HashMap一问一答
Posted cmg219
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了HashMap一问一答相关的知识,希望对你有一定的参考价值。
参考博文一文读懂HashMap , 深入浅出学Java——HashMap
上面两篇文章介绍的jdk1.7的hashmap实现与原理,写得十分清楚,建议阅读。
在写了几篇随笔后,发现我只是阐述原理,却没有认真细下心来分析为什么要这样做,这样做有哪些好处。接下来,我打算已问答的方式来完成这边随笔。
1.HashMap是什么
Hash table based implementation of the <tt>Map</tt> interface. This
implementation provides all of the optional map operations, and permits
<tt>null</tt> values and the <tt>null</tt> key. (The <tt>HashMap</tt>
class is roughly equivalent to <tt>Hashtable</tt>, except that it is
unsynchronized and permits nulls.) This class makes no guarantees as to
the order of the map; in particular, it does not guarantee that the order
will remain constant over time.
是什么
基于哈希表实现的Map接口。这实现提供了所有可选的映射操作并且允许null值和null键。HashMap类大致相当于Hashtable,只是它是不同步,允许为空。这个类不能保证地图的顺序;特别是,它不能保证内容会随着时间保持不变。
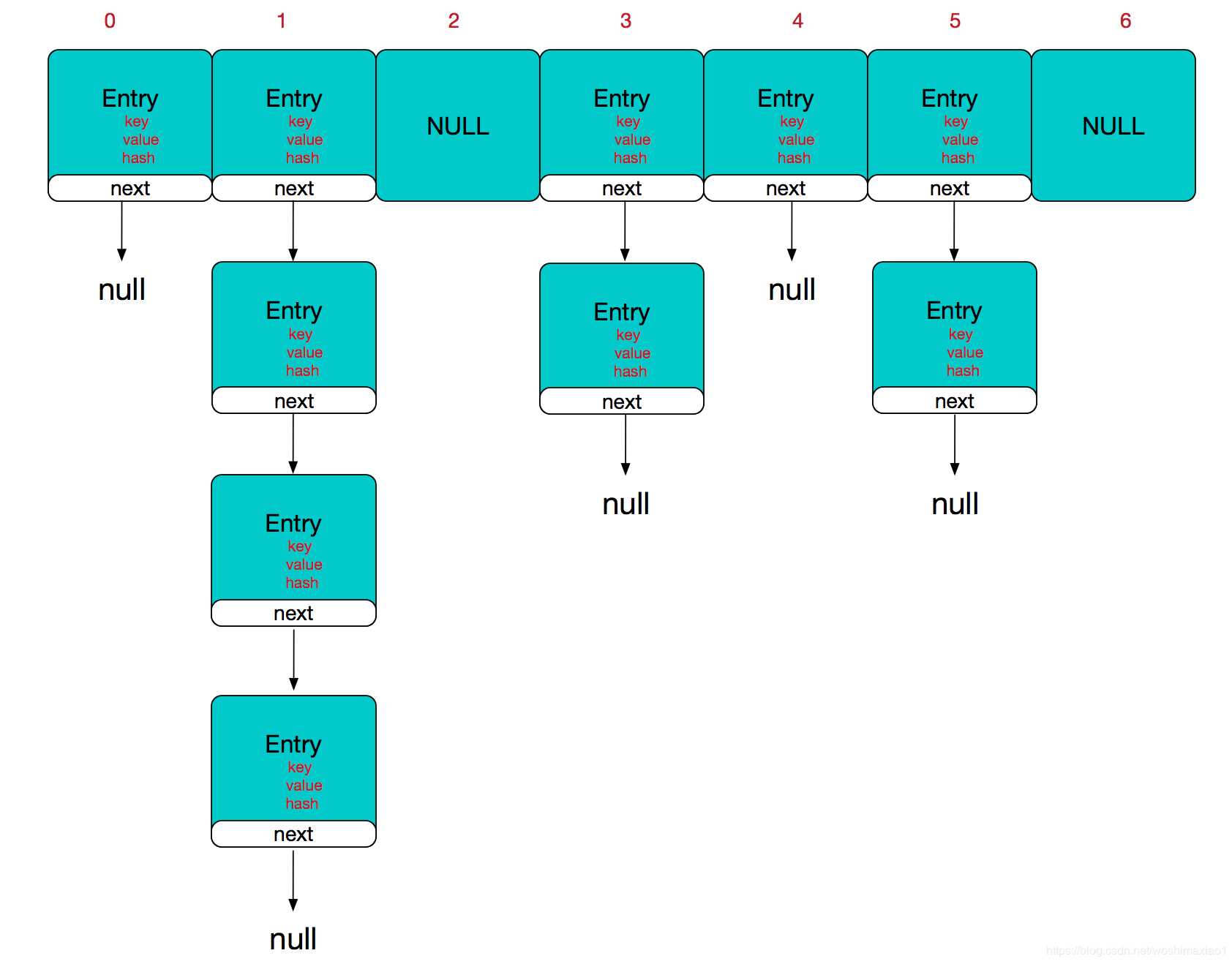
它的数据结构
众所周知,HashMap是用来存储Key-Value键值对的一种集合,这个键值对也叫做Entry,而每个Entry都是存储在数组当中,因此这个数组就是HashMap的主干。HashMap数组中的每一个元素的初始值都是NULL。HashMap由数组+链表组成的,数组是HashMap的主体,链表则是主要为了解决哈希冲突而存在的。
2.Put方法的实现原理
public V put(K key, V value) {
//如果table数组为空数组{},进行数组填充(为table分配实际内存空间),入参为threshold,
