词向量
Posted petewell
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了词向量相关的知识,希望对你有一定的参考价值。
自然语言处理-词向量
引言
在计算机视觉中,作为输入的图片可以直接数值化。在语言识别中,作为输入的语音也可以直接数值化。而在自然语言处理中,我们无法将文字直接数值化,为了能够让计算机处理文字,我们需要将文字映射到一个数值空间。由于词是组成语义的基本单位,所以对词的表述就显得尤为重要,我们把词的数值(表征)表示为Word Representation,一般来说,词向量经常指Word Embedding,也称Distributed Word Representation。
摘要
从Word Representation的发展过程引入Word Embedding,先从简单的SVD介绍开始,再到NNLM,word2vec等词向量模型。
one-hot编码
one-hot编码也称独热编码,这是一种简单的词表征方式,每个词使用一个$R^{|V|}$的向量表示,$|V|$表示词表的大小。
使用one-hot编码的词向量之间是相互独立的,因为对于每个词$(w^{i})^{T}w^j = 0$,这种编码方式并没有编码不同词之间的语义相似性。
基于矩阵分解的词表征
词–文档矩阵(Word-Document Matrix)
如果我们有大量的文档,我们用一个矩阵来存储所有文档的词频信息。矩阵的行向量代表词,列向量代表文档,每个元素代表词在文档中出现的频数,比如我们现在有两篇文档:
$I quad love quad NLP I quad love quad deep quad learningI$
经过统计次数,我们可以得到以下矩阵:
如果两个文档有相似的主题,那么两个文档的列向量会趋于有相似类型的词数量。该模型主要用于衡量文档主题的相似性。
基于窗口的词共现矩阵(Window based Co-occurrence Matrix)
