并发编程之线程
Posted shenjianping
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了并发编程之线程相关的知识,希望对你有一定的参考价值。
一、线程概述
1、什么是线程?
线程依附进程而存在的,一个进程至少有一个线程,线程相当于微进程,多进程能实现并发,多线程也同样可以。线程是最小的执行单元。
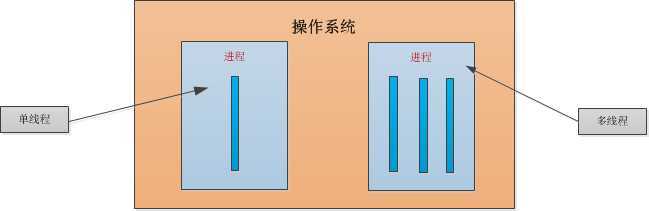
2、线程的特点
- 线程依附进程存在
- 同一个进程中的线程数据是互相共享的
- 一个进程可以开启多个线程
- 进程相当于容器,线程相当于容器中的实体
- 无论启动多少个线程,电脑有多少个cpu,Python在某一时刻只允许一个线程运行
3、为什么需要线程?
进程的开销过大,因为进程在创建过程中,每一个进程都需要各自持有一份数据,而线程因为是在同一个进程中,它们可以共享一份数据,这样减少了并发性能方面的损耗。
二、threading基于线程的并行
(一)直接调用
from threading import Thread import time def task(url): time.sleep(1) print(url,time.ctime()) url_list=[ ‘https://www.baidu.com‘, ‘https://www.zhihu.com‘, ‘https://www.163.com‘, ] if __name__ == ‘__main__‘: p_list = [] for url in url_list: p = Thread(target=task,args=(url,))#实例化3个线程 p.start() #启动每一个线程 print(p.getName()) #获取每一个线程的名字 """ 输出 Thread-1 Thread-2 Thread-3 https://www.baidu.com Fri Sep 27 22:05:22 2019 https://www.zhihu.com Fri Sep 27 22:05:22 2019 https://www.163.com Fri Sep 27 22:05:22 2019 """
(二)继承式调用
from threading import Thread import time class MyThread(Thread): def __init__(self,url): self.url = url super(MyThread,self).__init__() def run(self): """ 必须实现线程运行的run方法 :return: """ time.sleep(1) print(url, time.ctime()) url_list=[ ‘https://www.baidu.com‘, ‘https://www.zhihu.com‘, ‘https://www.163.com‘, ] if __name__ == ‘__main__‘: p_list = [] for url in url_list: p = MyThread(url)#实例化3个线程 p.start() #启动每一个线程 print(p.getName()) #获取每一个线程的名字 """ 输出 Thread-1 Thread-2 Thread-3 https://www.163.com Fri Sep 27 22:13:27 2019 https://www.163.com Fri Sep 27 22:13:27 2019 https://www.163.com Fri Sep 27 22:13:27 2019 """
(三)threading.Thread类的属性和方法
1、构造方法
def __init__(self, group=None, target=None, name=None, args=(), kwargs=None, *, daemon=None): """This constructor should always be called with keyword arguments. Arguments are: *group*应该是None; 当ThreadGroup实现一个类时保留给以后的扩展。 *target* run()方法要调用的可调用对象。默认为None,表示什么都不会被调用。 *name*是线程名称。默认情况下,唯一名称以“ Thread- N ” 的形式构造,其中N是一个小十进制数字。 *args*是目标调用的参数元组。默认为()。 *kwargs*是用于目标调用的关键字参数的字典。默认为{}。 """
2、方法
- start()
启动线程的活动。每个线程对象最多只能调用一次。它使run()方法在单独的控制线程中调用对象的方法。
- run()
表示线程活动的方法。可以在子类中重写此方法。标准run()方法调用传递给对象构造函数的可调用对象作为目标参数(如果有),并分别从args和kwargs参数中获取顺序和关键字参数。
- join(timeout=None)
等待线程终止。这将阻塞调用线程,直到join()被调用方法的线程终止(正常或通过未处理的异常终止),或者直到发生可选的超时。
