Prometheus+Grafan监控k8s集群详解
Posted
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了Prometheus+Grafan监控k8s集群详解相关的知识,希望对你有一定的参考价值。
一,Prometheus概述1,什么是Prometheus?
Prometheus是最初在SoundCloud上构建的开源系统监视和警报工具包,自2012年成立以来,许多公司和组织都采用了Prometheus,该项目拥有非常活跃的开发人员和用户社区。现在,它是一个独立的开源项目,并且独立与任何公司维护。为了强调这一点并阐明项目的治理结构,Prometheus在2016年加入了 Cloud Native Computing Foundation(云原生计算基金会(CNCF)),这是继kubernetes之后的第二个托官项目。
2,Prometheus的优势
Prometheus 的主要优势有:
- 由指标名称和键/值识别时间序列数据组成的多维数据模型。
- 强大的查询语言 (PromQL)
- 不依赖分布式存储;单个服务节点具有自治能力。
- 通过基于HTTP的拉取方式采集时间序列数据。
- 可以通过中间网关来推送时间序列数据。
- 可以通过静态配置文件或服务发现来获取监控目标。
- 支持多种类型的图标和仪表盘,比如Grafana等。
3,Prometheus的核心组件
Prometheus生态系统有多个组件组成,其中有许多组件是可选的:
- Prometheus Server:用于收集指标和存储时间序列数据,并提供查询接口。
- client Library:客户端库(例如Go,python,java等),为需要监控的服务产生相应的/metrics(服务指标度量)并暴露给Prometheus server。
- push gateway:推送网关,主要用于临时性的jobs。由于这类jobs存在时间较短,可能在Prometheus来pull之前就消失了,对此jobs定时将指标push到pushgateway,再由Prometheus server从pushgateway上pull。
- Exporter:用于暴露已有的第三方服务的 metrics 给Prometheus。
- alertmanager:用来处理告警,从Prometheus server端接收警告后,会进行去除重复数据,分组,并路由到对收的接收方式,发出报警。最常见的接收方式:电子邮件。
4,Prometheus的架构
Prometheus 的整体架构以及生态系统组件如下图所示: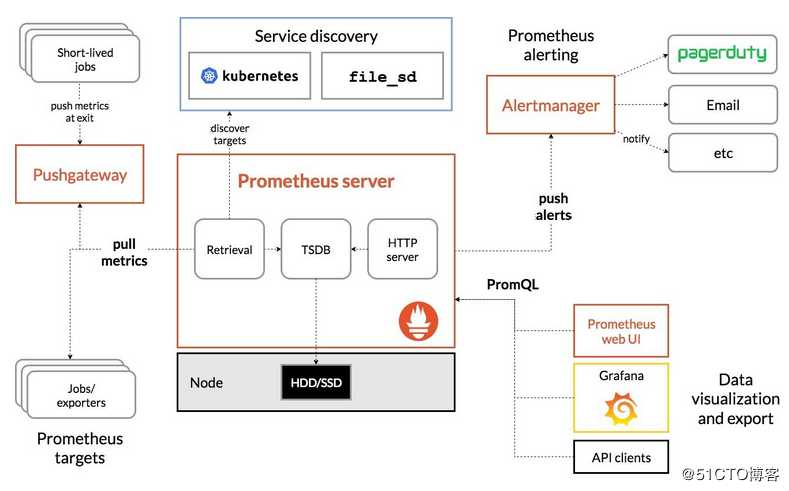
Prometheus server直接从监控目标中或者间接通过推送网关来拉取监控指标,它在本地存储所有抓取到的样本数据,并对此数据执行一系列规则,以汇总和记录现有数据的新时间序列和生成告警。可以通过Grafana或者其他工具来实现监控数据的可视化。
5,Prometheus的优缺点
Prometheus对于采集纯数字值的时间序列非常在行,所以它适合以物理机为中心的监控,也适合监控高度动态的面向服务的架构体。在微服务领域,它的多维数据采集以及查询非常独到且很有竞争力。
Prometheus最大的价值在于可靠性,用户可以再任何时候看到整个被监控系统的统计信息,即使在系统有问题的是时候。但它不能做到100%的精确,比如如果你要按请求数据计费,那么Prometheus不太适合你,因为它收集的数据可能不够详细完整。这种情况下你最好使用其他系统来收集和分析数据以进行计费,并使用Prometheus来监控系统的其余部分。
二,Prometheus部署
部署环境:
| 节点名 | 主机ip | 操作系统 |
|---|---|---|
| master | 172.16.1.30 | Centos7 |
| node01 | 172.16.1.31 | Centos7 |
| node02 | 172.16.1.32 | Centos7 |
1,获得Prometheus的git项目:
1)安装git工具包:
[root@master ~]# yum install git -y2)获取Prometheus的git项目:
[root@master prometheus]# git clone https://github.com/coreos/kube-prometheus.git

#执行git pull命令进行更新,确保克隆到本地的是最新的:
[root@master kube-prometheus]# git pull
Already up-to-date.2,导入部署Prometheus所需组件镜像:
1)在集群中的所有node上进行上传镜像包(包括master)
2)分别在集群中的node上进行load操作:
#注意:确定在当前路径下执行
[root@master images]# for i in `ls`; do docker load < $i; done
[root@node01 images]# for i in `ls`; do docker load < $i; done
[root@node02 images]# for i in `ls`; do docker load < $i; done以上镜像都是我通过国内阿里云镜像站下载好的(已修改tag),我已上传至网盘,大家可以去进行下载:链接:https://pan.baidu.com/s/1c8pP3vAS9qHCQqc-XaYRXQ
提取码:8zk2
注意:
考虑到以上组件的镜像版本在git项目上会经常的更新,所以大家就得根据最新版本去下载相对应的镜像;yaml文件中默认是从quay.io和gcr.io进行镜像拉取(其他的国内可直接拉取),我们知道,国内访问外网是被屏蔽的,我们无法直接将镜像下载下来,所以可以分别通过 quay-mirror.qiniu.com 和 registry.aliyuncs.com镜像站去拉取。
###例如:
拉取镜像:quay.io/coreos/prometheus-operator:v0.36.0
可以改为:quay-mirror.qiniu.com/coreos/prometheus-operator:v0.36.0
拉取镜像:gcr.io/google_containers/kube-proxy
可以改为:registry.aliyuncs.com/google_containers//kube-proxy
3,修改访问模式为nodeport
1)修改grafana-service文件:
[root@master kube-prometheus]# cd manifests/
[root@master manifests]# vim grafana-service.yaml 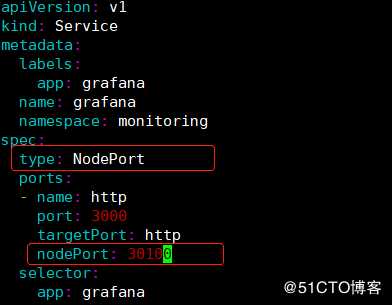
2)修改Prometheus-service文件:
[root@master manifests]# vim prometheus-service.yaml 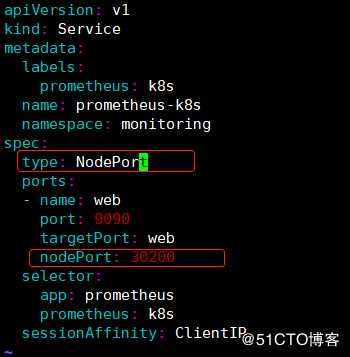
3)修改alertmanager-service文件: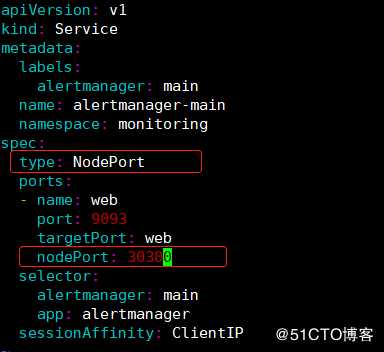
4,执行安装操作
1)先安装Prometheus所需要的资源(在manifests/setup目录下的yaml文件):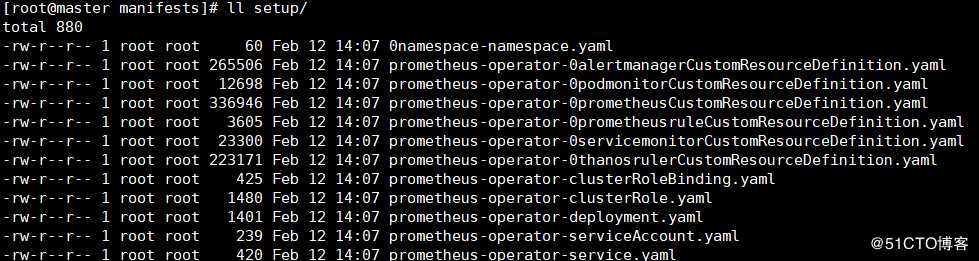
[root@master manifests]# kubectl apply -f setup/2)安装Prometheus(在manifests/路径下的yaml文件):
[root@master manifests]# cd ..
