《Deepening Hidden Representations from Pre-trained Language Models for Natural Language Understandin
Posted demo-deng
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了《Deepening Hidden Representations from Pre-trained Language Models for Natural Language Understandin相关的知识,希望对你有一定的参考价值。
文章名《Deepening Hidden Representations from Pre-trained Language Models for Natural Language Understanding》,2019,单位:上海交大
从预训练语言模型中深化语言表示
摘要:基于Transformer的预训练语言模型已经被证明在语境化语言表征方面是有效的,然而,当前的方法在下游任务的微调过程中都仅仅是利用编码器的最后一层输出信息。那么,只是单纯的利用单一层的输出会限制预训练表征的能力,因此,我们通过在显式隐式表示提取器(HIRE)中融合隐式表示来加深模型所学习的表示,可以自动的吸收最后一层输出进行互补表示,利用RoBERTa作为骨干编码器,提出了预训练语言模型的改进方案。
本方法中包括两个主要的额外组件:1.隐含表征提取器可以动态地学习完整的表征信息,然而最后一层无法有效捕获,所以在编码器旁边放置两层双向GRU,将每一层的输出汇总成一个向量,用于计算贡献分数。2.融合层通过两个不同的功能步骤将HIRE提取的隐藏信息与Transformer最终层的输出进行集成,从而形成一种精细的语境化语言表示。
Hidden Representation Extractor:用于提取Transformer编码器的额外信息,收集到的特征再和编码器的输出结合能够达到信息互补的作用,作者称之为:complementary representation。如下图所示,输出特征A:
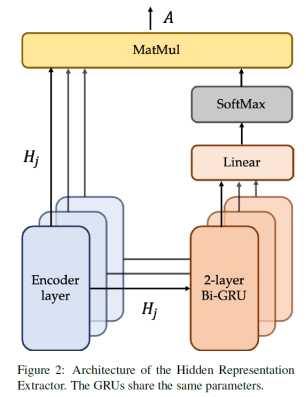
Fusion Layer:融合Transformer编码器和Hidden提取器的特征。对于基础Transformer输出的特征R不是直接结合特征A进入到任务输出层,而是通过特征之间的互补产生特征M:
分别拼接这4个特征,后面两个分别是对应元素上的求和、求点积,每个维度为n*d,拼接起来为n*4d
最后对特征M再接一个双向GRU,相当于再来一次特征融合,增加了特征的存储能力:
作者认为:F才是理想的输入文本的精确通用表示
Output layer:是明确任务输出层,可以根据不同的任务设置。就拿分类任务来说,将F的第一排特征提取出来作为C,再加非线性,输出和类别对应,用如下公式:
对Q映射到类别上,得到一个概率分别预测类别:
实验结果
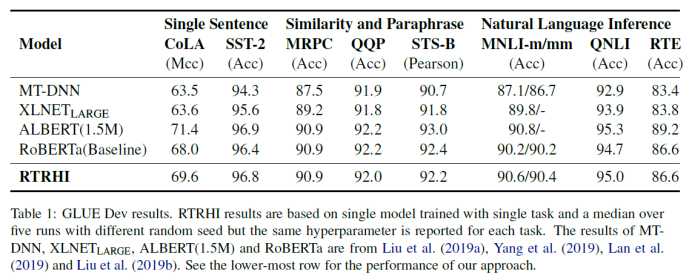
这篇文章是在结构上的优化,通过提高网络的复杂度获取,深化特征提取。如果网络真有那么复杂,运算性能会受到很大影响。
以上是关于《Deepening Hidden Representations from Pre-trained Language Models for Natural Language Understandin的主要内容,如果未能解决你的问题,请参考以下文章