- getName()
获取正在运行的线程的名称
- is_alive()
返回线程是否处于活动状态。该方法返回True在run()方法开始之前返回,直到run()方法终止之后。模块函数enumerate()返回所有活动线程的列表。
- setDaemon(True)
将线程声明为守护线程,必须在start() 方法调用之前设置, 如果不设置为守护线程程序会被无限挂起。这个方法基本和join是相反的。
当我们 在程序运行中,执行一个主线程,如果主线程又创建一个子线程,主线程和子线程 就分兵两路,分别运行,那么当主线程完成
想退出时,会检验子线程是否完成。如 果子线程未完成,则主线程会等待子线程完成后再退出。但是有时候我们需要的是 只要主线程
完成了,不管子线程是否完成,都要和主线程一起退出,这时就可以 用setDaemon方法啦
3、属性
- daemon
一个布尔值,指示此线程是否是守护线程(真)(假)。必须在start()调用之前设置此参数,否则RuntimeError引发该参数。它的初始值是从创建线程继承的;主线程不是守护程序线程,因此在主线程中创建的所有线程默认为 daemon= False。
当没有活动的非守护线程时,整个Python程序将退出。
- name
仅用于标识,没有语义。多个线程可以被赋予相同的名称。初始名称由构造函数设置。
三、concurrent.futures模块
- 该模块为了并行任务提高更高级别的接口
- 为了执行异步调用该模块既可以实现进程池也可以实现线程池
from concurrent.futures import ThreadPoolExecutor import requests import time def task(url): response=requests.get(url) print(response,time.ctime()) pool=ThreadPoolExecutor(5) url_list=[ ‘https://www.baidu.com‘, ‘https://www.zhihu.com‘, ‘https://www.163.com‘, ] for url in url_list: pool.submit(task,url) #异步提交任务 pool.shutdown() #相当于进程池的pool.close()+pool.join()操作 """ 输出: <Response [200]> Fri Sep 27 23:05:16 2019 <Response [200]> Fri Sep 27 23:05:16 2019 <Response [400]> Fri Sep 27 23:05:21 2019 """
另外,还有一种写法就是加上回调函数,将结果返回给future,之后使用future.result()将结果接收,在回调函数中单独处理。


from concurrent.futures import ThreadPoolExecutor import requests import time def task(url): response=requests.get(url) return response # ########d### def done(future,*args,**kwargs): """ done为回调函数,task执行的结果返回给future,将结果与之后的动作分离开来 :param future: :param args: :param kwargs: :return: """ response=future.result() print(response) pool=ThreadPoolExecutor(5) url_list=[ ‘https://www.baidu.com‘, ‘https://www.zhihu.com‘, ‘https://www.163.com‘, ] for url in url_list: res=pool.submit(task,url) res.add_done_callback(done) pool.shutdown() """ 输出: <Response [200]> <Response [200]> <Response [400]> """
四、threading.local模块
(一)使用
可以创建一个全局对象,各个线程可以用这个全局对象保存各自的局部变量,而在使用时不受其他线程的影响。
from threading import local,Thread,current_thread data = local() #定义全局local对象 def handle(): data.x = 1 for i in range(50): data.x += 1 print(current_thread(),data.x) if __name__ == ‘__main__‘: for i in range(5): t = Thread(target=handle) t.start() """ 输出: <Thread(Thread-1, started 3968)> 51 <Thread(Thread-2, started 5936)> 51 <Thread(Thread-3, started 8808)> 51 <Thread(Thread-4, started 7960)> 51 <Thread(Thread-5, started 7144)> 51 """