[root@master kube-prometheus]# kubectl apply -f manifests/5,查看Prometheus资源(确保以下pod都达到所期望的状态值)[root@master kube-prometheus]# kubectl get pod -n monitoring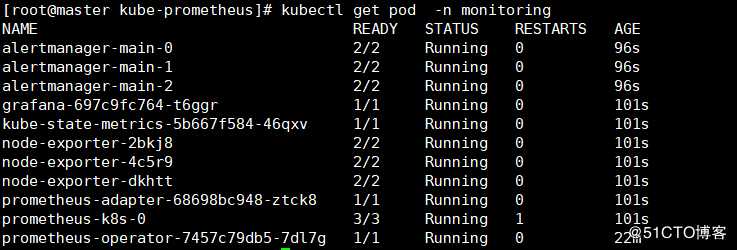
[root@master kube-prometheus]# kubectl get svc -n monitoring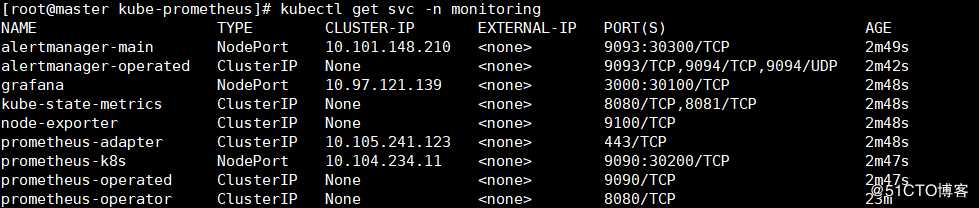
以上各组件说明:
- MerticServer: k8s集群资源使用情况的聚合器,收集数据给k8s集群内使用;如kubectl,hpa,scheduler等。
