不懂编程?一文学会网络爬虫!
Posted skygxk
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了不懂编程?一文学会网络爬虫!相关的知识,希望对你有一定的参考价值。
爬虫介绍
??市面上有太多有关网络爬虫的教程,有些与代码挂钩,有的算法味道太浓,对那些希望学习技术但又没什么经验的coder很不友好(当然,刚开始谁都是这样),本篇教程就带领这样的你走进网络爬虫的世界。
??好了,下面就让我们来切入正题,什么是网络爬虫?我们来看一下百度的定义:
??网络爬虫(又称为网页蜘蛛,网络机器人,在FOAF社区中间,更经常的称为网页追逐者),是一种按照一定的规则,自动地抓取万维网信息的程序或者脚本。另外一些不常使用的名字还有蚂蚁、自动索引、模拟程序或者蠕虫。
??看完之后,反正我是一脸懵逼。不妨先来看一下网络爬虫能给我们带来什么,对于我来说,最开始接触爬虫就是为了方便地看网络小说。看过的朋友知道,点击网页小说会存在着延迟,而且漫天的广告以及丑陋的阅读界面实在让人难以忍受。那就让我们全部爬取下来,再导入到专门的小说阅读器上,美哉!
??以三少的斗罗大陆为例(当然我是支持正版),百度搜索,然后随便进入一个页面,我们就可以开始阅读了,只是体验不太好。
??同时,我们会发现,我们只需要三个步骤,就可以看到源源不断的小说了,那就是:
- 搜索并打开第一章小说的页面
- 观看小说内容
- 找到下一章的按钮,点击进入
??是不是有点算法的意思了?学过中学数学的都知道,一个循环就可以搞定上面的流程。接下来,让我们细化上面的流程。在此之前,让我们对于网页有一个更深入的了解。
认识网页
??首先我们要了解平时在浏览器上看到的页面是怎么来的。简单来说,当我们输入一个网址或点击一个链接时,就会有一个网络请求从我们的电脑发出,然后互联网就会根据我们的请求把页面信息发到我们电脑上,电脑再经过一些解析最终呈现给我们。
??比如说,电脑接收到的网页信息(源代码)是这样的:
<li> 飞雪连天射白鹿 </li>
<li> 笑书神侠倚碧鸳 </li>
??而经过电脑解析后显示的是这样的:
飞雪连天射白鹿
笑书神侠倚碧鸳
??那怎么样才能看到电脑接收的原本的网页(源代码)呢?先随便打开一个浏览器,进入一个页面,然后按下F12,就可以啦(当然,一般看到的会是很复杂的东西)。