可以看到每一个线程输出的值都是一样的,虽然定义了全局对象local,但是定义的data.x属性是每一个线程独有的。本质是不同的线程使用同一个local对象创建不同的数据字典。
(二)全局变量和局部变量
1、global
全局变量使用global关键字
from threading import local,Thread,current_thread x=1 def handle(): global x for i in range(50): x += 1 print(current_thread(),x) if __name__ == ‘__main__‘: for i in range(5): t = Thread(target=handle) t.start() """ 输出: <Thread(Thread-1, started 8384)> 51 <Thread(Thread-2, started 1212)> 101 <Thread(Thread-3, started 7508)> 151 <Thread(Thread-4, started 8904)> 201 <Thread(Thread-5, started 8024)> 251 """
定义全局变量x,这样每一个线程都更改同一个变量,导致计算杂乱无章。
2、局部变量
from threading import local,Thread,current_thread def handle(): x =1 for i in range(50): x += 1 print(current_thread(),x) if __name__ == ‘__main__‘: for i in range(5): t = Thread(target=handle) t.start() """ 输出: <Thread(Thread-1, started 7244)> 51 <Thread(Thread-2, started 6704)> 51 <Thread(Thread-3, started 1488)> 51 <Thread(Thread-4, started 844)> 51 <Thread(Thread-5, started 8600)> 51 """
每一个线程使用自己的x属性,所以输出的值都是一定的。
(三)总结
threading.local模块可以对线程的数据进行管理:
- local模块实例化全局对象
- 每一个线程在使用这个对象都将创建自己的一个字典,类似于局部变量
- 每一个线程数据字典是独立的,互不干扰,试图去读取其它线程的数据会导致错误
五、线程通信
(一)queue模块
1、队列使用的必要性
当必须在多个线程之间安全地交换信息时,它就显得尤为重要了,因为内置了很多锁,保证了数据的安全性。
2、queue模块中的类
- queue.Queue(maxsize = 0)
FIFO(先进先出)队列的构造函数。 maxsize是一个整数,用于设置可以放入队列中的项目数的上限。一旦达到此大小,插入将被阻塞,直到消耗队列项目为止。如果 maxsize小于或等于零,则队列大小为无限。
- queue.LifoQueue(maxsize = 0)
LIFO(后进先出)队列的构造函数。 maxsize是一个整数,用于设置可以放入队列中的项目数的上限。一旦达到此大小,插入将被阻塞,直到消耗队列项目为止。如果 maxsize小于或等于零,则队列大小为无限。
- queue.PriorityQueue(maxsize = 0)
优先级队列的构造函数。 maxsize是一个整数,用于设置可以放入队列中的项目数的上限。一旦达到此大小,插入将被阻塞,直到消耗队列项目为止。如果 maxsize小于或等于零,则队列大小为无限。
最低值的条目将首先被检索(最低值的条目是由返回的条目sorted(list(entries))[0])。条目的典型模式是形式为元组(priority_number, data)。
- 异常queue.Empty
在空对象上调用非阻塞get()(或 get_nowait())时引发异常Queue。
- 异常queue.Full
在已满的队列对象上调用非阻塞put()(或 put_nowait())时引发异常Queue。
该模块实现了三种类型的队列,它们的区别仅在于检索条目的顺序不同。在FIFO 队列中,首先检索到添加的第一个任务。在 LIFO队列中,最近添加的条目是第一个检索到的条目(操作类似于堆栈)。使用优先级队列,条目将保持排序(使用heapq模块),并且最先检索值最低的条目。
在内部,该模块使用锁来临时阻止竞争线程。
3、队列对象
队列对象(Queue,LifoQueue或PriorityQueue)提供的公共方法:
- Queue.qsize()
返回队列的大小。注意,qsize()> 0不能保证后续的get()不会阻塞,qsize()<maxsize也不能保证put()不会阻塞。
