DirectX12(D3D12)基础教程(十九)—— 多实例渲染
Posted GamebabyRockSun_QQ
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了DirectX12(D3D12)基础教程(十九)—— 多实例渲染相关的知识,希望对你有一定的参考价值。
1、前言
距离示例:22-MultiInstance-PBR-Sphere 代码上传有近1年时间了,本来应该在去年中秋节前就该把这个示例中的要点分享出来的,只是一入 PBR 之门后那种兴奋与狂热,让我一头扎进了写代码及调试的无尽乐趣中,一发不可收拾,写代码写到几乎停不下来,最终连 IBL 的基本光照示例都写完后,算是松了一口气,暂时停下来,把这段时间的示例及其中运用到的基本方法和技巧梳理一下,分享给各位。
本章教程,重点为大家介绍多实例渲染的方法和技巧。这主要是为了较完整的展示 PBR 金属工作流渲染出的材质球之间的差异,通常这也是向美工显示金属度、粗糙度等核心参数如何控制表面反射效果的最直观的方法。当然多实例渲染本身也是一项非常非常重要的技术,所以我将这个方法单独提出来,作为一篇的教程,尽量聚焦一个或几个知识点,降低学习难度。当然这也是必须掌握的D3D12编程基础技巧之一。
本章示例运行效果如下( 可以键盘方向键等控制上下左右前后查看细致的差别,还有 Pgdown和PgUp键 ):

图中从左到右是从金属到非金属( 对应金属度参数从1.0f ~ 0.04f ),从上到下是粗糙度依次提升( 对应粗糙度参数从0.0f ~ 1.0f),尤其注意最左上角的光滑纯金属球,看上去很黑,其实这就是金属的本质属性,即几乎没有任何漫反射光,只有镜面高光导致的,所以我们只能看到几个高光的光点,所以在纯的只有几个点光源的照射下,是没法完全展示 PBR 金属工作流的惊艳效果的,当然大家不用着急后续我会详细讲解如何做到那种看上去非常惊艳的效果的(主要使用 IBL ,示例代码也已上传各位可以先自行学习)。
当然这里并不是说我们编写的 PBR Shader 有问题,恰恰相反,这充分说明了我们编写的PBR Shader 是完全正确的,因为金属就是几乎没有漫反射光线的,只是我们可能平时都没有注意这个细节。其实如果各位仔细观察过周围环境的话,若真是光滑纯金属的话,在夜晚就只有几个简单光源的环境中也是很不“明亮”的,看上去会更黑,但是镜面反光依然强烈,这是金属固有的光学物理属性使然(金属是可以吸收光的!),我们只是简单的通过近似在计算机中模拟了出来而已!平时只是可能我们因熟视无睹而忽略了这样的细节而已。
而这个金属的物理效果的表现,恰恰也是 PBR 光照渲染与传统的光照渲染不一样的地方,在传统光照中,无论什么材质都会有漫反射光项,所以在传统光照中,很多金属物体因带有漫反射光而表现出浓浓的“塑料风”效果,就是因为这个原因。当然本质上讲这样的简单的描述二者的区别是很不严谨的,但是对我们理解视觉效果和“原理性”掌握 PBR 是很有帮助的。也希望大家能够理解和记住这样的视觉效果差带来的问题,这对我们追求更加真实的渲染效果,或者说分辨渲染效果的“好坏”是很有帮助的。
2、什么是多实例(Multi-Instance)渲染
多实例渲染,本质上就是说将同一份模型(Mesh),按不同参数渲染成多份,每一份被称作一个实例,并且大多数情况下要求每个实例都要有差异。
在游戏中常见这类使用场景,例如在即时战略游戏中,同一种飞机可能需要渲染几百个,它们在外观上几乎没什么差异,或者差异很少,主要是位置不同,运动状态不同,颜色不同等;在休闲游戏中,这可能是一组相同的方块,差异可能只是位置和颜色不同,或者是纹理不同等;在 RPG 游戏中,同一种怪物或敌人就需要在一个较集中的小范围内重复渲染几十份,以表示有几十个敌人或怪物,他们的差异除了之前所说的,最重要的就是动画序列状态不同,有些敌人可能正在移动,有些敌人可能正在挥舞大刀,有些敌人可能已经被主角击中,而有些可能被击倒等等;
再比如,在一些RPG游戏中“大赚特赚”的换皮肤功能,可能就是使用 Multi-Instance 功能为相同的模型换上了不同的纹理而已,让场景中相同的角色人物因为不同玩家的个性需求而表现的很不一样,而很可能玩家就需要为这不同的皮肤花上好几百的货币,这样看上去,Multi-Instance还是一个非常非常有价值的功能!
