技术的极限(10): 稍微理解一下技术的原理
Posted math
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了技术的极限(10): 稍微理解一下技术的原理相关的知识,希望对你有一定的参考价值。
目录:
** 0x01 花时间在有伸缩性的事情上|Do Things That Scale
** 0x02 浏览器引擎简史
** 0x03 Git内部的对象存储|Git-Internals-PDF
** 0x04 函数式可组合UI组件|React Hook
** 0x05 如何画出完备的状态图
** 0x06 MIT的CS工具课
** 0x07 自由开放格式的图像格式|FLIF - Free Lossless Image Format
** 0x08 微服务的黑暗面|The Dark Side of Microservices, Explained
0x01 花时间在有伸缩性的事情上|Do Things That Scale
原文: https://blogs.gnome.org/tbernard/2020/01/17/doing-things-that-scale/
这篇文章的作者认为不必浪费时间在那些没有伸缩性(Scale)的事情上,例如:
- 只解决了自己或少数人的问题:Only fix a problem for myself (and maybe a small group of others)
- 需要永久维护,例如需要自己永久维护:Have to be maintained in perpetuity (by me)
而应该做那些更有伸缩性的事情:
- 修复那些大多数人大部分时候需要解决的问题:Fix the problem in way that will just work? for most people, most of the time
- 由社区里广泛的人参与开发、使用和维护的项目:Are developed, used, and maintained by a wider community
0x02 浏览器引擎简史
主流浏览器和它们的引擎:
- IE浏览器的渲染引擎是Trident
- Chromium浏览器的渲染引擎是Blink
- Safari浏览器的渲染引擎是Webkit
- Edge浏览器原来的渲染引擎是Edgehtml,现在是基于Chromium魔改了.
- Mozilla firefox的渲染引擎原来是Gecko,现在逐渐改为基于rust开发的Servo
- Opera浏览器原来有独立的渲染引擎,现在也基于Chromium了,但是原始的一帮人又自己另外搞了一个独立的浏览器引擎和浏览器,做个性化定制。
而Blink,2013年之前Chromium浏览器的引擎也是Webkit,只是Google想要做多进程构架,于是就自立门户,改名自家的渲染引擎为Blink,并且删除了大量的Webkit里不被需要的文件,从此以后不再向上游Webkit提交。基于Webkit渲染引擎的浏览器除了Apple的Safari外,还有很多其他的。而Webkit前身是KDE小组的 KHTML.
[1] Webkit引擎主页
[2] Blink引擎
[3] Servo
0x03 Git内部的对象存储|Git-Internals-PDF
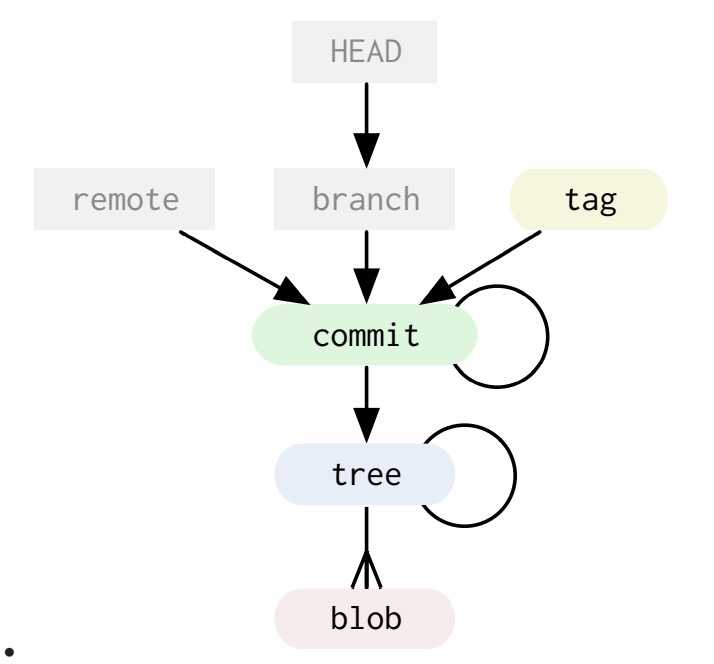
原文:https://github.com/pluralsight/git-internals-pdf
十分详细完整优美的Git内部结构的文档,图文并茂],五??推荐,我完整读完了,这个教程的前半部分讲Git内部结构写的非常好。后半部分是讲使用的部分,那个大家都比较熟悉了。
Git内部的对象存储,两个核心概念是:Git Object和Git Ref。
Git内部的Object包含:
- 对应文件的blob对象
- 对应目录的tree,tree对象包含blob或下级tree(图中自指剪头的含义)
- 对应一次提交的commit,commit包含指向父节点的commit(图中自指箭头的含义)以及指向本次提交的tree根节点
- 对应打标记的tag对象,tag对象一般指向打标记时当前分支上的commit
Git内部的Ref包含:
- Branch(分支),实际上就是某个commit的一个hash的别名
- HEAD,当前分支的最新commit的hash的别名
- Remote,远程仓库的分支信息
建议花时间读下这个文档。
0x04 函数式可组合UI组件|React Hook
原文: https://reactjs.org/docs/hooks-intro.html
