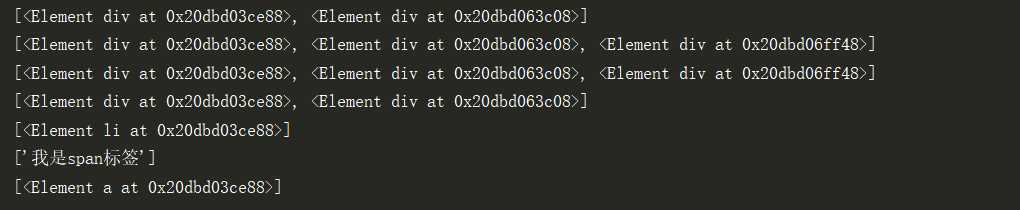
from lxml import etree import requests url = ‘http://www.shicimingju.com/book/sanguoyanyi.html‘ headers = { ‘User-Agent‘: ‘Mozilla/5.0 (Linux; android 6.0; Nexus 5 Build/MRA58N) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/77.0.3865.90 Mobile Safari/537.36‘ } """ 使用lxml.etree.parse()解析html文件,该方法默认使用的是“XML”解析器,所以如果碰到不规范的html文件时就会解析错误,报错代码如下: lxml.etree.XMLSyntaxError: Opening and ending tag mismatch: meta line 3 and head, line 3, column 87 解决办法: 自己创建html解析器,增加parser参数 parser = etree.HTMLParser(encoding="utf-8") """ parser = etree.HTMLParser(encoding="utf-8") tree = etree.parse(‘test.html‘,parser=parser) print(tree.xpath(‘/html/body/div‘)) # /表示从根节点开始定位 一个/表示一个层级 print(tree.xpath(‘/html//div‘)) print(tree.xpath(‘//div‘)) #任意位置定位 #属性定位 div[@attrName = ‘attrvalue‘] print(tree.xpath(‘//div[@class="poem"]‘)) #class为poem的div #索引定位 从1开始索引 print(tree.xpath(‘//li[3]‘)) #取文本 取属性: print(tree.xpath(‘//span/text()‘)) #返回列表 /text()直系文本内容 //text()所有文本内容 print(tree.xpath("//div[@class=‘poem‘]/a/@href")) #/@属性名称 ==》取属性值
以上是关于xpath解析的主要内容,如果未能解决你的问题,请参考以下文章