- Queue.empty()
如果返回True,队列为空。注意,如果返回True,不能保证后续put()的调用都不会阻塞。同样,如果empty()返回False,也不能保证get()的后续调用不会阻塞。
- Queue.full()
如果队列已满,返回True,否则返回False。注意,如果full()返回True,不能保证get()的后续调用不会阻塞。同样,如果full()返回False,也不能保证后续put()的调用都不会阻塞。
- Queue.put(item,block = True,timeout = None )
将item放入队列。如果可选的args、block为True且timeout为 None(默认),则在必要时阻塞,直到有可用插槽可用。如果 超时为正数,则它最多会阻塞超时的时间,Full如果在该时间内没有空闲插槽可用,则会引发异常。否则(block为False),如果在该时间内没有空闲插槽可用,则会引发异常。如果有空闲插槽立即可用,则将item放在队列中。否则引发Full异常(在这种情况下将忽略超时)。
- Queue.put_nowait(item)
等同于put(item, False)
- Queue.get(block = True,timeout = None )
从队列中删除并返回一个item。如果可选的args block为true,并且 timeout为None默认值,则在必要时阻塞,直到有可用的item为止。如果超时为正数,则它最多会阻塞超时的时间,Empty如果在该时间内没有可用的item,则会引发异常。否则(block为false),如果有立即可用的item,则返回一个item,否则引发Empty异常(在这种情况下,超时将被忽略)。
- Queue.get_nowait()
等同于get(False)。
- Queue.task_done()
在完成一项工作之后,Queue.task_done() 函数向任务已经完成的队列发送一个信号
- Queue.join()
阻塞直到队列中的所有item都已获得并处理。实际上意味着等到队列为空,再执行别的操作。
每当将item添加到队列时,未完成任务的数量就会增加。每当使用者线程调用task_done()以指示已检索到该item并且该item的所有工作完成时,该计数就会减少。当未完成的任务数降至零时,join()取消阻止。
(二)使用
1、先进先出队列
mport queue import threading import time def do_work(item): print("%s已经完成"%item,time.ctime()) time.sleep(1) def worker(): while True: item = q.get() #取出队列中的任务 if item is None: break do_work(item) #进行任务 q.task_done() #任务完成后向队列发送一个讯号通知一下 if __name__ == ‘__main__‘: q = queue.Queue() t_list = [] num_worker_threads = 5 # 5个工人线程完成任务 for i in range(num_worker_threads): t = threading.Thread(target=worker) t.start() # 将10个任务放入队列中 for item in range(10): q.put(item) # 等队列中的任务全部取出并且处理 q.join() #结束所有工人线程 for i in range(num_worker_threads): q.put(None) for t in t_list: t.join() """ 输出: 0已经完成 Sat Sep 28 15:51:41 2019 1已经完成 Sat Sep 28 15:51:41 2019 2已经完成 Sat Sep 28 15:51:41 2019 3已经完成 Sat Sep 28 15:51:41 2019 4已经完成 Sat Sep 28 15:51:41 2019 5已经完成 Sat Sep 28 15:51:42 2019 6已经完成 Sat Sep 28 15:51:42 2019 8已经完成 Sat Sep 28 15:51:42 2019 9已经完成 Sat Sep 28 15:51:42 2019 7已经完成 Sat Sep 28 15:51:42 2019 """
注意:
#put、put_nowait和get、get_nowait方法的区别 q.put() #不会报错,阻塞等待 q.put_nowait() #如果队列是有长度的,那么放满了此时不会阻塞,而是直接报错 q.get() #不会报错,阻塞等待 q.get_nowait() #如果队列已经空了,那么继续get不会阻塞,而是直接报错 #使用用异常处理,来让队列不阻塞也不报错 # try: # q.get_nowait() #为空会报错 # except: # print(‘队列已空‘)
2、其它队列