- PrometheusOperator:是一个系统监测和警报工具箱,用来存储监控数据。
- NodeExPorter:用于各个node的关键度量指标状态数据。
- kubeStateMetrics:收集k8s集群内资源对象数据,指定告警规则。
- Prometheus:采用pull方式收集apiserver,scheduler,control-manager,kubelet组件数据,通过http协议传输。
- Grafana:是可视化数据统计和监控平台。
6,Prometheus监控页面展示
1)访问Prometheus web页面:
访问url:http://172.16.1.30:30200/ 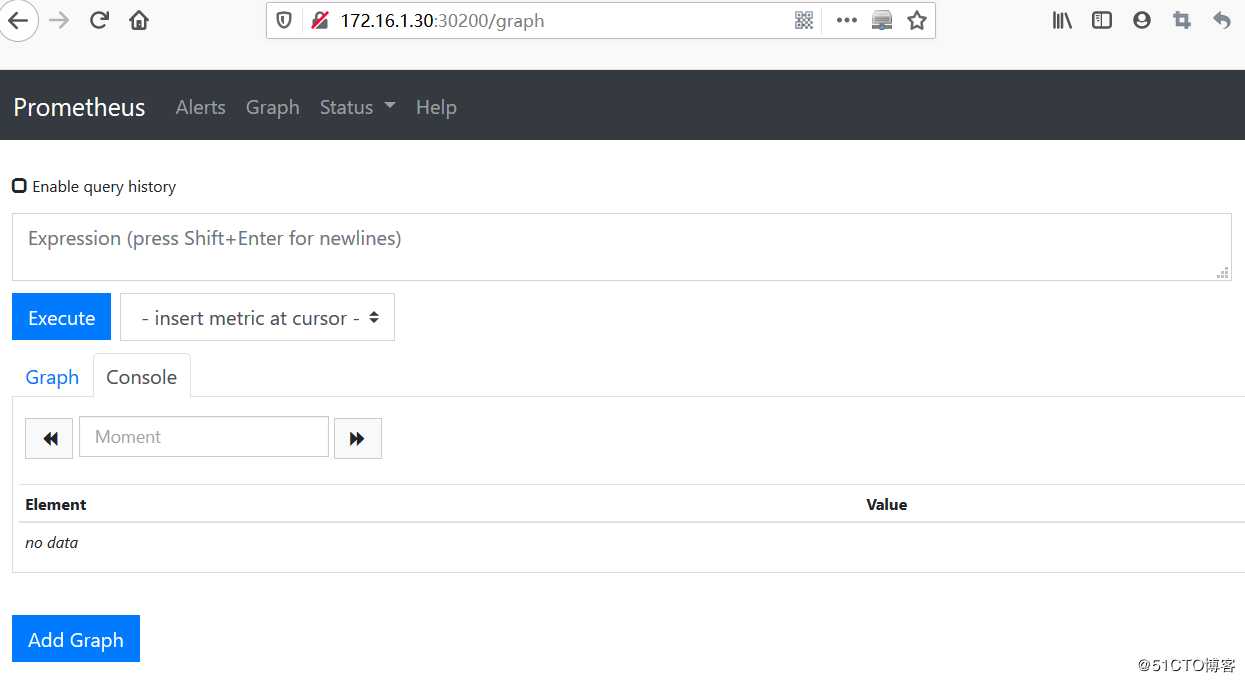