爬取步骤
??刚才说到了三个步骤,在我们了解网页的基本信息后,再把这三个步骤描述地更贴切些。
??原本是:
- 搜索并打开第一章小说的页面
- 观看小说内容
- 找到下一章的按钮,点击进入
??现在是:
- 获取第一章小说的源代码
- 从源代码中找到小说的内容,并保存
- 找到下一章的链接,并获取下一章小说的源代码
- 重复第3步
??现在让我们来一步一步实现上面的步骤:
1. 获取第一章小说的源代码
??好了,到此为止,我们已经可以开始编写网络爬虫了,接下来让我们请出近些年很火的大杀器:Python,相信你无论是从电视上还是互联网上,都对这门语言有所耳闻。不懂编程?不要怕,继续朝下看。
??”不要重复制造轮子“,用荀子的话说就是”君子生非异也,善假于物也“。就像你只需要打开word,点击查找,就可以找到文中你想要的字词,而不是自己真的一个个去找。同样,在Python中,你只要import别人写好的库,就可以使用一些有趣儿的功能。
??切入正题,获取第一章小说的源代码,那我们先找到第一章的链接,当然这个就需要自己百度了,在这里我找到的是这样一个页面:
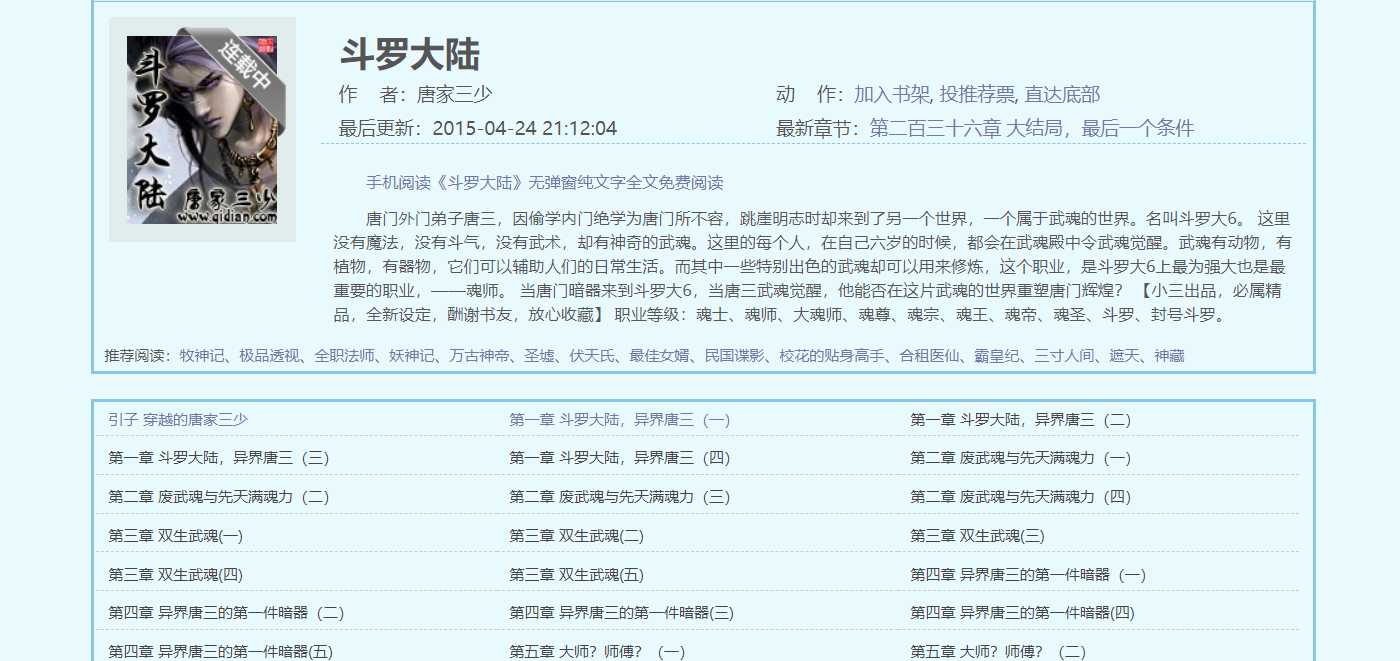
??然后进入第一章,可以在浏览器的最上方看到链接:http://www.xbiquge.la/1/1710/1298266.html
??实现第一步,用Python代码只需两行即可:
import requests
html = requests.get(‘http://www.xbiquge.la/1/1710/1298266.html‘).content.decode(‘utf-8‘)
??import requests 就是我们直接引用别人的”轮子“;requests.get()是我们用别人的”轮子“来获取网页的源代码。
??现在,网页的源代码就存放在html这个变量里啦。
2. 从源代码中找到小说的内容,并保存
??接下来我们将要实现的功能类似于word里的查找,不过是高级一些的查找:匹配一些特定的语段。再用一下刚才的例子:
<li> 飞雪连天射白鹿 </li>
<li> 笑书神侠倚碧鸳 </li>
??我们要从这段源代码中找到需要的信息,显而易见,我们需要查找
??同样的,让我们看一下这个网页里的小说内容在什么和什么之间:
??右键小说的内容部分,点击检查按钮,或者是检查元素按钮,这样我们就能看到小说内容部分的源代码,如图。
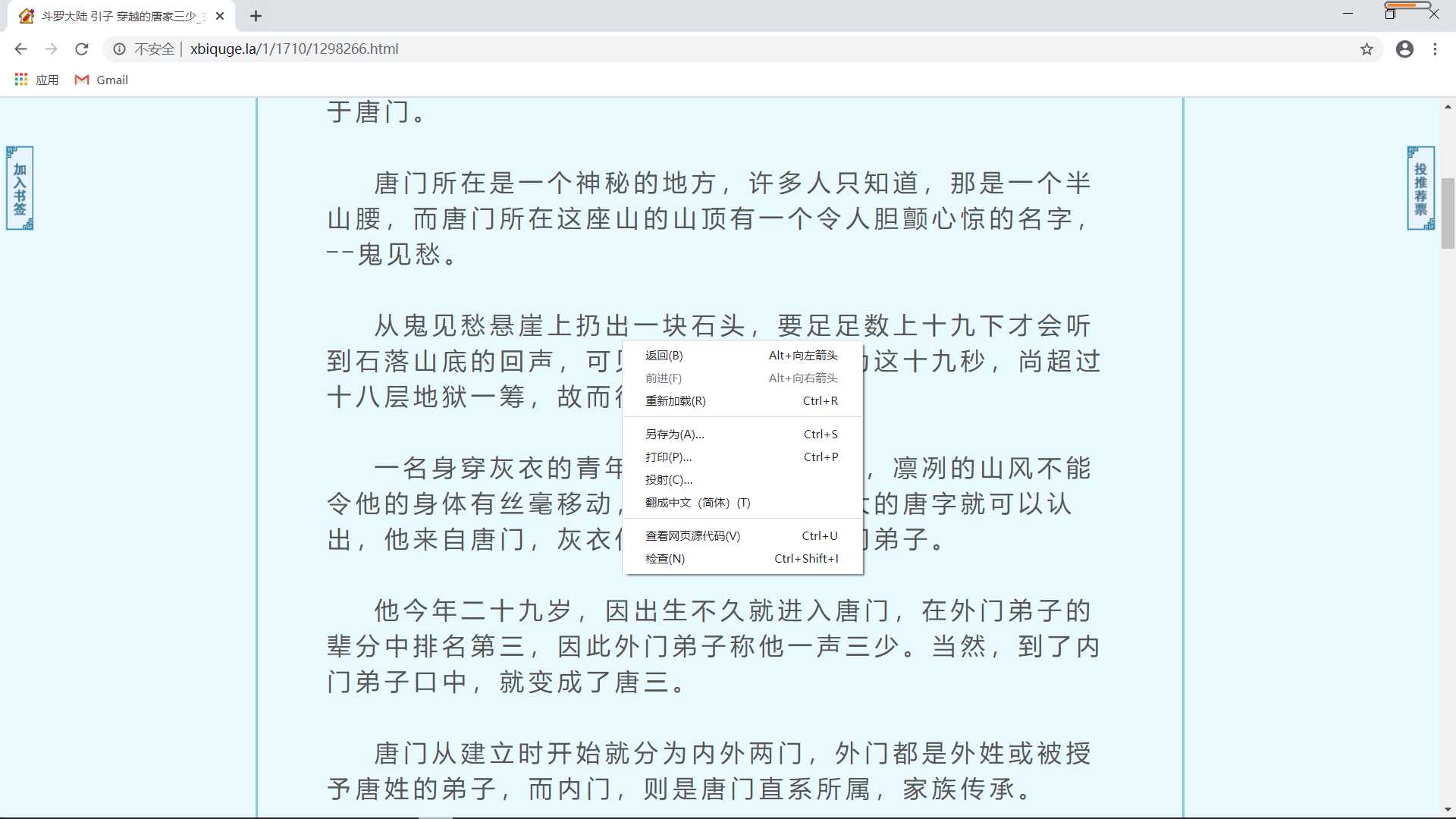
??我们发现内容在<div id="content">和</div>之间,然后双击点开:
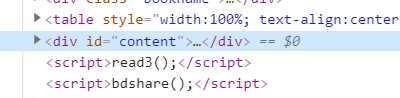
??发现这个标签里面确实是小说内容。那我们怎么获取这个标签里的文字呢?如果word用的比较熟,你会知道在”查找替换“中有个通配符查找:还是刚才的例子:
<li> 飞雪连天射白鹿 </li>
<li> 笑书神侠倚碧鸳 </li>
??在word中的查找面板输入<li>*</li>,就可以查找到所有以<li>开头</li>结尾的语段了。
??我们就是要使用这种方式获取小说的内容。在多种编程语言中,有一种和通配符相似但功能又远远超过通配符的东西:正则表达式,详情请参见正则表达式教程。
??同样,我们也要引用已有的库,来获取网页源代码中<div id="content">和</div>之间的内容:
import re
text = re.search(‘<div id="content">(.*?)</div>‘, html).group(1)
??现在,text里保存的就是源代码html里<div id="content">和</div>之间的内容了。
3. 找到下一章的链接,并获取下一章小说的源代码
??同样,我们在浏览器中找到下一章的按钮,右键检查或检查元素,我们会看到这样的源代码:

→ <a href="/1/1710/1298267.html">下一章</a>
??显而易见,/1/1710/1298267.html 就是下一章的链接,同样使用正则表达式,我们把链接存起来,并获取下一章小说的源代码(还是用到re和requests这两个库哦)。
url = re.search(‘→ <a href="(.*?)">下一章</a>‘, html).group(1)
html = requests.get(‘http://www.xbiquge.la‘ + url).content.decode(‘utf-8‘)