总之多实例渲染是游戏渲染中常见的技巧和方法,也是最最常用的技术。
3、为什么要多实例(Multi-Instance)渲染
就像刚才所说的,既然这是一个直接就可以“赚钱”的功能,我也就不太想过多的解释为什么了!因为这太显然了。
首先什么是赚钱呢?赚钱就是要获取利润,注意利润不同于收入,而利润就是你卖出商品的收入减去你投入的成本之后剩下的钱,当然你还要交税,剩下的才是你的利润,所以赚钱的核心目标就是降低成本提高利润!
其次,游戏里如何降低成本提高利润呢?那就是想方设法的“氪金”!比如换皮肤,个性化的角色表达,这里的成本在哪里呢?那就在美工加工模型的社会平均劳动时间与你的团队中美工加工模型的劳动时间之间的差异上,如果你的团队产品的时间成本低,那么你推出的“皮肤商品”就会丰富,或者说你的“皮肤商品”质量就会高(相同时间代价条件下),玩家个性需求的满足度就会更高,就更愿意为你的“皮肤”商品买单。如果你不得不为每个个性化的角色都创建一套完整的模型,那么成本将是非常恐怖的,想象一下为了几万人能够同时在线的MMORPG中每个玩家都创建一个不同的模型,需要付出极其高昂的代价,估计即使微软都能被搞破产了。
那么最终如何降低这个成本呢?那就是一套模型,不断变换“纹理、子网格或者动画序列等”(表面上看上去可能就是换了皮肤、换了装备、换了发型头饰、甚至换了动作等等),通过“组合”的方式来满足玩家的需求(这里的组合可以直接理解为数学意义上的组合运算,假设你只有一个美工,创建了一个人物模型,花了大概一周时间创建了10套皮肤、10套装备、10套不同的动作,10套发型,10套脸型,然后呢为了节约成本,你就请他另谋高就了,接着你算算你能大概组合出多少不同的角色?然后假设平均每个玩家大概都能为此付给你100块左右,当然双十一你还可以打折,然后大概有1w左右玩家为此付费,而所有这一切的直接成本不过就是你只需要付给那个美工一周的薪水而已,当然后来你可能良心发现又付给他一笔奖金…ok,扯远了自己脑补吧)。这样最终你的成本就得以极大的压缩,虽然例子可能不太真实,但至少这说明可以赚钱就是 Mutil-Instance 渲染的最大价值。
最终如何实现这冒着“浓浓的金钱的味道”不同“角色”在几乎一样的场景里呢?Multi-Instance! 我想作为程序的你不会想的有多少角色我就循环多少次 Draw Call 每个角色吧?如果那样大概有些玩家大概在看到约100个左右的角色时,基本电脑已经卡死了,他们因此可能会嚷嚷着退钱,然后残酷的骂你开发的是“氪金”游戏,接着你可能连同你的公司一起消失在了慢慢的历史长河之中…从此赚钱再与你无关。
OK! 希望你看明白了我在说啥,如果你不懂政治经济学,而无法明白这里的逻辑的话,那么只需要简单的知道,Multi-Instance 是你的产品能够赚钱的可靠功能之一就行了。别的原因就显得那么的不重要了。所以为了生存,必须掌握这一技能!当然这一切如果再加上 PBR 的视觉 Buff 的加持,那么你就可能赚到更多的钱,所以为什么需要 PBR 也就更加显而易见了!
最终,请记住“没有人需要它,就不会有它!”