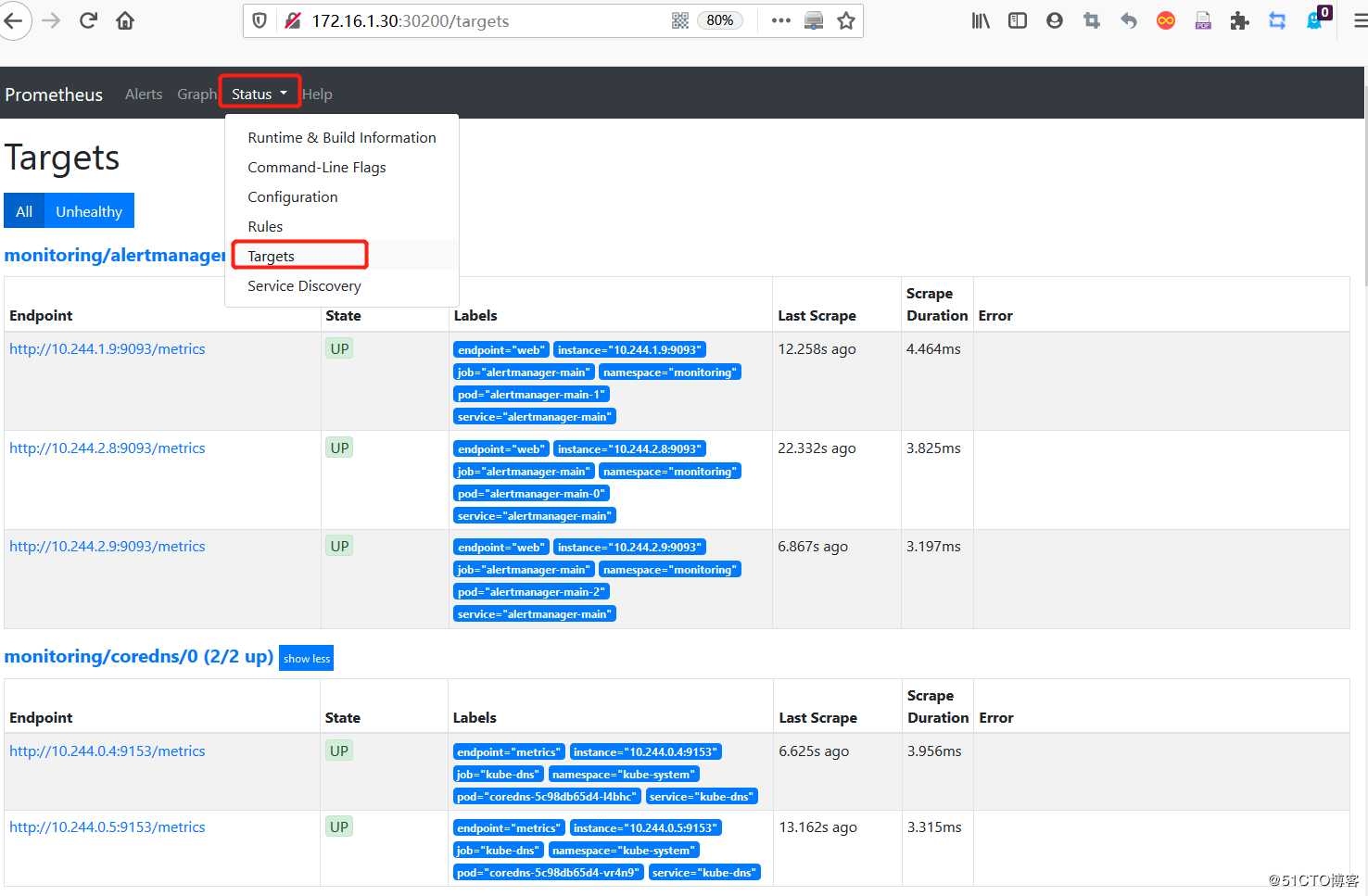
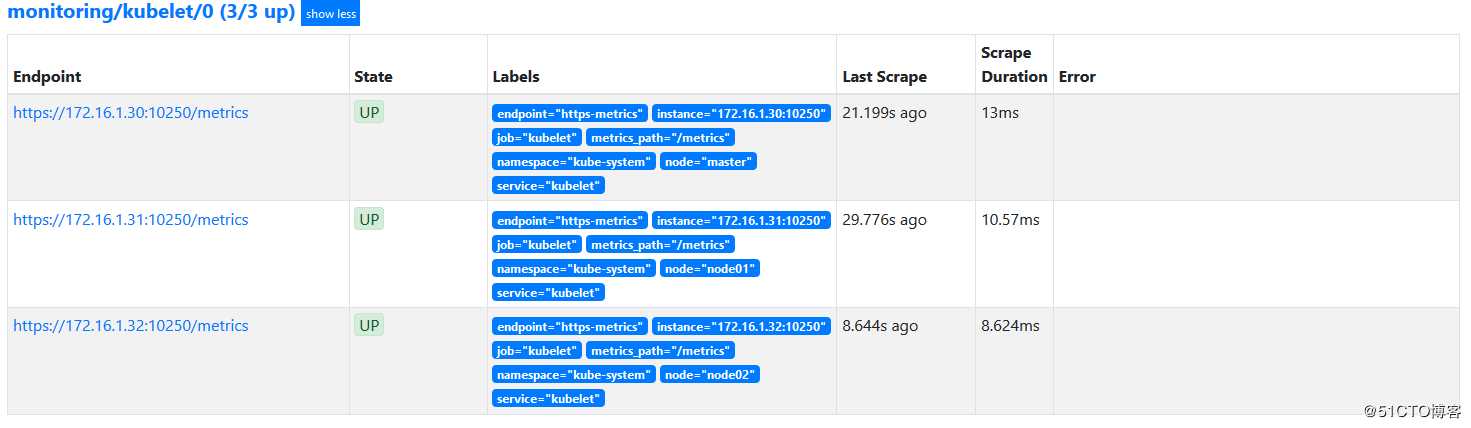
#部署成功后,会显示集群节点各个组件的详细信息,并且状态为up。
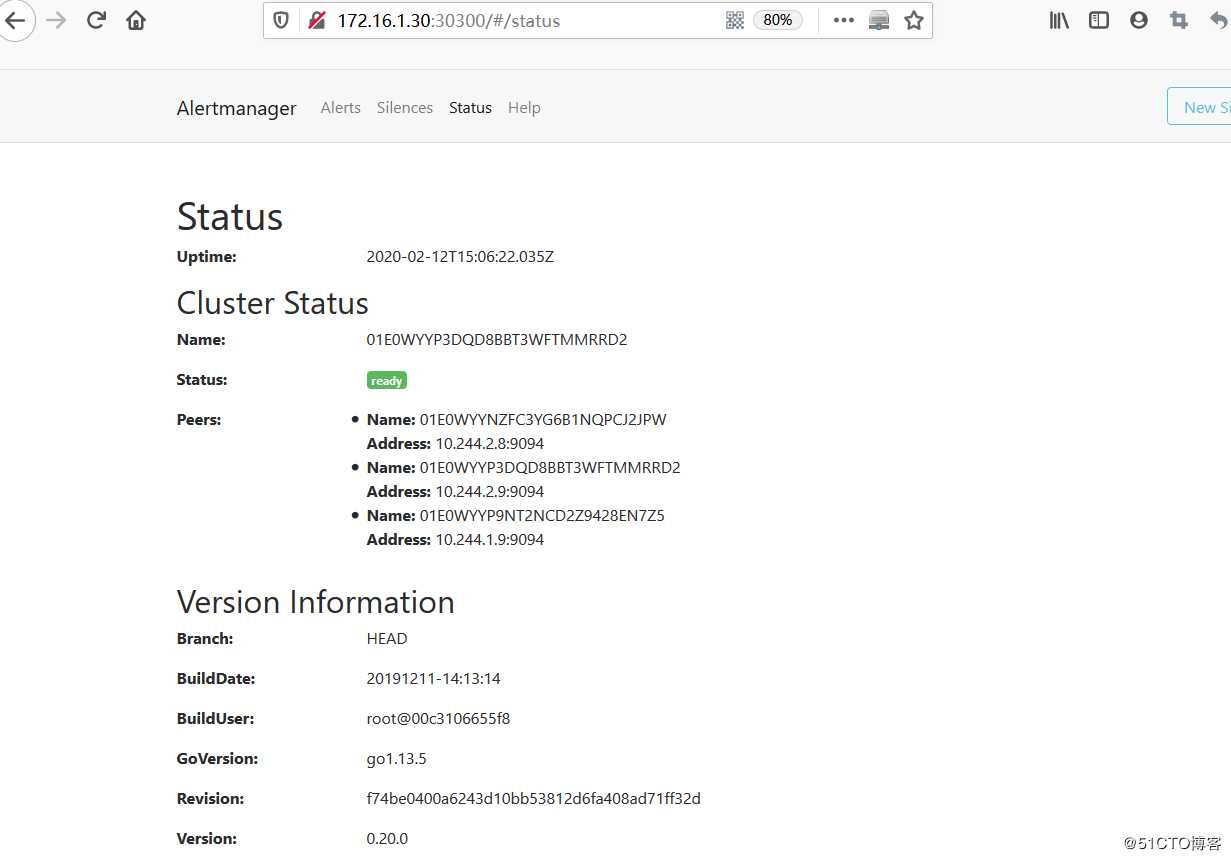
2)访问alertmanager web页面:
访问url: http://172.16.1.30:30300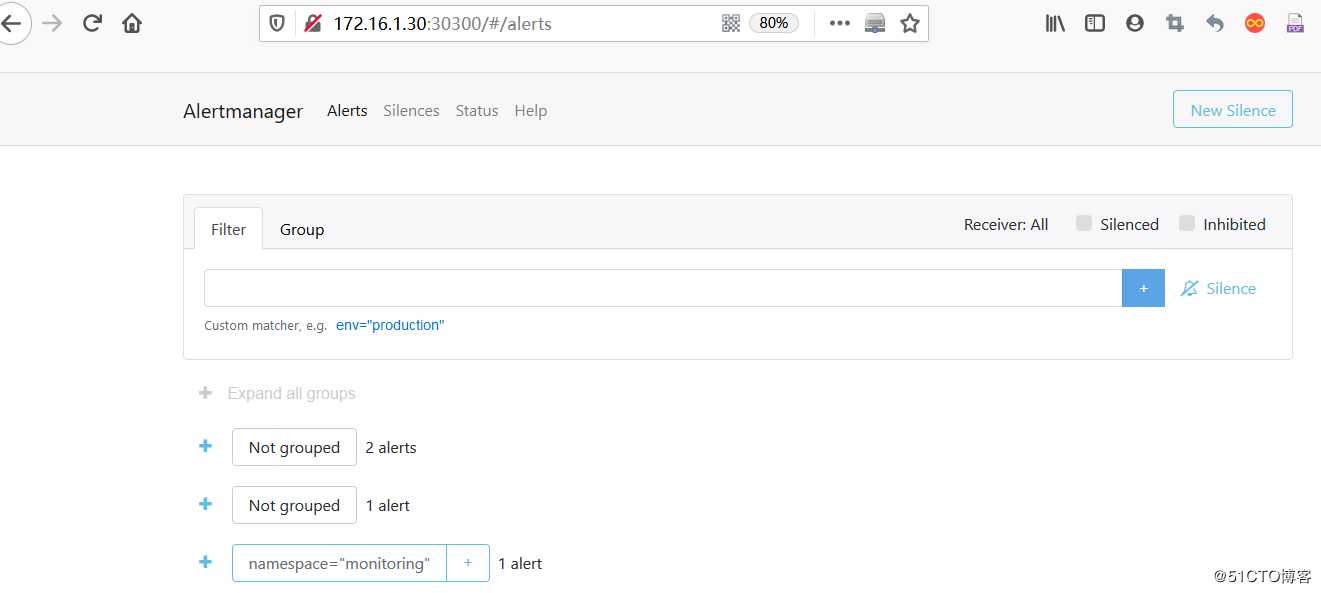
3)访问Grafana 图形化界面:
访问url: http://172.16.1.30:30100 , 初始用户名和密码都为:admin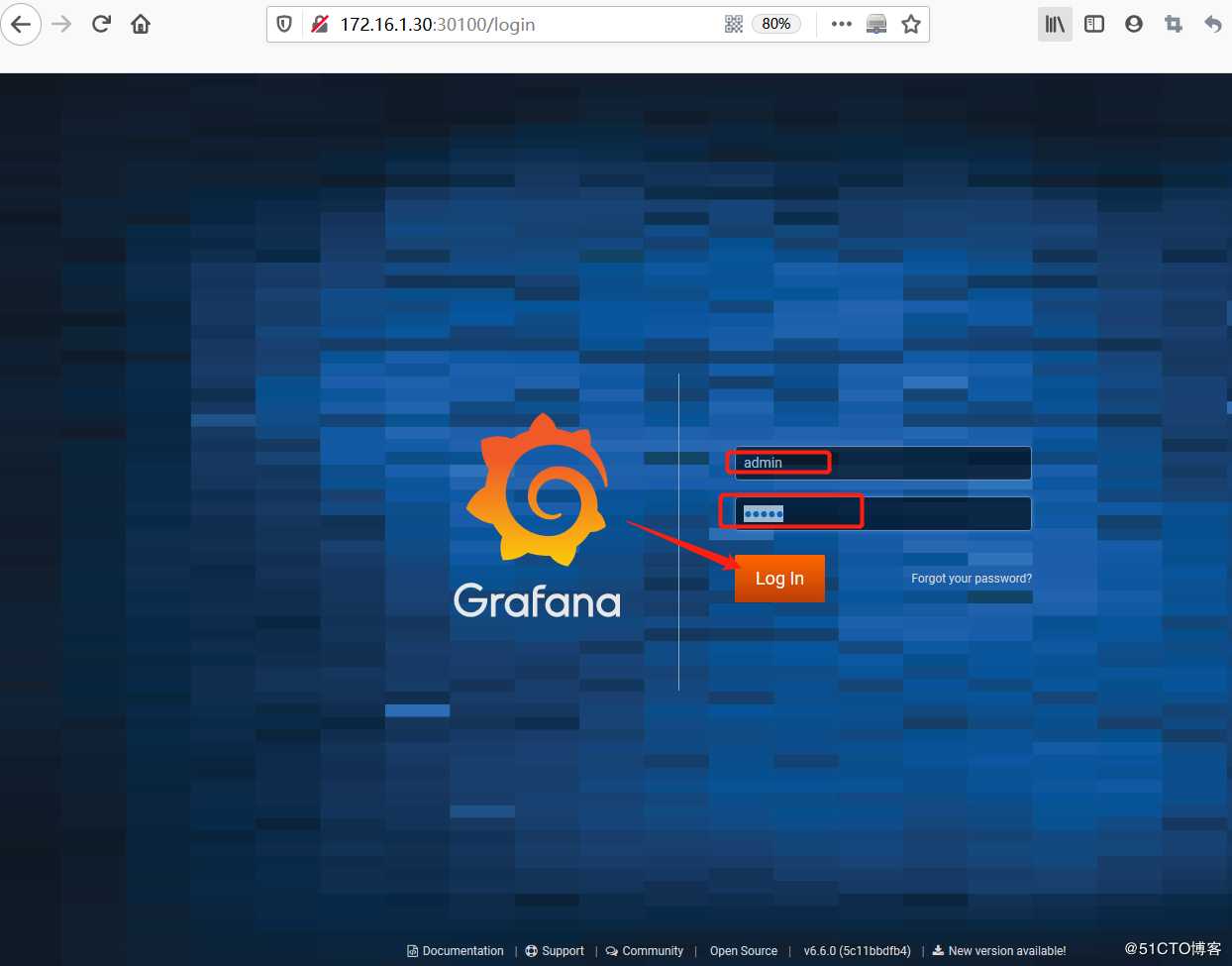
#修改用户名和密码后点击登录: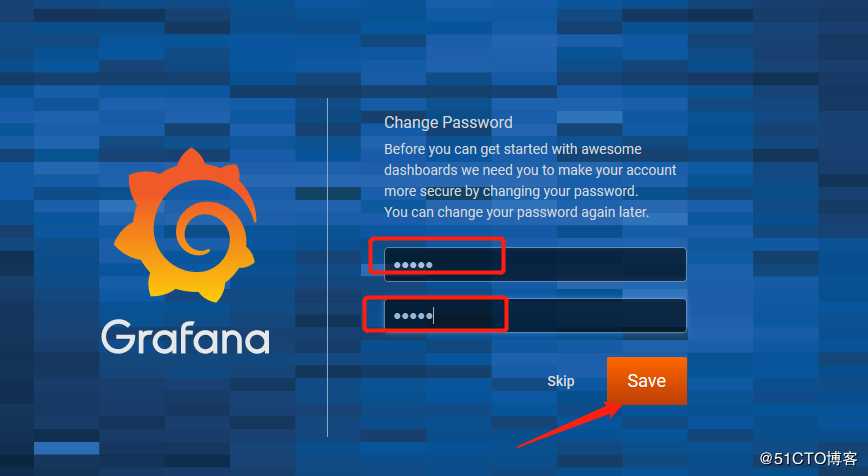
三,使用Prometheus监控平台
1,为grafana添加Prometheus数据源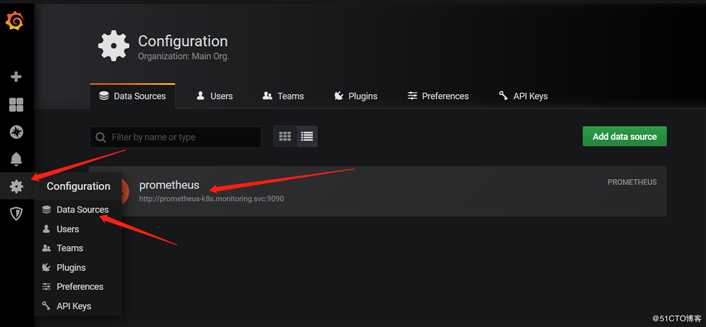
上图所示,可以看到当部署完Prometheus后默认已经为我们添加了一个Prometheus数据源,大家也可以点击右上角的"Add data source"选项自定义添加所需要的数据源。如下图所示: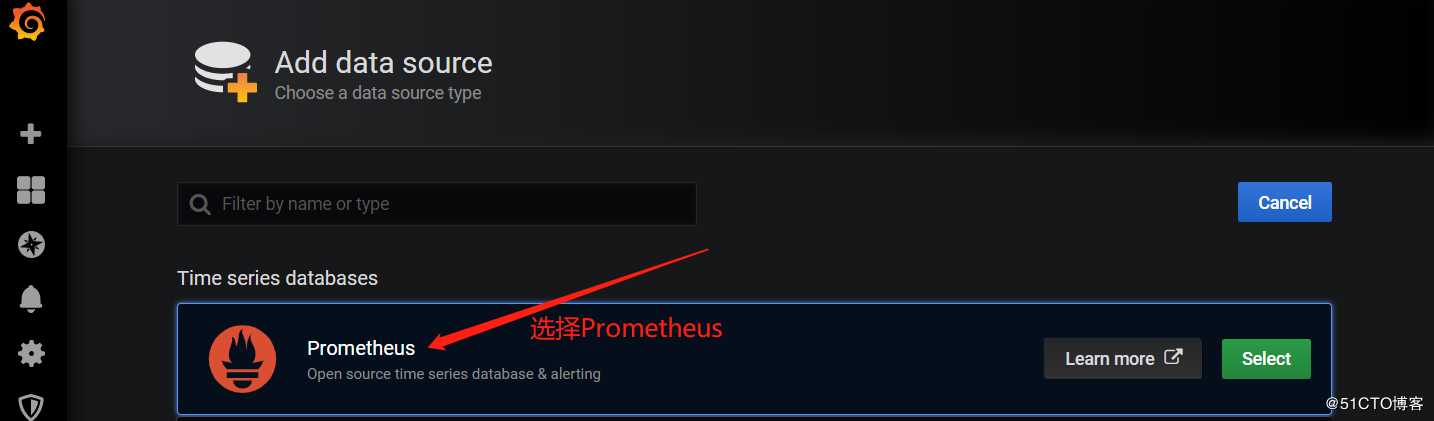