我看了下React的Hook,这个Feature让你用一个function来写一个React Component class做的事情。我表示悲观,很多前端本来对分离状态和UI就很懵,用function只会导致对模块化边界的进一步弱化。
React Hook试图用相对来说Stateless的方式让UI组件更轻量、可组合性更好。但是实际业务的逻辑是膨胀的,膨胀后还能持续保持function里的代码逻辑清晰,组件粒度控制合理,成本更高,反而class至少能在class对边界上控制住这个理解复杂度的膨胀。function是可以做class的事情,但是当应对膨胀的业务逻辑时,function很容易变成一个能力不足的class,换一个好的说法是你需要更高的掌控抽象的能力,但是与此相反的是,在开发人群中,对抽象能力掌握更好的是在金字塔的上半部分。
- It’s hard to reuse stateful logic between components
- Complex components become hard to understand
React Hook想要解决的问题是这两个,但是我认为这是少数前端才会需要的,大部分前端需要的不是这个。
0x05 如何画出完备的状态图
原文:drawing-minmal-dfa-for-the-given-regular-expression
这是一个讲解如何画出一个正则表达式对应的DFA图的文章,它的思路很适合画出其他状态机的状态图。
画出正确的状态图的关键步骤是:
- 首先找到从初始状态(init state)到最终状态(final state)的最小转换路径;
- 其次考虑从final state遇到新的输入后,应该到哪个状态;
- 最后,考虑已知状态遇到其他剩余的输入后,应该转换到哪个状态。
这样,你可以思考,应该有哪些状态,从而得到有限状态集合;以及有哪些输入会导致状态发生变化,从而得到状态迁移的输入集合。
0x06 MIT的CS工具课
原文:The Missing Semester of Your CS Education
MIT的开放课程上有很多课程,学生们会花很多时间在使用工具上,因此MIT认为花时间把这些工具掌握的稍微流利一点,理解一点点工具背后的设计是有价值的。理解和掌握工具不但能减少时间,还能更好地辅助解决复杂的问题。
该课程包含如下这些主题:
- 1/13: Course overview + the shell
- 1/14: Shell Tools and Scripting
- 1/15: Editors (Vim)
- 1/16: Data Wrangling
- 1/21: Command-line Environment
- 1/22: Version Control (Git)
- 1/23: Debugging and Profiling
- 1/27: Metaprogramming
- 1/28: Security and Cryptography
- 1/29: Potpourri
- 1/30: Q&A
我看了下其中的Version Control (Git)这篇,使用如下的类型描述,点到为止地描述了Git内部的对象存储:
// a file is a bunch of bytes
type blob = array<byte>
// a directory contains named files and directories
type tree = map<string, tree | file>
// a commit has parents, metadata, and the top-level tree
type commit = struct {
parent: array<commit>
author: string
// 注:原文没有,但最新的git有这个
committer: string
message: string
tree: tree
}
type object = blob | tree | commit
objects = map<string, object>
def store(object):
id = sha1(object)
objects[id] = object
def load(id):
return objects[id]实际上,我们可以补充下 git 的 tag 。tag 有两种,lightweight tag 是 ref,annotated tag 是 object,通常我们发版本后添加的tag就是一个object字段是指向一个commit的annotated tag,类型描述如下:
// 注:原文没有,我添加的
// a tag provides a permanent shorthand name for a particular commit.