4、关于上一篇教程中“菲涅尔”项的补充说明
在前面的教程《DirectX12(D3D12)基础教程(十八)—— PBR基础从物理到艺术(中)》推导漫反射率时我们得到了一个关于漫反射与镜面反射之间基于“能量守恒” 的公式:
f
r
=
k
d
f
l
a
m
b
e
r
t
+
k
s
f
s
p
e
c
u
l
a
r
−
r
e
f
l
e
c
t
i
o
n
式中:
k
d
+
k
s
⩽
1
f_r = k_d f_lambert + k_s f_specular-reflection \\\\[2ex] 式中:k_d + k_s \\leqslant 1
fr=kdflambert+ksfspecular−reflection式中:kd+ks⩽1
并且在《DirectX12(D3D12)基础教程(十八)—— PBR基础从物理到艺术(下)》中讲解基本的 “CooK-Torrance”近似渲染方程时,忘记详细描述上式中的 “
k
s
k_s
ks” 其实就等于该方程中的
F
F
F 函数即 “菲涅尔” 项的值。所以最终在点光源 PBR 示例的完整实现中,关于 “
k
d
k_d
kd” 计算的Shader代码片段如下:
float3 kS = F;
float3 kD = float3( 1.0f,1.0f,1.0f ) - kS;
kD *= 1.0 - g_fMetallic;
Shader代码已经很清楚的表达了:
1、“ k s = F k_s = F ks=F ”,即 “菲涅尔” 系数就是镜面反射系数,当然这种说法很不严谨,更严谨的说法应该说菲涅尔系数是指光被表面反射后其中“方向性”很强的那部分在总反射能量中的占比;
2、“ k d = 1.0 − k s k_d = 1.0 - k_s kd=1.0−ks ”,这就是能量守恒在反射后的光线中的关系,这个很好理解,因为我们假定的表面反射模型中就只有两部分;
3、最后 “ k d k_d kd ” 即漫反射系数根据 “非金属度($ 1 - Metallic )”进行了缩放,当金属度参数“ )”进行了缩放,当金属度参数 “ )”进行了缩放,当金属度参数“Metallic = 1.0 $ ” 时,那么计算后的 “ k d k_d kd ” 就为 0 0 0 ;也既光滑的纯金属球是没有漫反射光的,因为金属会吸收光(其实是因其内部自由电子多的缘故)!这也与本章示例中看到的情况一致。
这样最终短短的 3 行代码就保证了 PBR 在表现金属与非金属材质上的 “正确性” 和便捷性。当然这也是迪士尼公司相关工作人员在进行了大量的观察研究并进行数据分析之后得出的非常棒的经验方程和参数。在此为他们的辛勤而卓有成效的工作表示感谢!
5、Multi-Instance的基本原理
其实从纯技术的角度来说,Multi-Instance 的原理并不难理解,直白的说,本质上它就是可以为一个网格模型(Mesh)指定不同的多组参数进行同时渲染,使的网格被充分复用,从而节约了 Draw Call 的次数,也使得一次提交给显卡的工作量可以达到接近“饱和”的状态,并且这些参数完全由你来控制,对应的每组参数最终生成的模型就可以被称作一个实例。也就是说所有的同一个模型的多个实例只需要一次 Draw Call 调用即可,这也是在 D3D12 异步渲染架构中极力推荐的做法。
当然在 D3D12 中,因为本质上 Draw Call 异步的原因,所以循环调用 Draw Call 在规模不大时也不会有什么太大问题,但是当规模过大时,依然会产生问题。那么具体理解这个问题可以看下图:
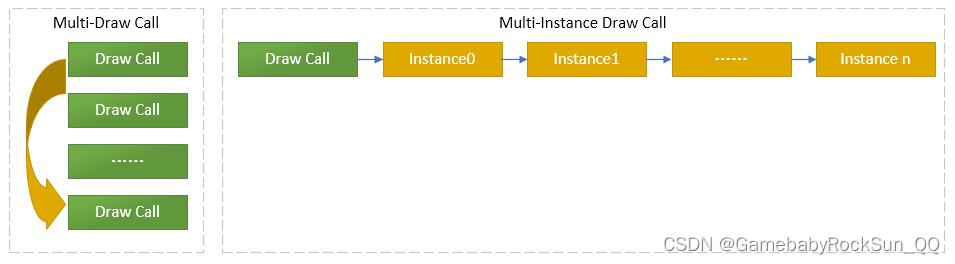
其实这种差别主要是因为GPU可以高度并行的执行命令的架构使然,在 D3D12 中两种方式对于 CPU 侧来说是没有啥影响的,因为 Draw Call 现在只是条命令,并且被以命令列表的方式一次性提交给了 GPU ,而 CPU 不用再等待 GPU 的返回,希望到这里大家已经深刻的理解了 D3D12 中 CPU 和 GPU 可以完全并行的同步执行工作的原理,并且完全理解了 Draw Call 等命令已经变成了异步执行的确切含义!