import queue #LifoQueue后进先出 q = queue.LifoQueue() q.put(1) q.put(2) print(q.get()) #输出为2,后进先出,类似栈 # PriorityQueue 优先队列,put参数传入为一个元组 (优先级,要传入得值)
#数字越小,代表优先级越高。当优先级一样的时候,根据传入的值的 ASCII码值的顺序,进行排列 q = queue.PriorityQueue() q.put((11,‘zhangsan‘)) q.put((2,‘lisi‘)) q.put((6,‘wangwu‘)) print(q.get()) #输出(2, ‘lisi‘)
六、线程同步
(一)threading.Lock 同步锁/互斥锁
当遇到多个线程操作同一个资源时,会引发资源安全或者错乱的情况,此时可以使用同步锁/互斥锁进行解决,在某一时刻只允许一个线程来操作该资源。比较形象的比喻就是房子外面挂着一把钥匙,谁拿着钥匙就进去,直到钥匙被归还,另一个线程再拿着钥匙进去。
from threading import Lock, Thread data = 100 # 设置一个共享的全局变量 def handle(lock): global data lock.acquire() # 拿到钥匙 data = data - 1 lock.release() # 归还钥匙 if __name__ == ‘__main__‘: lock = Lock() t_list = [] for i in range(5): t = Thread(target=handle, args=(lock,)) t_list.append(t) t.start() [t.join() for t in t_list] # 等待所有的线程执行完毕 print(data)
死锁:当多个进程抢夺同一个资源而造成互相等待的现象,若无外力作用将会一直持续下去,此时系统处于死锁状态。
(二)threading.RLock 递归锁
递归锁就是用来解决在使用同步锁情况下出现的死锁情况。下面是一个死锁的情况:
import threading import time def eat1(name): noodle_lock.acquire() time.sleep(3) print("%s获取面条" % name) fork_lock.acquire() print("%s获取叉子" % name) print("%s吃面了" % name) fork_lock.release() noodle_lock.release() def eat2(name): fork_lock.acquire() time.sleep(5) print("%s获取叉子" % name) noodle_lock.acquire() print("%s获取面条" % name) print("%s吃面了" % name) noodle_lock.release() fork_lock.release() if __name__ == ‘__main__‘: noodle_lock = threading.Lock() fork_lock = threading.Lock() threading.Thread(target=eat1, args=(‘zhangsan‘,)).start() threading.Thread(target=eat2, args=(‘lisi‘,)).start() """ 输出: zhangsan获取面条 lisi获取叉子 """
上面的当zhangsan获取面条这个锁时,lisi获取了叉子这个锁,当zhangsan再获取叉子这个锁时已经无法获取,同样的lisi再获取面条这个锁时也是无法获取,这样就造成了死锁。
使用递归锁可以解决这个问题,递归锁相当于有一串钥匙。
import threading import time def eat1(name): noodle_lock.acquire() time.sleep(3) print("%s获取面条" % name,time.ctime()) fork_lock.acquire() print("%s获取叉子" % name,time.ctime()) print("%s吃面了" % name,time.ctime()) fork_lock.release() noodle_lock.release() def eat2(name): fork_lock.acquire() time.sleep(5) print("%s获取叉子" % name,time.ctime()) noodle_lock.acquire() print("%s获取面条" % name,time.ctime()) print("%s吃面了" % name,time.ctime()) noodle_lock.release() fork_lock.release() if __name__ == ‘__main__‘: noodle_lock = fork_lock = threading.RLock() #递归锁,相当于拥有一串钥匙,其它的线程拿不到了,相当于将拿到面条、拿到叉子然后吃面,之后下一个线程也是如此 threading.Thread(target=eat1, args=(‘zhangsan‘,)).start() threading.Thread(target=eat2, args=(‘lisi‘,)).start() """ 输出: zhangsan获取面条 Sat Sep 28 12:34:28 2019 zhangsan获取叉子 Sat Sep 28 12:34:28 2019 zhangsan吃面了 Sat Sep 28 12:34:28 2019 lisi获取叉子 Sat Sep 28 12:34:33 2019 lisi获取面条 Sat Sep 28 12:34:33 2019 lisi吃面了 Sat Sep 28 12:34:33 2019 """
