合理使用Order by 重要性
Posted weixiaotao
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了合理使用Order by 重要性相关的知识,希望对你有一定的参考价值。
案例场景
表数据量7000+万,其中满足如下条件的数据量约为:1200条。走主键索引的查询未必是最优的。见如下案例:
#表索引说明
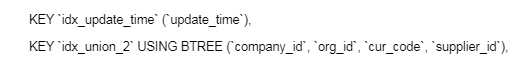

案例分析
分别查看sql的执行计划
1、无limit 、无order by

2、limit 2000

3、order by id,add_time limit 2000

4、order by id limit 2000

从执行计划来看,order by id limit 2000 时候,mysql查询引擎遍历的rows最小为4万(其他均为3000+万)甚至order by id,add_time 时还出现了 filesort,表面看来
order by id limit 2000时候,应该是最理想的查询方式。可实际执行起来恰恰相反。
案例总结
1.走主键索引的场景(order by id limit 2000)
表明通过id 索引 根据索引树从最右侧叶子节点依次按顺序获取n条与where条件进行过滤,直到获取2000条数据,并没有真正通过id作为条件去筛选数据,而是用where条件筛选,由于根据id 顺序匹配数据,如果该数据不满足where会继续获取,直到满足2000条,这样就会导致访问数据量过大。极端情况如果第2000条数据为表的最后一条数据,则会扫描全表。
可理解 执行顺序是:order by --> where--> limit
2.走组合索引的场景(order by id,add_time limit 2000)
使用limit 时执行计划会使用组合索引,进行条件筛选,在Extra中显示Using index condition;Using where ;Using filesort; 优化器首先解析索引列;通过索引列(union_2)找出表中行数据,在获取其他where条件进行筛选(索引向下),获取到与条件匹配行后进行order by排序,由于没有使用排序索引索引使用了Using filesort进行文件排序,【一般情况下文件排序会导致增加消耗,查询时缓慢,不过不能一概而论】,最后根据limit 获取指定行数
可理解 执行顺序是:where --> order by --> limit
每个索引在数据库中都是一个索引树,其数据节点存储了指向实际数据的指针,如果用一个索引来查询,其原理就是从索引树上去检索,并获得这些指针,然后去取出数据,如果通过一个索引(id),得到过滤后的指针,这时,你的另一个条件索引(union_2)如果再过滤一遍,将得到2组指针的集合,如果这时候取交集(order by id 场景),未必就很快,因为如果每个集合都很大的话,取交集的时候,等于扫描2个集合,效率会很低,所以没法用2个索引。
当然有时候mysql会考虑临时建立一个联合索引,将2个索引联合起来用,但是并不是每种情况都能奏效,同样的道理,用一个索引检索出结果集之后,排序时,也无法用上另一个索引了(order by id,add_time 场景)。
最后在不同情况下优化器选择索引不同,优化需根据不同场景进行优化,我们也需要根据不同的场景创建最优的索引。
以上是关于合理使用Order by 重要性的主要内容,如果未能解决你的问题,请参考以下文章