典型的这些不同实例的参数可以是位置矩阵、缩放矩阵、旋转矩阵或者它们的复合矩阵,还可以是对应的纹理索引数组、或者是一些影响渲染结果的开关参数等,比如透明不透明,动画序列的动画矩阵索引关键帧索引动作索引等等,这样只要有一个模型,就可以渲染出成千上万个不同状态的实例,而这些只需要一个 Draw Call 调用即可!
这不但可以节约 Draw Call 调用的数量,并且可以使 GPU 尽可能的高度饱和的工作,同时系统的整体运行性能也得到了根本上的保障。潜在的通过修改 Multi-Instance 的每个 Instance 的数据,那么就可以简单的控制一组对象呈现不同的状态、外观等,而这几乎不需要变动任何代码,从而极大的降低了耦合度。
6、Multi-Intance的第一步:模型顶点数据与实例数据
在D3D12中,要实现 Multi-Instance 的调用,首先需要确定的是每个 Instance 的状态数据结构,这个完全由程序根据需要来设定,在本章示例中,主要是设定了如下的实例参数:
struct ST_GRS_PER_INSTANCE
XMFLOAT4X4 mxModel2World;
XMFLOAT4 mv4Albedo; // 反射率
float mfMetallic; // 金属度
float mfRoughness; // 粗糙度
float mfAO; //
;
其中第一个参数很好理解,那就是具体到每个小球需要在世界空间中摆放的位置,如果对于更复杂的模型来说,这可能是一系列模型局部坐标系中的变换(缩放->旋转->平移等)复合之后的矩阵。而后续4个参数就是每个小球需要表现的不同的 PBR 材质的参数了,分别为 基础反射率、金属度、粗糙度、和环境遮挡系数(这个参数我们还从来没有介绍过,目前可以简单的将它理解为一个遮光的系数即可)。
当然依照惯例,我们还需要定义 Mesh 顶点自身的数据及扩展的属性,在我们示例中,顶点数据结构定义如下:
struct ST_GRS_VERTEX
XMFLOAT4 m_v4Position; //Position
XMFLOAT4 m_v4Normal; //Normal
XMFLOAT2 m_v2UV; //Texcoord
;
7、Multi-Intance 的第二步:在 PSO 中描述多实例数据结构(元数据)
定义了顶点数据和实例数据后,我们来思考一个问题,那就是实例数据怎么和顶点数据 “组合”?或者更直白的说,这两个数据怎么传入渲染管线中?按照我们之前掌握的技巧,传递顶点数据大家应该已经很熟悉了,那就是按照我们既定的格式准备好所有顶点的数据在一个缓冲区中,然后在创建 PSO 的时候指定我们传入的顶点的数据结构的 “元信息”(元数据)即可。通常这就是描述一个结构体的数组如下:
typedef struct D3D12_INPUT_ELEMENT_DESC
LPCSTR SemanticName;
UINT SemanticIndex;
DXGI_FORMAT Format;
UINT InputSlot;
UINT AlignedByteOffset;
D3D12_INPUT_CLASSIFICATION InputSlotClass;
UINT InstanceDataStepRate;
D3D12_INPUT_ELEMENT_DESC;
当然如果你有过数据库设计的经验的话,理解起这个结构体的话是没什么难度的,这其实就相当于一个“字段”的描述信息而已。因此我也亲切的将这个结构体的数组描述信息称之为 “元数据” 。针对前面的定义的本章示例的顶点结构,其“元数据”描述如下:
D3D12_INPUT_ELEMENT_DESC stIALayoutSphere[] =
// 前三个是每顶点数据从插槽0传入
"POSITION",0, DXGI_FORMAT_R32G32B32A32_FLOAT,0, 0, D3D12_INPUT_CLASSIFICATION_PER_VERTEX_DATA, 0 ,
"NORMAL", 0, DXGI_FORMAT_R32G32B32A32_FLOAT,0,16, D3D12_INPUT_CLASSIFICATION_PER_VERTEX_DATA, 0 ,
"TEXCOORD",0, DXGI_FORMAT_R32G32_FLOAT, 0,32, D3D12_INPUT_CLASSIFICATION_PER_VERTEX_DATA, 0 ,
;
上述记录中顶点的数据结构定义是很清晰了(注意我说了“记录”)。它的含义是说一个 Mesh 中每个顶点数据结构中包含3个字段(注意我又说了“字段”),但其实一个Mesh中又是有成千上万个顶点组成的,而每个 Mesh 只是对应一个实例,那么多实例中的每个实例的“元数据”又该怎么定义呢?