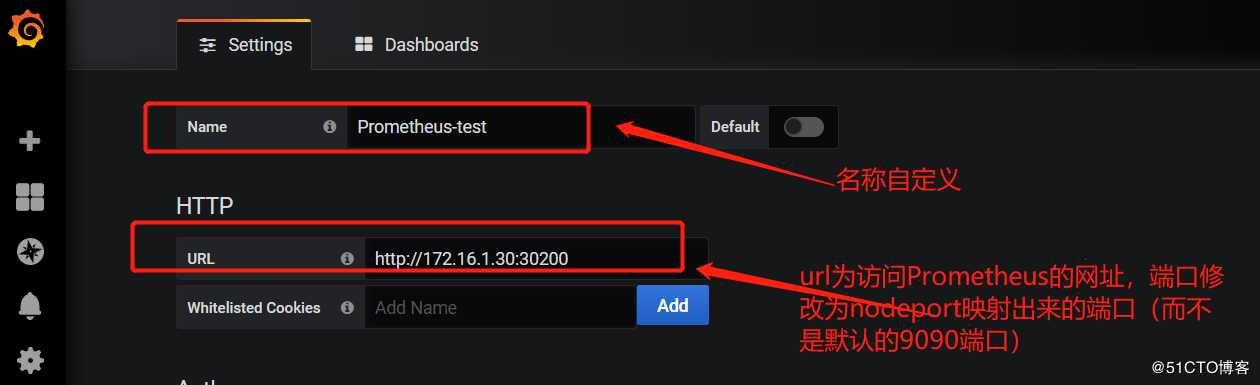
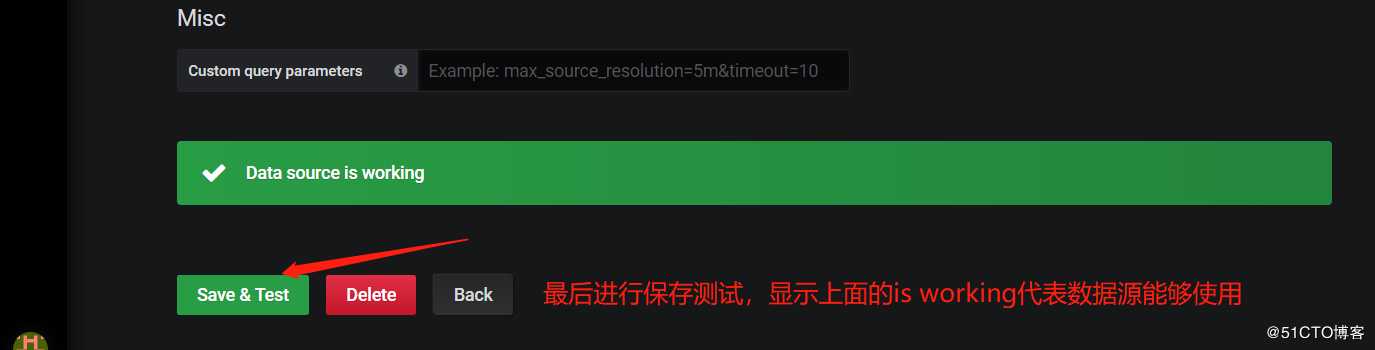
2,为grafana添加dashboard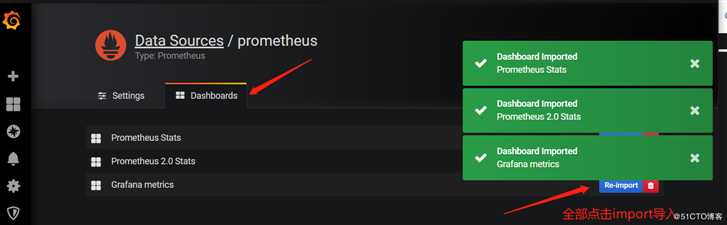
3,监控集群资源
如上图所示,已为我们提供了一些内置资源监控模板,大家可以选择查看需要监控的资源。下面将展示几个重要监控的资源对象信息:
1)查看集群资源信息: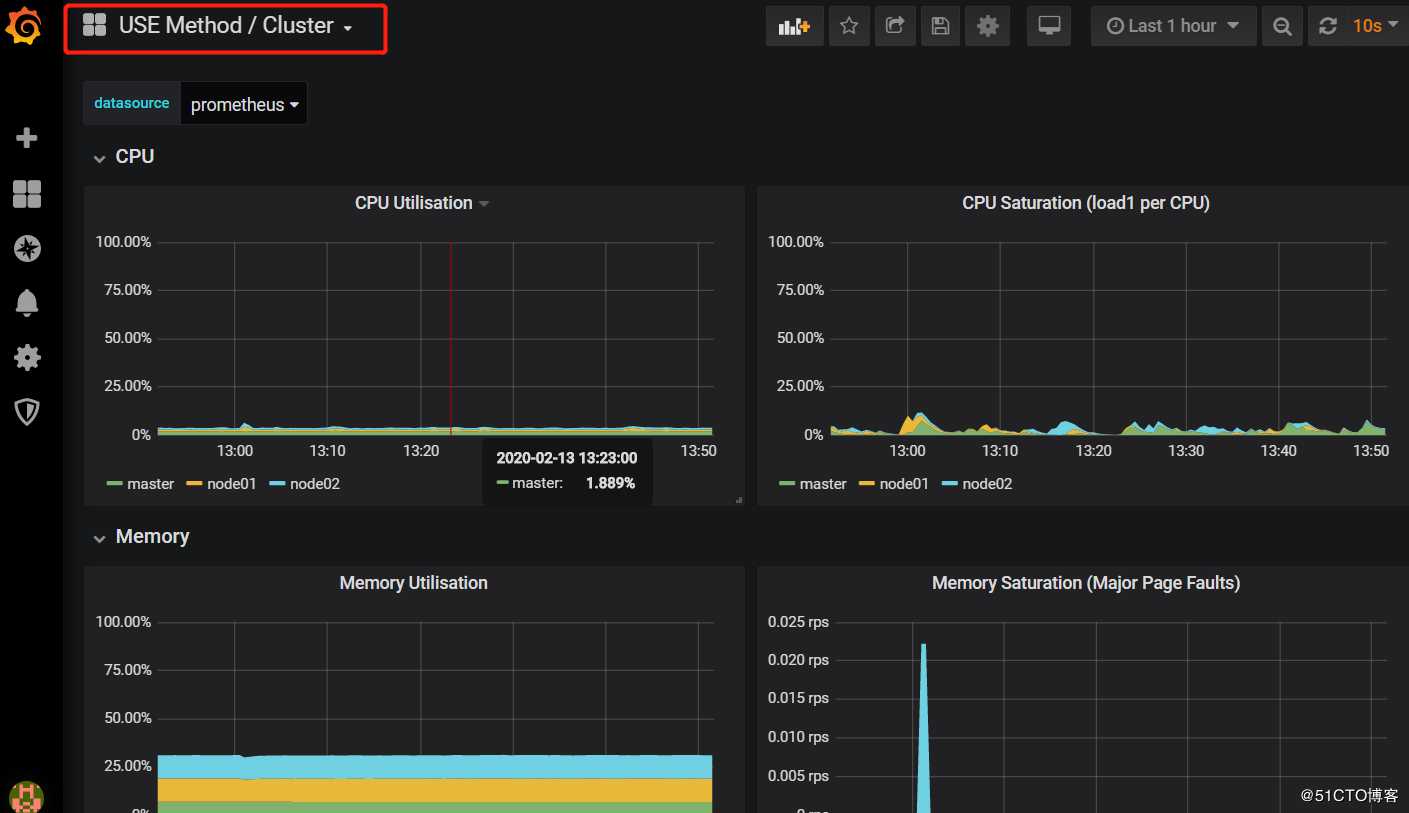
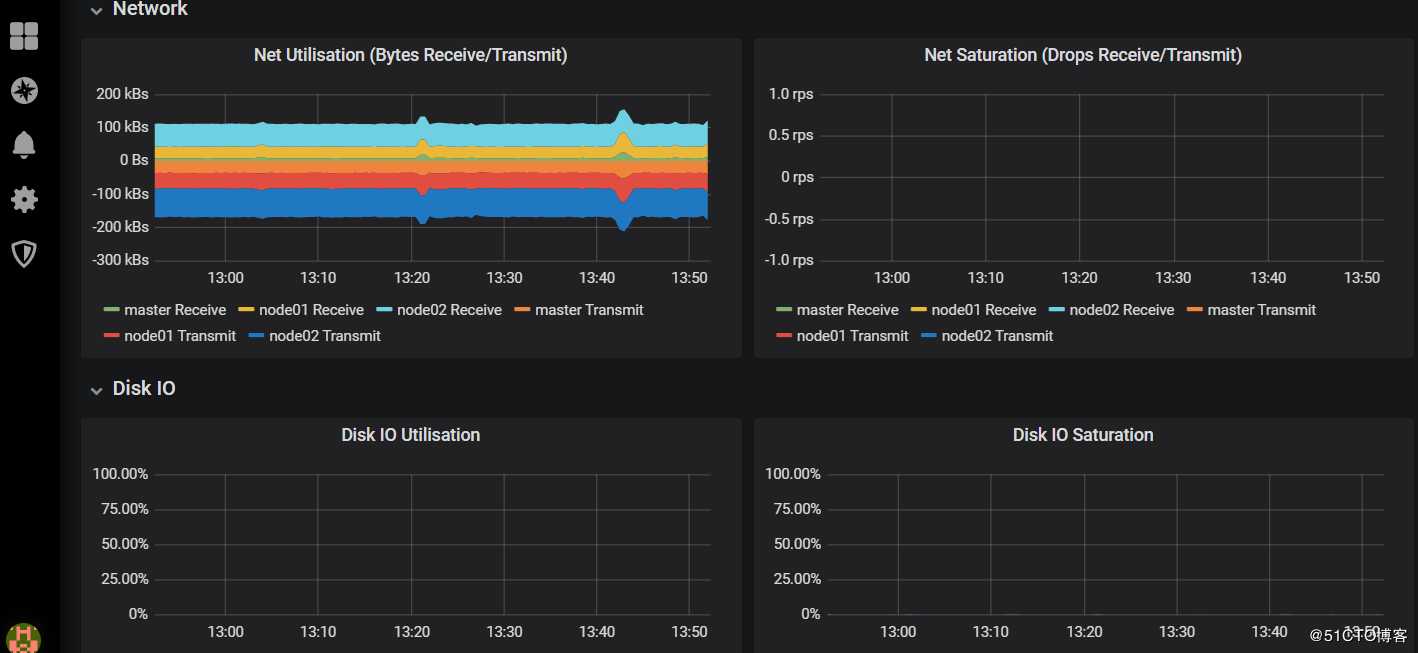
#可以看到集群中cpu,memory,network以及磁盘IO等使用信息的展示。