给定一个词,计算在一个限定大小的窗口中出现的其他词的次数。我们将这些计数放在一个矩阵中,矩阵的行表示词,列也是词。假如窗口大小为1,我们需要计算当前词左右两边的两个词。比如,我们两个句子:
$I quad love quad NLP I quad love quad deep quad learningI$
窗口长度为1,我们得到的矩阵为:
以看到矩阵是对称矩阵,可以行或者列作为词表征。这个矩阵的意义在于假如两个词有相似的context则偏向于有相似的意思,也就是说相似的词有相似的词表征。
SVD(Singular Value Decomposition)
SVD,奇异值矩阵分解。对于任意一个矩阵$X$都可以做奇异值分解:
其中$U$和$V$都是正交矩阵,$S$只有对角元素:
其中$sigma_1…sigma_r$是矩阵$X$的奇异值。
LSA(Latent Semantic Analysis)
上述描述的两种矩阵中,都存在一个明显的问题-当出现大量的文档和词的时候,我们得到的矩阵会十分庞大,而且会出现矩阵稀疏问题。后来,有人为了提高相似度的计算准确度,提出了对矩阵进行SVD分解,可以得到更好的词表征。这种方法称为LSA,潜在语义分析。LSA是为了研究词表征,另外还有类似的研究文档表征的方法叫LSI(Latent Semantic Index)。 我们通过计数统计得到了词-文档矩阵或者词共现矩阵$X$,然后对矩阵$X$使用SVD,取最大的$k$个奇异值,由于每个奇异值对应于$U$的列,因此得到$hat{boldsymbol{U}}_{ntimes k}$,每一行代表一个词表征,因此可以得到$k$维的词表征。
优点:降低矩阵稀疏度 减少噪声
缺点:有新词或新的语料出现,矩阵需要重新计算 矩阵维度高
矩阵过于稀疏,很多词无法共现 会出现过高或过低的词频
Word Embedding 出现解决了上述问题。
基于迭代的词表征(词向量)
迭代的词表征得到的是一个稠密的向量,与矩阵分解不同的是,词向量是通过迭代训练模型得到。