//此时threshold为initialCapacity 默认是1<<4(24=16)
if (table == EMPTY_TABLE) {
inflateTable(threshold);
}
//如果key为null,存储位置为table[0]或table[0]的冲突链上
if (key == null)
return putForNullKey(value);
int hash = hash(key);//对key的hashcode进一步计算,确保散列均匀
int i = indexFor(hash, table.length);//获取在table中的实际位置
for (Entry<K,V> e = table[i]; e != null; e = e.next) {
//如果该对应数据已存在,执行覆盖操作。用新value替换旧value,并返回旧value
Object k;
if (e.hash == hash && ((k = e.key) == key || key.equals(k))) {
V oldValue = e.value;
e.value = value;
e.recordAccess(this);
return oldValue;
}
}
modCount++;//保证并发访问时,若HashMap内部结构发生变化,快速响应失败
addEntry(hash, key, value, i);//新增一个entry
return null;
}插入位置是怎么确定的
HaspMap的一种重要的方法是put()方法,当我们调用put()方法时,比如hashMap.put("Java",0),此时要插入一个Key值为“Java”的元素,这时首先需要一个Hash函数来确定这个Entry的插入位置,设为index,
int hash = hash(key);
int i = indexFor(hash, table.length);假设求出的index值为2,那么这个Entry就会插入到数组索引为2的位置。
hash值是怎么计算
static final int hash(Object key) {
int h;
return (key == null) ? 0 : (h = key.hashCode()) ^ (h >>> 16);
}key的hash值,并不仅仅只是key对象的hashCode()方法的返回值,还会经过扰动函数的扰动,以使hash值更加均衡。扰动函数就是为了解决hash碰撞的。它会综合hash值高位和低位的特征,并存放在低位,因此在与运算时,相当于高低位一起参与了运算,以减少hash碰撞的概率。(在JDK8之前,扰动函数会扰动四次,JDK8简化了这个操作)