显然,每实例的数据不能紧跟在每顶点数据之后,因为那样每实例的数据就被“笛卡尔积”为每顶点数据了,浪费空间不说,还严重占用显存并影响效率。 根据我们需要实现的多实例渲染的功能需求,那么每实例数据的“元数据”究竟该怎样描述呢?
这就要用到我们在DirectX12(D3D12)基础教程(十七)——让小姐姐翩翩起舞(3D骨骼动画渲染) 系列教程中用到的“多插槽”(Multi-Slot)方法(当然我更愿意将这个说成是技能,希望你已经完全掌握了之前教程中的完整技能树),对于多实例数据的“元数据”使用单独的插槽(Slot)来传入渲染管线,同时在定义每实例数据的“元数据时”指定 D3D12_INPUT_CLASSIFICATION_PER_INSTANCE_DATA 标志,从其名称中的 “ Per Instance Data” 即可猜出其含义,具体的,根据之前我们定义的每实例数据结构,可以对应的描述其“元数据”如下:
D3D12_INPUT_ELEMENT_DESC stIALayoutSphere[] =
// 前三个是每顶点数据从插槽0传入
"POSITION",0, DXGI_FORMAT_R32G32B32A32_FLOAT,0, 0, D3D12_INPUT_CLASSIFICATION_PER_VERTEX_DATA, 0 ,
"NORMAL", 0, DXGI_FORMAT_R32G32B32A32_FLOAT,0,16, D3D12_INPUT_CLASSIFICATION_PER_VERTEX_DATA, 0 ,
"TEXCOORD",0, DXGI_FORMAT_R32G32_FLOAT, 0,32, D3D12_INPUT_CLASSIFICATION_PER_VERTEX_DATA, 0 ,
// 下面的是没实例数据从插槽1传入,前四个向量共同组成一个矩阵,将实例从模型局部空间变换到世界空间
"WORLD", 0, DXGI_FORMAT_R32G32B32A32_FLOAT,1, 0, D3D12_INPUT_CLASSIFICATION_PER_INSTANCE_DATA, 1 ,
"WORLD", 1, DXGI_FORMAT_R32G32B32A32_FLOAT,1,16, D3D12_INPUT_CLASSIFICATION_PER_INSTANCE_DATA, 1 ,
"WORLD", 2, DXGI_FORMAT_R32G32B32A32_FLOAT,1,32, D3D12_INPUT_CLASSIFICATION_PER_INSTANCE_DATA, 1 ,
"WORLD", 3, DXGI_FORMAT_R32G32B32A32_FLOAT,1,48, D3D12_INPUT_CLASSIFICATION_PER_INSTANCE_DATA, 1 ,
"COLOR", 0, DXGI_FORMAT_R32G32B32A32_FLOAT,1,64, D3D12_INPUT_CLASSIFICATION_PER_INSTANCE_DATA, 1 ,
"COLOR", 1, DXGI_FORMAT_R32_FLOAT, 1,80, D3D12_INPUT_CLASSIFICATION_PER_INSTANCE_DATA, 1 ,
"COLOR", 2, DXGI_FORMAT_R32_FLOAT, 1,84, D3D12_INPUT_CLASSIFICATION_PER_INSTANCE_DATA, 1 ,
"COLOR", 3, DXGI_FORMAT_R32_FLOAT, 1,88, D3D12_INPUT_CLASSIFICATION_PER_INSTANCE_DATA, 1 ,
;
从这个完整的输入数据的记录中,可以明确的看出每实例数据与每顶点数据描述之间的差异与相同点,其实重点的就是插槽(Slot)序号和输入数据类型(Identifies the type of data contained in an input slot.)。而第三处不同就是最后一个参数 InstanceDataStepRate (实例数据步进率),这是功能更强的一个参数,它的含义是说,用当前的一份实例的数据,重复绘制多少个实例。当然对于每顶点数据来说这个参数毫无意义,而对于每实例数据来说,当它大于1时,就是表示最终我们绘制的 一个 M e s h 的重复实例总数 = I n s t a n c e D a t a S t e p R a t e × 实例数据个数 一个Mesh 的重复实例总数 = InstanceDataStepRate \\times 实例数据个数 一个Mesh的重复实例总数=InstanceDataStepRate×实例数据个数 。