NNLM
这个模型是由Bengio大神于2003年发表,可以说是Neural Language Model的开山之作。本来作者的主要目的是建立语言模型,结果发现了词向量这种副产品,由此引发了后人对词向量的火热研究。
模型使用了一个简单的前向神经网络,如下图所示:
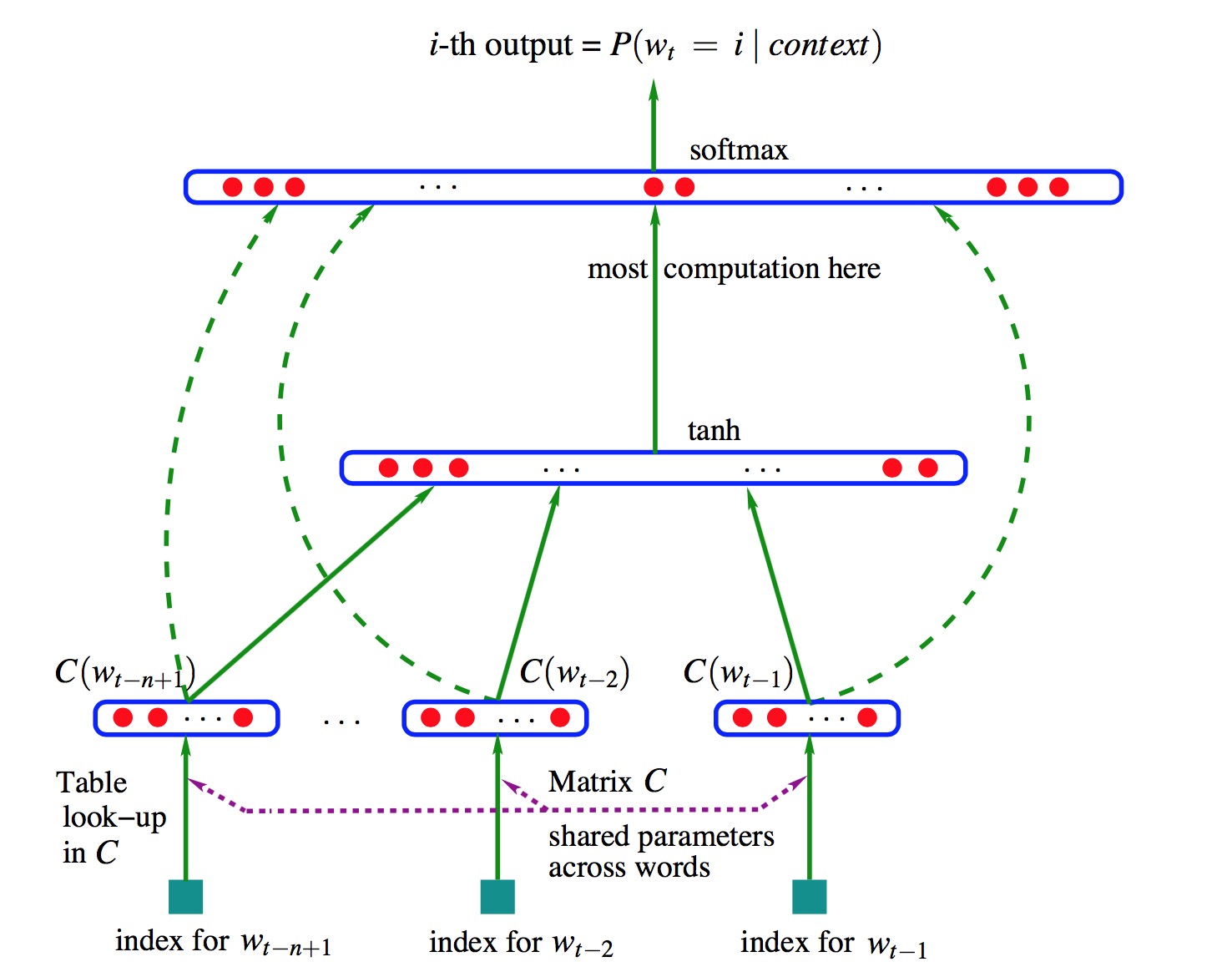
该模型通过上下文来预测下一个单词,图中所示的输入为上文的各个词$w_i$,然后将他们的词向量$C(w_i)$连接起来,输出是每个词的概率$P(w_t|content)$,虚线表示的是词向量层和输出层的直接连接。
Word2vec
Word2vec这个工具,是Tomas Mikolov在Google的时候开发的用来训练词向量的工具。Word2vec这个工具中有两个模型(CBOW、Skip-Gram),还有两种加速训练的trick(层次Softmax、负采样),下面分别一一讲述。
- $w$表示词
- $x$表示one-hot编码
- $u$和$v$表示词向量
- $x(w)$表示one-hot编码中对应词$w$位置的值,取值为0或1,只有一个位置上的值为1。
CBOW(Continuous Bag-of-word Model)
模型的网络结构如下:
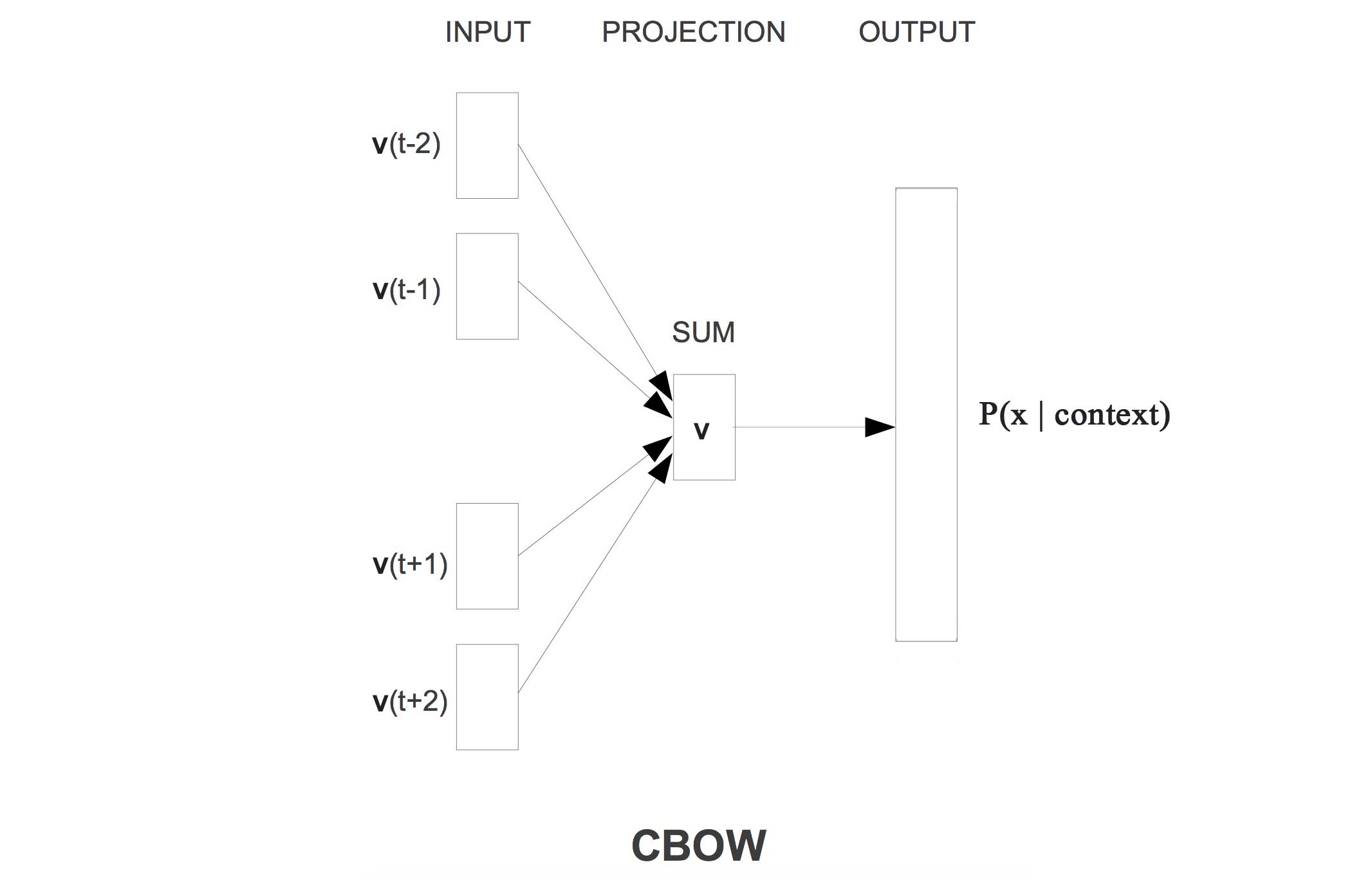
说明:
模型中存在两套词向量。
一套称为Input词向量,用矩阵$V_{|V|times d}=(v_1,dots,v_{|V|})$表示,|V|指的是词表大小,d指词向量维度
一套称为Output词向量,用矩阵$U_{|V|times d}=(v_1,dots,v_{|V|})$表示
建模过程
确定一个窗口大小m
选定目标词位置t。得到该位置的上下文:
得到上下文各个词的one-hot表示:
使用矩阵$V$,计算$v = Vx$得到上下文的词向量(对于图中的INPUT层)
将上下文的词向量相加或者平均,得到。(对应图中的PROJECTION层):