2)查看各个节点资源的使用情况: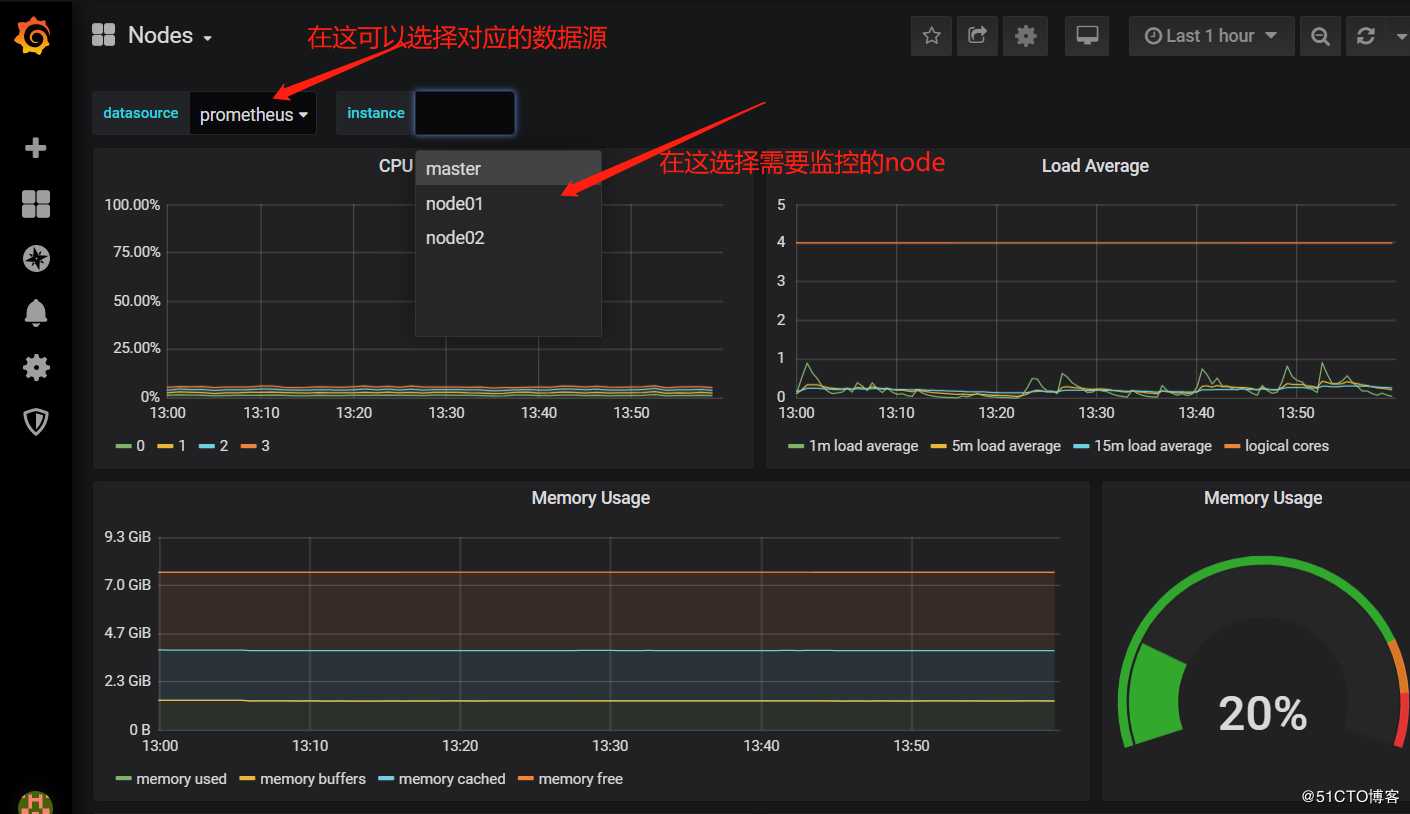
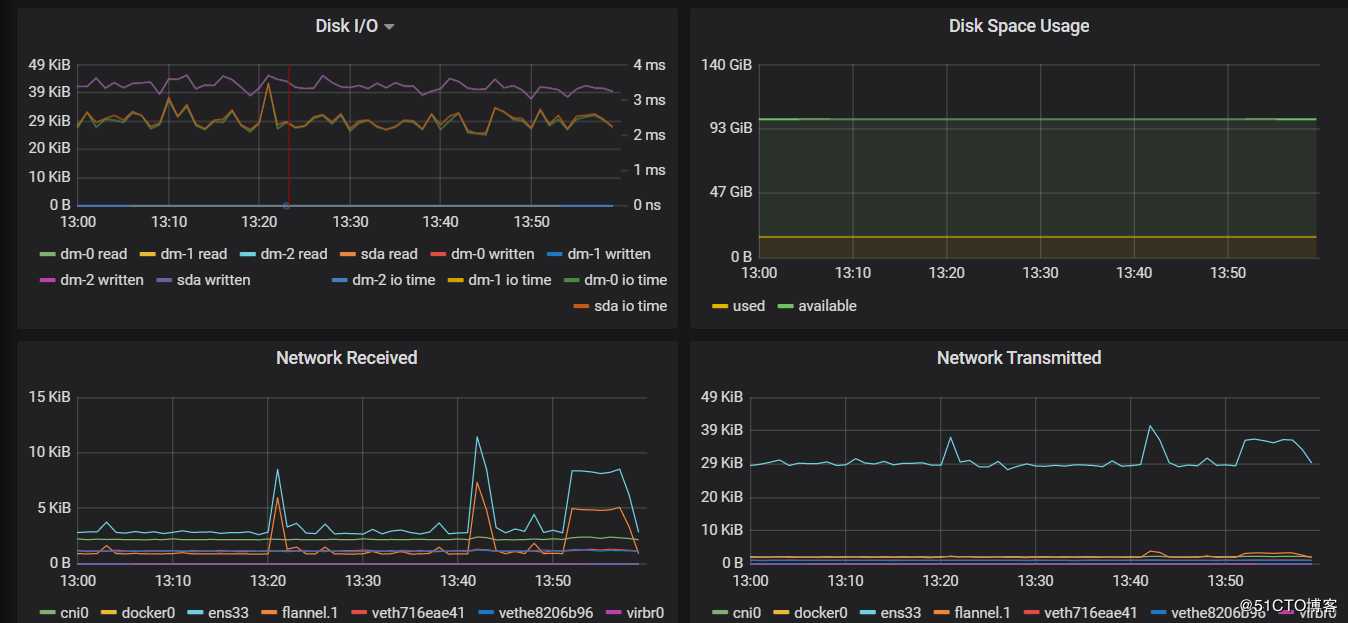
3)Pod资源查看: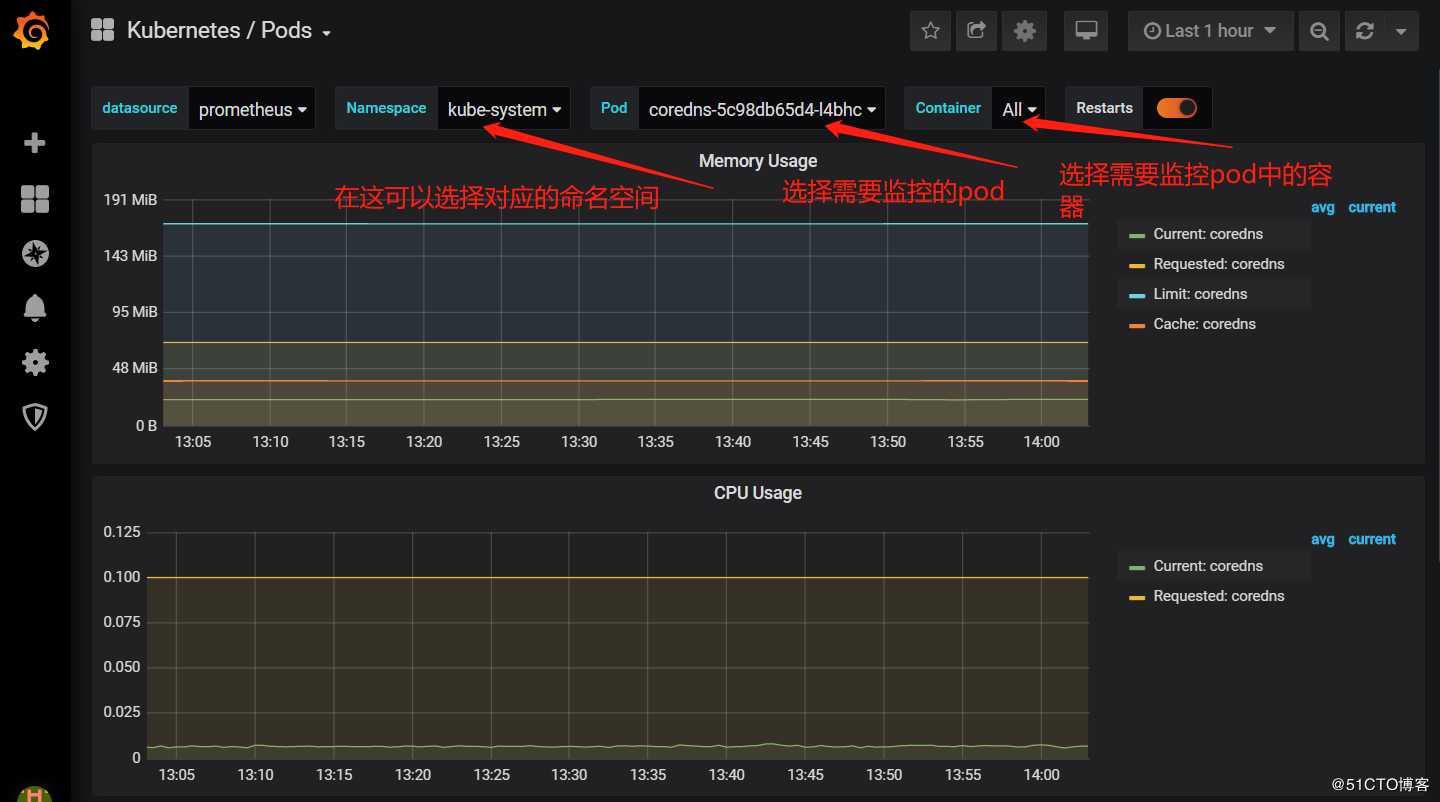
#如上所示,可以看到Prometheus为我们提供的资源监控项还是非常全面的。其他资源监控项大家可以自行查看。
4,其他监控模板
grafana提供自带的监控模板是非常丰富的,不过我们也可以进入Grafana官网下载其他监控模板。
1)下载监控模板,如下图所示:
比如,我们选择Node Exporter for Prometheus 模板: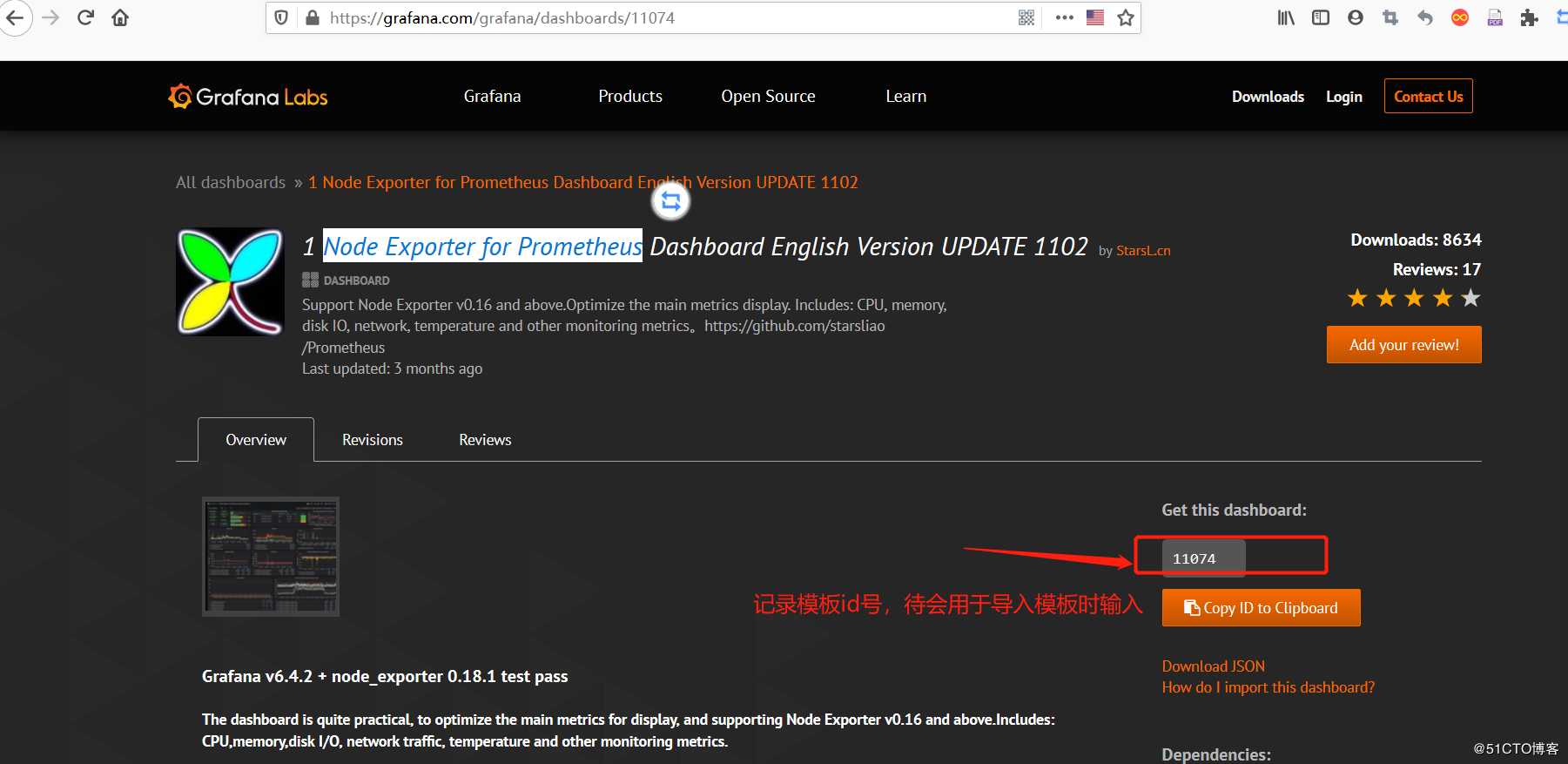
