大三寒假生活13
Posted quyangzhangsiyuan
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了大三寒假生活13相关的知识,希望对你有一定的参考价值。
今天完成了实验五第三问,实验六也进行了一点。明天继续进行实验六。
编程实现利用 DataFrame 读写 mysql 的数据
(1) 在 MySQL 数据库中新建数据库 sparktest,再建表 employee,包含下列两行数据;
表 1 employee 表原有数据

(2) 配置Spark通过JDBC连接数据库MySQL,编程实现利用DataFrame插入下列数据到MySQL,
最后打印出 age 的最大值和 age 的总和。
表 2 employee 表新增数据

import java.util.Properties import org.apache.spark.sql.types._ import org.apache.spark.sql.Row object TestMySQL{ def main(args: Array[String]) { val employeeRDD = spark.sparkContext.parallelize(Array("3 Mary F 26","4 Tom M 23")).map(_.split(" ")) val schema = StructType(List(StructField("id", IntegerType, true),StructField("name", StringType, true),StructField("gender", StringType, true),StructField("age", IntegerType, true))) val rowRDD = employeeRDD.map(p => Row(p(0).toInt,p(1).trim,p(2).trim,p(3).toInt)) val employeeDF = spark.createDataFrame(rowRDD, schema) val prop = new Properties()prop.put("user", "root") prop.put("password", "password") prop.put("driver","com.mysql.cj.jdbc.Driver") employeeDF.write.mode("append").jdbc("jdbc:mysql://127.0.0.1:3306/sparktest", "sparktest.employee", prop) val jdbcDF = spark.read.format("jdbc").option("url","jdbc:mysql://127.0.0.1:3306/sparktest").option("driver","com.mysql.cj.jdbc.Driver").option("dbtable","employee").option("user","root").option("password", "password").load()
jdbcDF.agg("age"-> "max", "age"-> "sum").show()
jdbcDF.show() } }
跟第二问一样,如果写成scala文件打包运行会报错
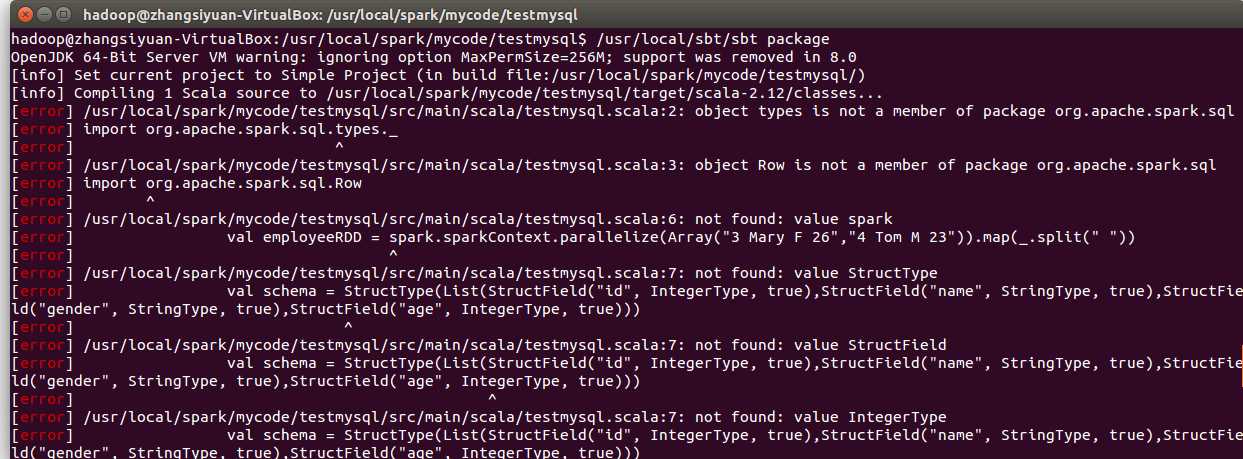
找不到解决办法,只能打开spark-shell一行一行运行。
如果报连接失败的错误就是没有JDBC驱动
可以去官网进行下载:https://dev.mysql.com/downloads/connector/j/
我是直接通过FTP把windows中的驱动包复制到了虚拟机中。
然后如果还是报错,可能是你的地址不对。错误忘了截图。一开始localhost,就一直报错,然后改成127.0.0.1成功运行。修改成你对应的地址,如果你没有修改过mysql的地址就是127.0.0.1
以上是关于大三寒假生活13的主要内容,如果未能解决你的问题,请参考以下文章