最终这样的 “元数据” 记录描述为我们带来了极大的灵活性,首先,当我们实际使用多实例绘制时,每个实例的具体参数,是可以按照我们真实的需要自由发挥的,而不必非要像本章教程这里这样的定义,具体需要什么数据都可以在这里自由定义;其次,每个实例数据还可以单独再指定重复的次数,这为很多几乎相同的多个实例绘制提供了极大的便利。
8、Multi-Intance 的第三步:在 Vertex Shader 中接收多实例的数据
定义完顶点以及对应的多实例数据的 “元数据” 后,面临的问题就是在 Vertex Shader 中应该如何来接收并使用这些数据呢?当然顶点数据的使用,我们已经是轻车熟路了。对于多实例数据,根据本章示例代码中定义的“元数据格式”,就需要像下面这样在 Vertex Shader 中接收:
struct VSInput
float4 mv4LocalPos : POSITION;
float4 mv4LocalNormal : NORMAL;
float2 mv2UV : TEXCOORD;
float4x4 mxModel2World : WORLD;
float4 mv4Albedo : COLOR0; // 反射率
float mfMetallic : COLOR1; // 金属度
float mfRoughness : COLOR2; // 粗糙度
float mfAO : COLOR3; // 环境遮挡系数
uint mnInstanceId : SV_InstanceID;
;
上面的结构体定义就是来自于本章示例教程的 Multiple_Instances_VS.hlsl Shader 程序文件中。其中的前三个参数很好理解,需要注意的第一个地方是,第四个参数 mxModel2World 在 Shader 中我们直接使用了 float4x4类型,这相当于 4 个 float4 ,也就是对应我们之前定义的 “元数据” 中语义为 “WORLD” 的连续四个数据。 这里实质上为我们揭示两个具有启发意义的潜在知识:1、PSO 定义中的 D3D12_INPUT_ELEMENT_DESC 结构体记录中的语义需要与Shader中的对应参数语义相对应,当然这应该是已知的知识了,这里只是再次强调一下,方便大家能够更深刻的理解;2、在 D3D12_INPUT_ELEMENT_DESC 结构体记录中定义的数据类型或者说描述的个数不一定非要和Shader中的一一对应,而只需要语义相同,然后加起来的数据大小一致即可;一般我们往往是在D3D12_INPUT_ELEMENT_DESC 结构体记录中使用多条语义相同而顺序连续的多条记录来组成一个Shader中对应的参数或字段,这主要因为在D3D12_INPUT_ELEMENT_DESC 结构体记录中使用的 DXGI 的数据类型没有矩阵等复杂数据类型的对应枚举值引起的。
接着需要注意的第二个地方是,后续的 COLOR0~3 三个字段虽然用了常见的 COLOR 语义,但除了数据类型两边保持了一致并做到字段一一对应之外,该字段跟 Color 本身并没有太大关系。在这里,其实完全可以按照字段本身含义来命名,比如金属度字段,就可以在两边都定义语义为 “METALLIC”,这是在高版本的 HLSL Shader Model 中被允许的做法。这也就启发我们说,在 D3D12_INPUT_ELEMENT_DESC 结构体记录中和 Shader 中,“语义”名称的本质含义其实只是为了对应相应的字段而已,其命名完全是自由的,有时候甚至跟“语义”本身没有任何关系,因此建议大家在必要的时候尽量使用正确含义的“语义”名称来命名字段。而对于相应的 “SV_” 开头的系统变量语义来说,就不能这样做了,因为系统变量语义命名完全是固定的,就像一般语言中的 “关键字” 一样。当然这也就是说你完全可以将位置字段指定语义为NORMAL,这完全没有问题,当然这样引起的后果就是你的代码将非常难以理解,包括你自己,更为严重的后果就是你很可能被你的队友狠揍一顿。