2)在Grafana web界面上导入模板: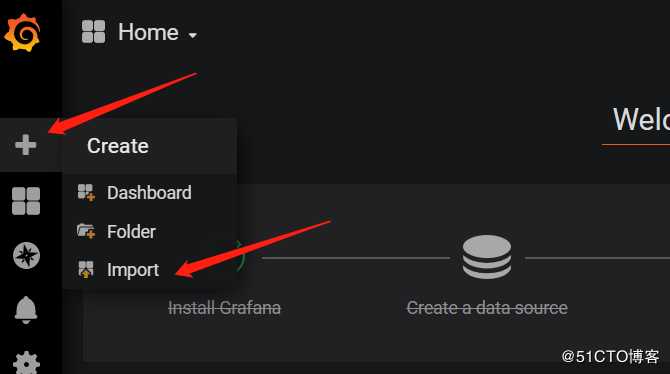
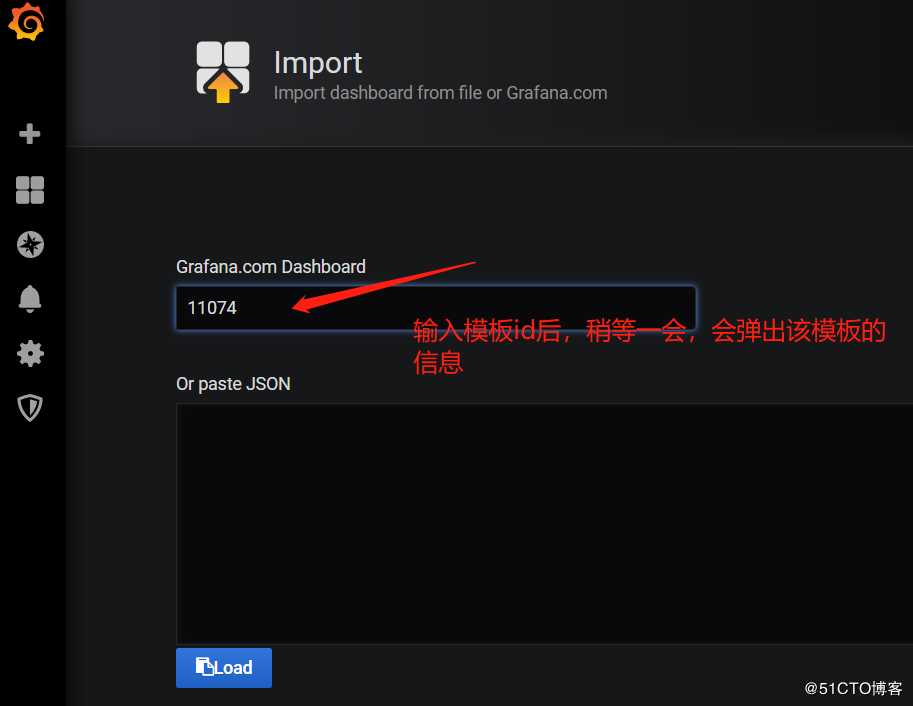
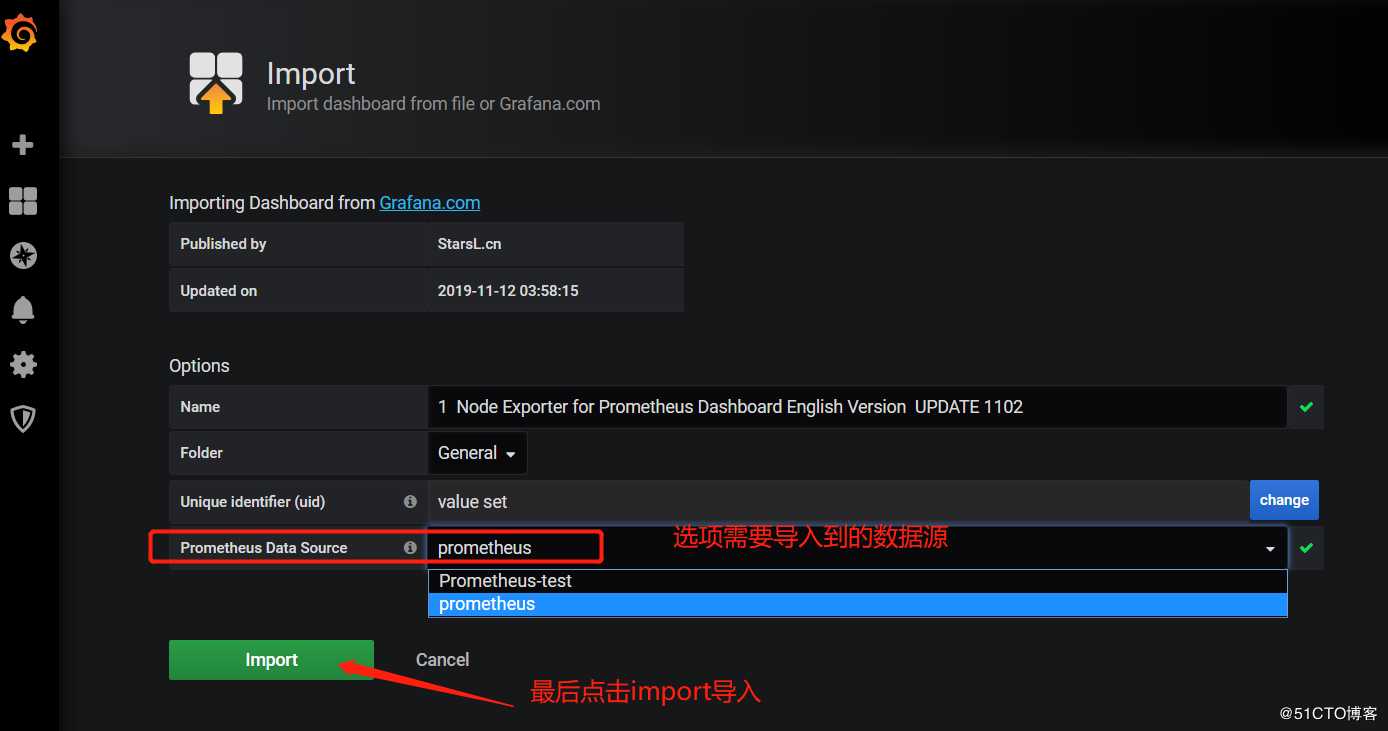
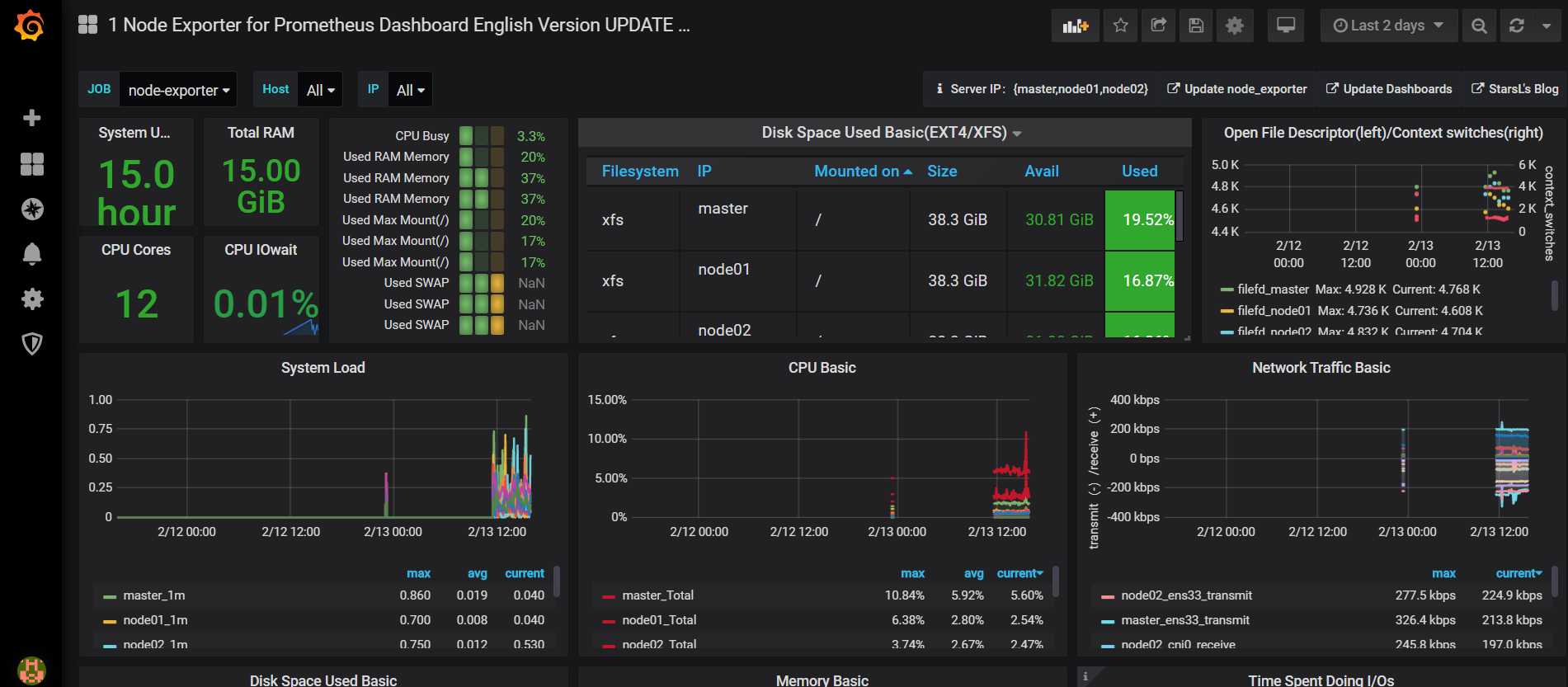
模板导入成功,其他类型的监控模板大家可以自己在Grafana官网上去下载。
Alertmanager实现邮箱告警可参考博文:监控利器-Prometheus安装与部署+实现邮箱报警
以上是关于Prometheus+Grafan监控k8s集群详解的主要内容,如果未能解决你的问题,请参考以下文章