Spark应用程序--词频统计--命令行分析学习
Posted daisy99lijing
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了Spark应用程序--词频统计--命令行分析学习相关的知识,希望对你有一定的参考价值。
词频统计:
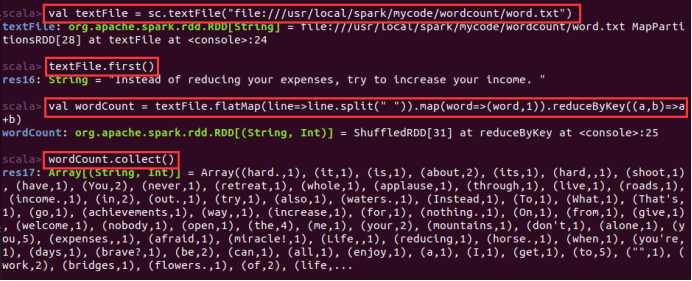
textFile包含了多行文本内容:
textFile.flatMap(line => line.split(” “))会遍历textFile中的每行文本内容,当遍历到其中一行文本内容时,会把文本内容赋值给变量line,并执行Lamda表达式line => line.split(” “)。
line => line.split(” “)是一个Lamda表达式,左边表示输入参数,右边表示函数里面执行的处理逻辑,这里执行line.split(” “),也就是针对line中的一行文本内容,采用空格作为分隔符进行单词切分,从一行文本切分得到很多个单词构成的单词集合。这样,对于textFile中的每行文本,都会使用Lamda表达式得到一个单词集合,最终,多行文本,就得到多个单词集合。
textFile.flatMap()操作就把这多个单词集合“拍扁”得到一个大的单词集合。
然后,针对这个大的单词集合,执行map()操作:
map(word => (word, 1))这个map操作会遍历这个集合中的每个单词,当遍历到其中一个单词时,就把当前这个单词赋值给变量word,并执行Lamda表达式word => (word, 1),这个Lamda表达式的含义是,word作为函数的输入参数,然后,执行函数处理逻辑,这里会执行(word, 1),也就是针对输入的word,构建得到一个tuple,形式为(word,1),key是word,value是1(表示该单词出现1次)。程序执行到这里,已经得到一个RDD,这个RDD的每个元素是(key,value)形式的tuple。
最后,针对这个RDD,执行reduceByKey((a, b) => a + b)操作,这个操作会把所有RDD元素按照key进行分组,然后使用给定的函数(这里就是Lamda表达式:(a, b) => a + b),对具有相同的key的多个value进行reduce操作,返回reduce后的(key,value),比如(“hadoop”,1)和(“hadoop”,1),具有相同的key,进行reduce以后就得到(“hadoop”,2),这样就计算得到了这个单词的词频
以上是关于Spark应用程序--词频统计--命令行分析学习的主要内容,如果未能解决你的问题,请参考以下文章