插入位置已经有值了怎么办
但是HaspMap的长度肯定是有限的,当插入的Entry越来越多时,不同的Key值通过哈希函数算出来的index值肯定会有冲突,此时就可以利用链表来解决。
其实HaspMap数组的每一个元素不止是一个Entry对象,也是一个链表的头节点,每一个Entry对象通过Next指针指向下一个Entry对象,这样,当新的Entry的hash值与之前的存在冲突时,只需要插入到对应点链表即可。
需要注意的是,新来的Entry节点采用的是“头插法”,而不是直接插入在链表的尾部,这是因为HashMap的发明者认为,新插入的节点被查找的可能性更大。
如果key是null
如果key为null,存储位置为table[0]或table[0]的冲突链上
如果该对应数据已存在,会发生什么
执行覆盖操作。用新value替换旧value,并返回旧value。
3.Get()方法的实现原理
public V get(Object key) {
//如果key为null,则直接去table[0]处去检索即可。
if (key == null)
return getForNullKey();
Entry<K,V> entry = getEntry(key);
return null == entry ? null : entry.getValue();
}final Entry<K,V> getEntry(Object key) {
if (size == 0) {
return null;
}
//通过key的hashcode值计算hash值
int hash = (key == null) ? 0 : hash(key);
//indexFor (hash&length-1) 获取最终数组索引,然后遍历链表,通过equals方法比对找出对应记录
for (Entry<K,V> e = table[indexFor(hash, table.length)];
e != null;
e = e.next) {
Object k;
if (e.hash == hash &&
((k = e.key) == key || (key != null && key.equals(k))))
return e;
}
return null;
} get()方法用来根据Key值来查找对应点Value,当调用get()方法时,比如hashMap.get("apple"),这时同样要对Key值做一次Hash映射,算出其对应的index值,即index = hash("apple")。前面说到的可能存在Hash冲突,同一个位置可能存在多个Entry,这时就要从对应链表的头节点开始,一个个向下查找,直到找到对应的