使用矩阵$U$,计算目的词的概率分布(对应图中的OUTPUT层):
使用负对数似然(又称交叉熵)损失函数$J$:
训练过程
选取batch的大小n
使用SGD训练,对于每个训练样本的损失函数$J_i$,构造batch的损失函数:
每一轮迭代更新$U$和$V$
Skip-Gram(Continuous Skip-gram Model)
既然可以用上下文来预测目标词,反过来也能用目标词来预测上下文,Skip-Gram因此应运而生。
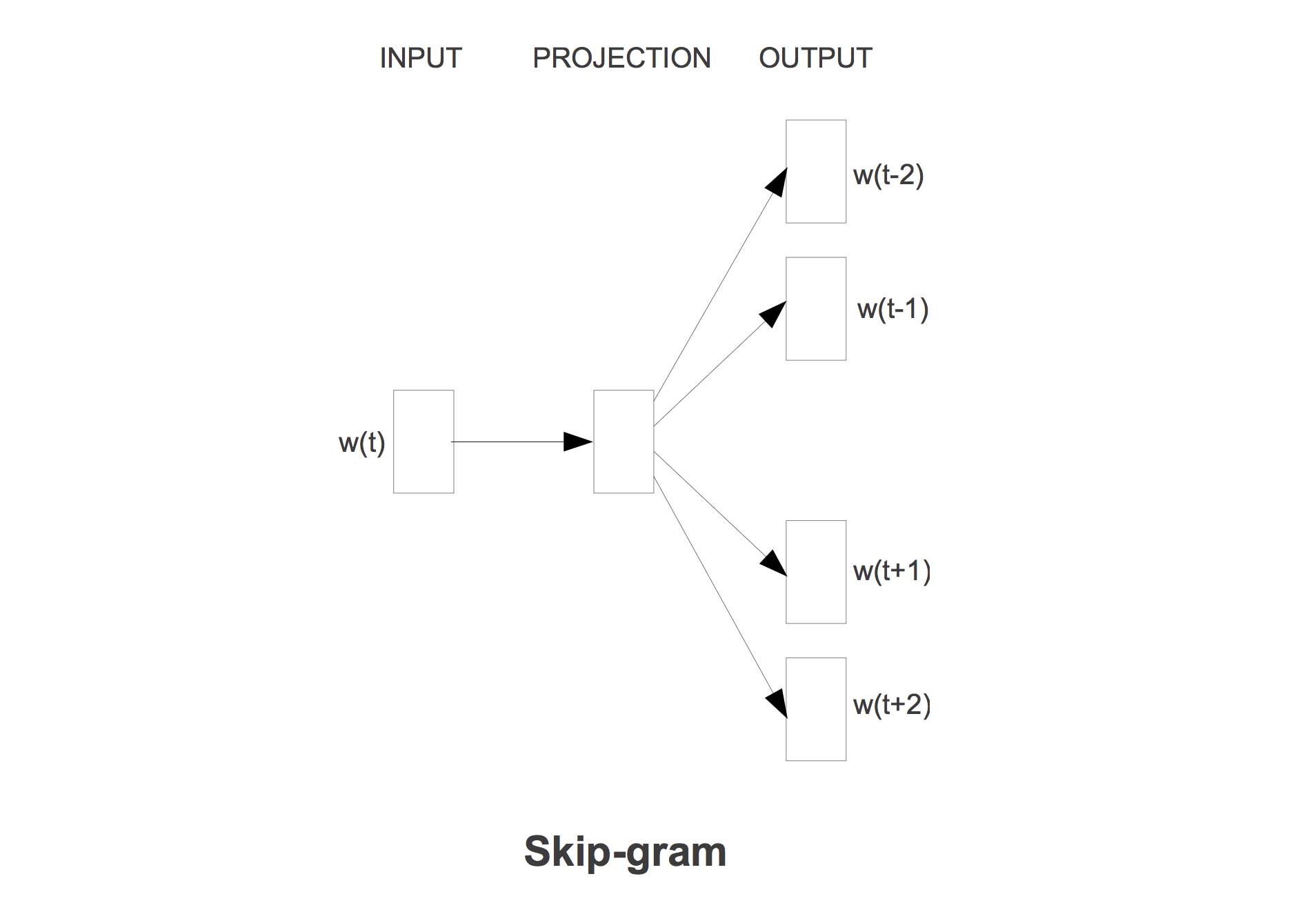
与CBOW一样,模型中存在两套词向量$U$和$V$。
建模过程
确定Context的窗口大小$m$。
选取一个目标词$w^t$,然后在目标词的Context中的选择一个词$w^c$,组成训练样本:
得到训练样本one-hot表示为:$(x^t,x^c)$
使用矩阵$V$,得到目标词的词向量(对应图中INPUT层):$v^t = c^tV$
由于只有一个词,所以不需要相加或者平均,直接复制到下一层(对应PROJECTION层): $hat{v} = v^t$
使用矩阵$U$,计算上下文中的词的概率分布(对应图中的OUTPUT层):
使用负对数似然(又称交叉熵)损失函数$J$:
训练过程
选取batch的大小n
使用SGD训练,对于每个训练样本的损失函数$J_i$,构造batch的损失函数:
每一轮迭代更新$U$和$V$
加速技巧
Word2vec的训练是无监督的,我们只需要分好词,在训练的时候像有监督一样进行梯度下降。因此,在训练模型的时候,我们需要同时更新$U$和$V$。
从公式可以看出,每次迭代只需要更新矩阵中的少量向量(Skip-Gram中是一个)。然而如果我们使用简单的Softmax,我们就要每次都更新整个$U$,假如词表大小到达千万级以上,可想而知这是多么耗时。因此,我们需要一些Trick来加速训练。
以上是关于词向量的主要内容,如果未能解决你的问题,请参考以下文章