??因为获取到的网址是相对网址,我们要在前面加上网站的域名,才能从外部访问。就比如有个人叫张小明,在自己家的时候爸爸妈妈叫小明就可以,但是在外面就不行了,因为还有李小明,黄小名之类的,要把”域名“加上。
??现在,next_html里保存的就是下一章小说的源代码啦。
4. 重复第3步
??说到重复,那就一定要提到循环,这里我们循环三次,放上全部的代码:
import requests
import re
import io
# 小说保存在这里
novel = ‘‘
html = requests.get(‘http://www.xbiquge.la/1/1710/1298266.html‘).content.decode(‘utf-8‘)
for i in range(3):
text = re.search(‘<div id="content">(.*?)</div>‘, html).group(1)
novel = novel + text
url = re.search(‘→ <a href="(.*?)">下一章</a>‘, html).group(1)
html = requests.get(‘http://www.xbiquge.la‘ + url).content.decode(‘utf-8‘)
# 去除源网页小说中一些杂乱的字符
novel = re.sub(‘[ |
]|<br />‘, ‘‘, novel, 0, re.DOTALL)
novel = re.sub(‘ ‘, ‘
‘, novel, 0, re.DOTALL)
novel = re.sub(‘[
|
]+‘, ‘
‘, novel)
# 保存到本地文件
with open(‘斗罗大陆.txt‘, ‘w‘, encoding=‘utf-8‘) as out:
out.write(novel)
??让我们看看运行后的结果吧!

总结
??当然,这只是第一步,网络爬虫也不仅仅这么简单,如果更加深入探究,我们会用到各种 html 解析库,甚至调用浏览器内核去生成页面信息,再爬取文字或者图片等等。
??你也可以尝试将这个小说爬取工具完善:例如添加爬取每一章的章节名称,生成分章节的信息等等。我也完善了具体代码,有兴趣的小伙伴可以去我的GitHub下载哦(当然你也可以当作一个小工具来使用,它可以爬取各种小说)。
以上是关于不懂编程?一文学会网络爬虫!的主要内容,如果未能解决你的问题,请参考以下文章