2月10日学习记录
Posted lq13035130506
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了2月10日学习记录相关的知识,希望对你有一定的参考价值。
1,背诵单词:assault 猛烈地攻击,袭击 principal最重要的,主要的 consumption 消费(量),消耗 sniff .嗅…味道;抽鼻涕 extensive广大的,广阔的 tolerance 宽容 denote 表示,意味着 fierce 凶猛的,残忍的 idiot白痴;笨蛋 regarding关于,有关 surge汹涌;彭湃 railroad 铁路 coordinate 同等的,并列的 renovate 更新,修复 efficiency效率;功效 gown长袍 cotton棉花;棉线 minor较小的,较小的 magistrate地方行政官 whale n.鲸;庞然大物
2,做爬取北京信件网页内容并学习Java爬虫webMagic框架观看视频:https://www.bilibili.com/video/av48765648? 23到33集
1,添加webMagic依赖
2,添加资源文件log4j.properties
3,WebMagic的结构分为Downloader、PageProcessor、Scheduler、Pipeline四大组件,
1.Downloader
Downloader负责从互联网上下载页面,以便后续处理。WebMagic默认使用了Apache HttpClient作为下载工具。
2.PageProcessor
PageProcessor负责解析页面,抽取有用信息,以及发现新的链接。WebMagic使用Jsoup作为html解析工具,并基于其开发了解析XPath的工具Xsoup。
在这四个组件中,PageProcessor对于每个站点每个页面都不一样,是需要使用者定制的部分。
3.Scheduler
Scheduler负责管理待抓取的URL,以及一些去重的工作。WebMagic默认提供了JDK的内存队列来管理URL,并用集合来进行去重。也支持使用Redis进行分布式管 理。除非项目有一些特殊的分布式需求,否则无需自己定制Scheduler。
4.Pipeline
Pipeline负责抽取结果的处理,包括计算、持久化到文件、数据库等。WebMagic默认提供了“输出到控制台”和“保存到文件”两种结果处理方案。Pipeline定义了结 果保存的方式,如果你要保存到指定数据库,则需要编写对应的Pipeline。对于一类需求一般只需编写一个Pipeline。
4,常用对象:
1. Request
Request是对URL地址的一层封装,一个Request对应一个URL地址。它是PageProcessor与Downloader交互的载体,也是PageProcessor控制Downloader唯一方 式。除了URL本身外,它还包含一个Key-Value结构的字段extra。你可以在extra中保存一些特殊的属性,然后在其他地方读取,以完成不同的功能。例如附加上一个页 面的一些信息等。
2. Page
Page代表了从Downloader下载到的一个页面——可能是HTML,也可能是JSON或者其他文本格式的内容。Page是WebMagic抽取过程的核心对象,它提供一些方法 可供抽取、结果保存等。在第四章的例子中,我们会详细介绍它的使用。
3. ResultItems
ResultItems相当于一个Map,它保存PageProcessor处理的结果,供Pipeline使用。它的API与Map很类似,值得注意的是它有一个字段skip,若设置为true,则不 应被Pipeline处理。
5,抽取元素:
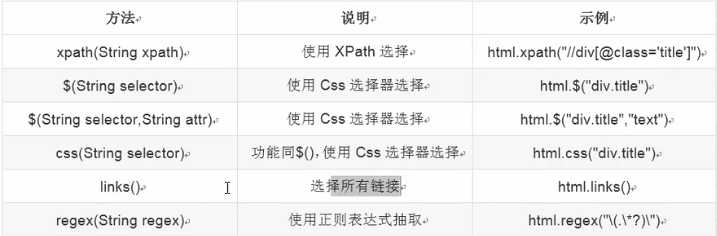
xpath方法:
//查找所有的"B" var xpath="//B"; //查找所有元素 xpath = “//*”; // 选择所有路径依附于/A/B/的元素 xpath ="/A/B/*"; //选择所有的有3个祖先元素的B元素 xpath ="///*/B" ; // 选择所有父元素是DDD的BBB元素 xpath="//C/D"; // 选择A/B/C的第一个E子元素 xpath="/A/B/C/E[1]"; //选择A/B/C的最后一个E子元素 xpath="/A/B/C/E[last()]" ; //选择有name属性的B元素 xpath = “//B[@name]” ; //选择所有的name属性 xpath="//@name"; //选择有任意属性的B元素 xpath="//B[@*]"; //选择没有属性的B元素 xpath="//B[not(@*)]"; //选择含有属性id且其值为’e2’的E元素 xpath="//E[@id=‘e2’]"; //选择含有属性name且其值(在用normalize-space函数去掉前后空格后)为’b’的B元素 xpath="//B[normalize-space(@name)=‘b’]"; //选择含有2个B子元素的元素 xpath="//*[count(B)=2]"; //选择含有3个子元素的元素 xpath="//[count()=3]"; //选择所有名称为B的元素(这里等价于//B) xpath="//*[name()=‘B’]"; //选择所有名称以"W"起始的元素 xpath="//*[starts-with(name(),‘W’)]"; //选择所有名称包含"W"的元素 xpath="//*[contains(name(),‘W’)]"; //选择名字长度为2(大于、小于)的元素; xpath="//*[string-length(name()) = 2]"; xpath="//*[string-length(name()) < 2]"; xpath="//*[string-length(name()) > 1]"; //多个路径可以用分隔符 | 合并在一起,可以合并的路径数目没有限制,选择所有的WF和C元素 xpath="//WF | //C"; //等价于/A xpath="/child::A"; //等价于//C/D xpath="//child::C/child:: D";
3,遇到的问题:对Java集合的操作不熟练
4,明天计划:继续将爬取的数据进行分析并学习hive的使用
以上是关于2月10日学习记录的主要内容,如果未能解决你的问题,请参考以下文章