最后需要注意的地方就是,mnInstanceId:SV_InstanceID 这个字段是我们在Shader中直接引用的系统变量,而并没有在 D3D12_INPUT_ELEMENT_DESC 结构体记录中做对应的定义,这就是说类似 SV_ 这样开头的一些系统变量,尤其是类似这里的Instance ID一类的系统变量字段,一般在渲染管线中都是隐含的,不需要我们再去定义字段去对应。也就是说你用或不用,它就在那里,不增不减。
综合起来这时候在 Shader 中我们发现,最终所谓的每实例数据还是被扩展到了每顶点数据上,似乎我们还是绕回了之前说的那个 “笛卡尔积” 的地方。实际上这完全是我们多虑了。其实在 Shader 编译并且最终创建 PSO 的时候, PSO 管线内部已经做了相应的调整,虽然形式上我们传递的每实例数据被扩展填充到了每顶点数据中,但其实它们是被分开存储摆放的,每顶点数据则是在对应的顶点缓冲区中,而每实例数据在这里其实仅仅只是放了个“引用”而已,还是每个实例只有一份并单独集中放在另一块缓冲区中,而最终这两块缓冲区都是由我们的程序来创建和填充的,并且完全由程序来控制。而 Vertex Shader 中的输入参数定义只是一个“引用”定义而已,并不明确的指出这些值的摆放位置,而这些都最终是由我们在C++程序中调用D3D12的API接口来实现控制的。
9、Multi-Intance 的第四步:准备每顶点数据和每实例数据
到这里大家应该已经搞明白了多实例数据定义的技能,接着就是按照刚才所讨论的,分别为每顶点数据和每顶点数据准备缓冲区,并克隆数据。在本章示例中因为按照开始所描述的已经定义了对应的结构体,所以二者的缓冲区其实就是结构体缓冲而已,并且为了简洁性,两个缓冲我们都放置在了上传堆中,也就是共享的缓冲区中,并没有再进一步传递到默认堆也既显存中。而在实际项目代码中,对于模型数据为了优化访问效率,一般都需要传递到显存中,这个区别请大家一定要注意。因为这里毕竟是教程示例,而不是正式的项目代码,所以更注重简洁性和易理解性。
首先,本章示例中准备的 Mesh 缓冲如下:
CHAR pszMeshFile[MAX_PATH] = ;
StringCchPrintfA(pszMeshFile, MAX_PATH, "%sAssets\\\\sphere.txt", T2A(g_pszAppPath));
ST_GRS_VERTEX* pstVertices = nullptr;
UINT* pnIndices = nullptr;
UINT nVertexCnt = 0;
LoadMeshVertex(pszMeshFile, nVertexCnt, pstVertices, pnIndices);
nIndexCnt = nVertexCnt;
g_stBufferResSesc.Width = nVertexCnt * sizeof(ST_GRS_VERTEX);
//创建 Vertex Buffer 仅使用Upload隐式堆
GRS_THROW_IF_FAILED(pID3D12Device4->CreateCommittedResource(
&g_stUploadHeapProps
, D3D12_HEAP_FLAG_NONE
, &g_stBufferResSesc
, D3D12_RESOURCE_STATE_GENERIC_READ
, nullptr
, IID_PPV_ARGS(&pIVB)));
GRS_SET_D3D12_DEBUGNAME_COMPTR(pIVB);
//使用map-memcpy-unmap大法将数据传至顶点缓冲对象
UINT8* pVertexDataBegin = nullptr;
GRS_THROW_IF_FAILED(pIVB->Map(0, nullptr, reinterpret_cast<void**>(&pVertexDataBegin)))以上是关于DirectX12(D3D12)基础教程(十九)—— 多实例渲染的主要内容,如果未能解决你的问题,请参考以下文章