Key值,这样就获得到了所要查找的键值对。例如假设我们要找的Key值是"apple":
第一步,算出Key值“apple”的hash值,假设为2。
第二步,在数组中查找索引为2的位置,此时找到头节点为Entry6,Entry6的Key值是banana,不是我们要找的值。
第三步,查找Entry6的Next节点,这里为Entry1,它的Key值为apple,是我们要查找的值,这样就找到了对应的键值对,结束。
为什么是e.hash == hash && ((k = e.key) == key || (key != null && key.equals(k)))
get方法的实现相对简单,key(hashcode)–>hash–>indexFor–>最终索引位置,找到对应位置table[i],再查看是否有链表,遍历链表,通过key的equals方法比对查找对应的记录。要注意的是,有人觉得上面在定位到数组位置之后然后遍历链表的时候,e.hash == hash这个判断没必要,仅通过equals判断就可以。其实不然,试想一下,如果传入的key对象重写了equals方法却没有重写hashCode,而恰巧此对象定位到这个数组位置,如果仅仅用equals判断可能是相等的,但其hashCode和当前对象不一致,这种情况,根据Object的hashCode的约定,不能返回当前对象,而应该返回null。
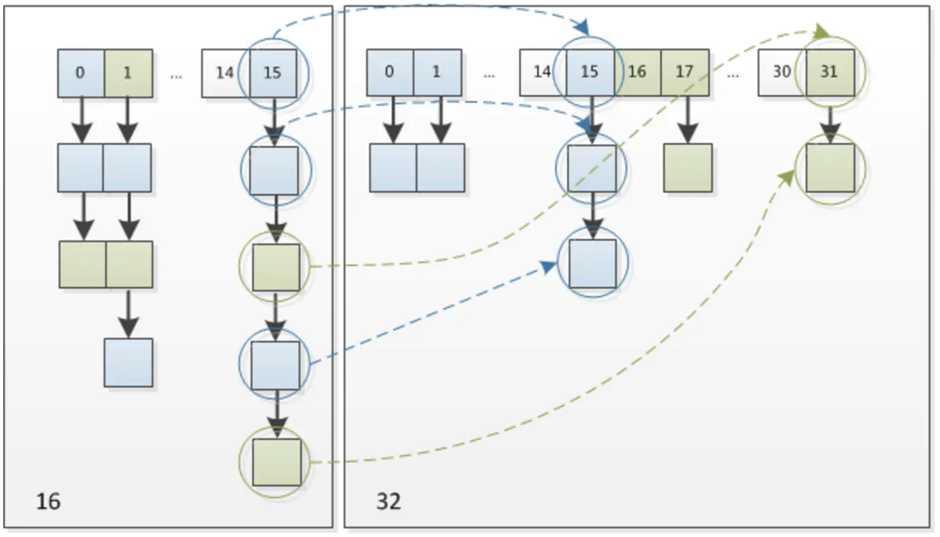
4.HashMap长度为什么是2的幂次方
index = HashCode(Key) & (hashMap.length - 1);1.Length - 1的值的所有二进制位全为1(如15的二进制是1111,31的二进制为11111),这种情况下,index的结果就等同于HashCode后几位的值。只要输入的HashCode本身分布均匀,Hash算法的结果就是均匀的。
2.当HashMap扩容后,变为原来长度的两倍,这时候,需要将原来的元素复制到扩容后的HashMap。二次幂的好处是,元素在扩容后的HashMap的位置要么是在原位置,要么就是在原位置在移动二次幂。因为index值只和HashCode(Key)的低位有关系,再扩容两倍后,index的值会多1bit,如果是0位置不变,如果是1,位置等于以前的位置加上以前的HashMap长度。
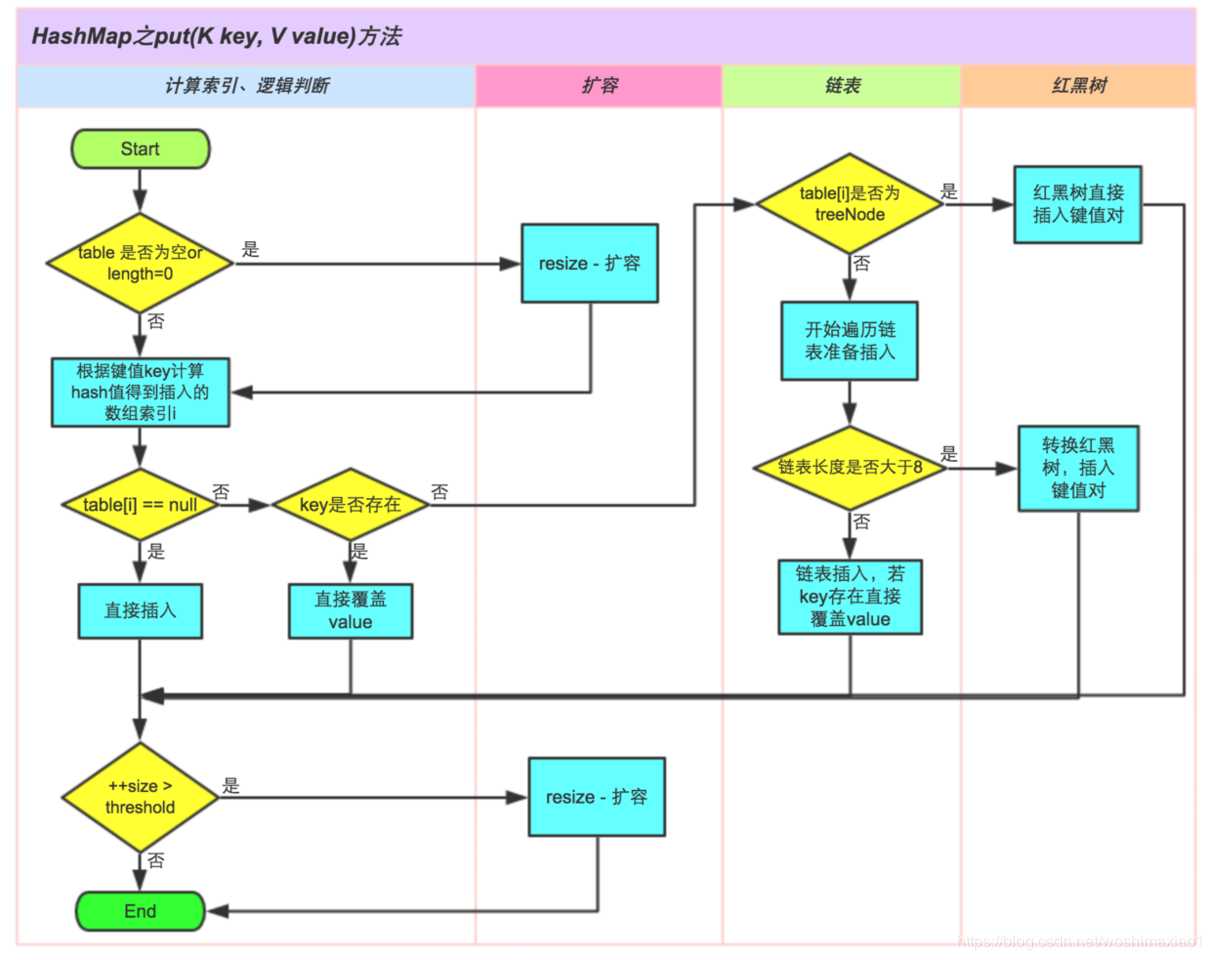
附HashMap put方法逻辑图
以上是关于HashMap一问一答的主要内容,如果未能解决你的问题,请参考以下文章