// it contains an object, type, tag, tagger and a message
type tag = struct {
// object是某个commit的hash
object: string
type: string
tag: string
tagger: string
message: string
}
0x07 自由开放格式的图像格式|FLIF - Free Lossless Image Format
一种自由的无损图像压缩格式,下面是它的压缩优势:
- 14% smaller than lossless WebP,
- 22% smaller than lossless BPG,
- 33% smaller than brute-force crushed PNG files (using ZopfliPNG),
- 43% smaller than typical PNG files,
- 46% smaller than optimized Adam7-interlaced PNG files,
- 53% smaller than lossless JPEG 2000 compression,
- 74% smaller than lossless JPEG XR compression.
另一个自由和开放格式的下一代图像格式是JEPG-XL,JPEG-XL的一个吸引人的特性是支持从已有的JPEG图像无损地转换到JPEG-XL,同时显著地减小尺寸:
JPEG XL includes several features that help transition from the legacy JPEG format. Existing JPEG files can be losslessly transcoded to JPEG XL, while significantly reducing their size.
0x08 微服务的黑暗面|The Dark Side of Microservices, Explained
原文:https://hackernoon.com/the-dark-side-of-microservices-explained-s6z3679
微服务的黑暗面。微服务是分布式系统的一种,解决的核心问题也是分布式系统的两个重要问题:【共识(consensus)】和【部分失败(partial failure)】。因为这两个问题如此麻烦,以至于大部分时候我们只能把它们交给7*24都花时间在解决这些问题的工程师所造的产品上,例如Database和K8s。然而即使这样,开发、调试、监控、日志、部署依然是很麻烦的事,这些麻烦就是微服务的黑暗面。
- A distributed system is any collection of computers that work together to perform a task.
- Microservices are simply a type of distributed system designed for delivering the backend of a web service.
- Since the early days of distributed systems research going back to the 70s.
- We’ve known that distributed systems are hard.
- From a theoretical perspective, the difficulty mostly arises from two key areas:
- consensus
- and partial failure.
共识:
- 这些共识算法都是在强一致性和性能之间取舍:Paxos, Raft, 时钟向量(Vector Clocks), ACID, 最终一致性(Eventual Consistency), Map Reduce, Spark, Spanner等等。
- A机器修改数据x为5,B机器修改数据x为6,此时x应该等于什么?看两次修改的时间谁先谁后?但是以A还是B的时间为准呢?大部分时候我们只能托管给DataBase或者其他共享状态组件。
部分失败:
- 一次RPC调用,跨越了A、B、C、D...多个微服务,任何一个步骤失败,都会导致调用处于部分失败情况。[1]
- 不要使用同步API、使用指数增加的重试间隔、处理超时、使用熔断方式处理连续N次的失败并周期性尝试和恢复、使用降级的方式返回缓存数据或默认数据、使用桶或者窗口等技术限制并发请求数等。[2]
参考:
[1] 微软的文档上的图片可以直观地看到部分失败的图解
[2] 解决部分失败的策略
[3] PAXOS
[4] RAFT
[5] Vector Clock
[6] Eventual Consistency
--end--
以上是关于技术的极限(10): 稍微理解一下技术的原理的主要内容,如果未能解决你的问题,请参考以下文章