递归锁就是用来解决死锁问题的,注意的是:
- 在只有一个线程时,递归锁不起作用
- 对个线程,如果一个线程拿到锁了(acquire),其它的就拿不到了
RLock内部维护着一个Lock和一个counter变量,counter记录了acquire的次数,从而使得资源可以被多次acquire。直到一个线程所有的acquire都被release,其他的线程才能获得资源。
(三)threading.Semaphore 信号量
同步锁允许在某一时刻一个线程来操作资源,但是信号量在某一时刻允许一定数量的线程操作资源。
信号量同步是基于内部计数器,每调用一次acquire(),计数器减1;每调用一次release(),计数器加1;当计数器为0时,acquire()调用被阻塞,直到有线程调用release()。
值得注意的是信号量也是锁,只是在内部加了一个计算器。
在火车站内需要对顾客进行检查,假设每次只能检查4个人,然后检查完毕的人再换下个顾客来检查,这里每次检查4个人就是信号量可以并发处理4个线程。
import threading import time def check_person(i,sem): sem.acquire() time.sleep(1) print(i+1,time.ctime()) sem.release() if __name__ == ‘__main__‘: sem = threading.Semaphore(4) #同时四个人进行检查 for i in range(50): t = threading.Thread(target=check_person,args=(i,sem)) t.start() """ 输出: 1 Sat Sep 28 12:55:01 2019 2 Sat Sep 28 12:55:01 2019 3 Sat Sep 28 12:55:01 2019 4 Sat Sep 28 12:55:01 2019 5 Sat Sep 28 12:55:02 2019 6 Sat Sep 28 12:55:02 2019 8 Sat Sep 28 12:55:02 2019 7 Sat Sep 28 12:55:02 2019 ... """
可以明显看出,每次都是4个线程一起并发,相当于4个人检查完毕。
(四)threading.Event 事件
1、Event事件概述
- 这是线程之间通信的最简单机制之一:一个线程发出事件信号,其他线程等待事件。
- 事件对象管理一个内部标志,该标志可以通过方法设置为true,并通过
set()方法设置为falseclear()。该wait()方法将阻塞直到标志为真。 - 所以事件对象的机制就是:全局定义了一个Flag,如果Flag值为 False,当程序执行event.wait()方法时就会阻塞,如果Flag值为True时,程序执行event.wait()方法时不会阻塞继续执行。
2、常用属性、方法
is_set()
-
当且仅当内部标志Flag为True时,才返回True。
set()
-
将内部标志Flag设置为True。唤醒所有等待变为真的线程。
wait()一旦标志为True的线程将根本不会阻塞。
clear()
-
将内部标志Flag重置为False。随后,线程调用
wait()将阻塞,直到set()被调用以再次将内部标志设置为True为止。
wait(timeout = None )
-
阻塞直到内部标志Flag为真。如果内部标志在输入时为True,立即返回。否则,阻塞直到另一个线程调用
set()将该标志设置为True,或者直到发生可选的超时为止。如果存在timeout参数而不是timeout参数
None,则它应该是一个浮点数,以秒为单位(或几分之一)指定操作的超时时间。当且仅当内部标志在等待调用之前或等待开始之后设置为True时,此方法才返回True,因此它将始终返回
True,除非给出了超时且操作超时。
3、事件的使用
以汽车过红绿灯为例,当为红灯时,汽车不能通过十字路,当为绿灯时,汽车是可以通过十字路:
参考:
https://docs.python.org/3.6/library/threading.html#thread-objects
https://docs.python.org/3.6/library/queue.html
https://www.cnblogs.com/yuanchenqi/articles/6248025.html
以上是关于并发编程之线程的主要内容,如果未能解决你的问题,请参考以下文章