迁移学习
Posted luyunan
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了迁移学习相关的知识,希望对你有一定的参考价值。
迁移学习考虑的问题:没有直接相关的数据能否帮助到本任务?,解决的思虑可以求同存异概言。与本任务有关的 data 叫做 target data,与本任务无关的 data 叫做 source data,则迁移学习依据 target data 与 source data 有无 label 可分为四个大块:
- Source data 有 label,target data 有 label(Fine-tuning; Multi-task learning)
- Source data 有 label,target data 无 label(Domain-adversarial learning; Zero-shot learning)
- Source data 无 label,target data 有 label(Self-taught Learning)
- Source data 无 label,target data 无 label(Self-taught Clustering)
Labeled Source & Labeled Target
Fine-tuning
Idea
先用 Source data 训练一个模型,继而以此模型为 Initial,加以 Target data 继续训练,得到最终模型。
劣势及解决方案
但是由于 Target data 非常少,故容易过拟合。解决此问题的方法是
- Conservative Training,即限制 Target data 训练后的模型与原来 Source data 训练的模型相去不远,比如 输出近似、参数近似。
- Layer Transfer,即限制 Target data 只能 tune Source data 模型的部分层,而其它层保持固定。
哪些 Layers 可以 Transfer ?
须知深度网络是一个 multi-level representation,每层均有其表征含义。以语音识别为例,识别某人的声音可分解为识别口腔动作、发音方式、发音粗细等等。此时欲将他人的庞大发音数据的知识迁移到此任务,可使人与人发音之间的共同特点所对应的 Layer 转移到新的网络。在语音识别中这些 Layers 往往是靠近输出层的若干层,而在影像识别中,这些 Layers 往往是靠近输入层的若干层。
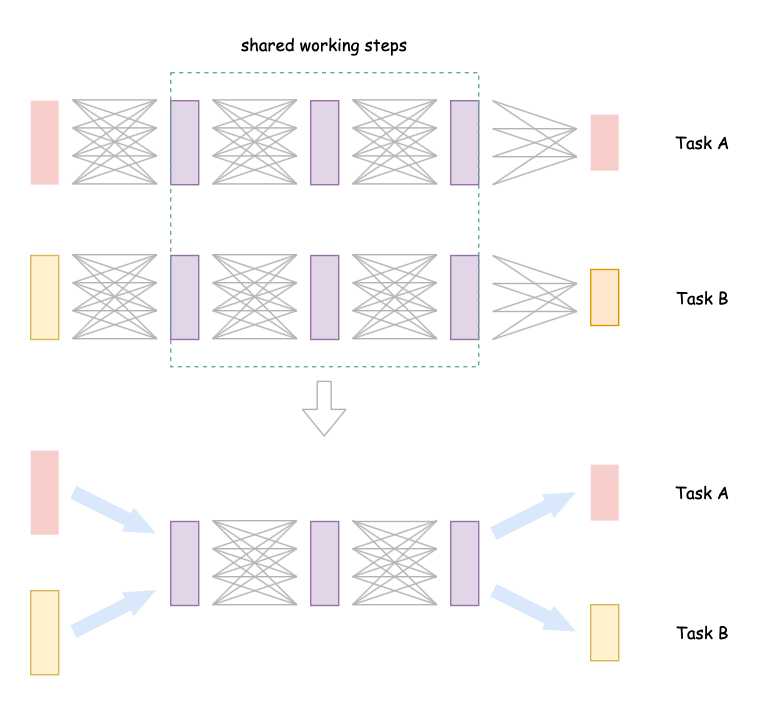
Multi-task Learning
与 Fine-tuning 仅关注 Target data 相异的是,Multi-task Learning 会同时关注 Target data 与 Source data 两者上的性能。
Labeled Source & UnLabeled Target
Domain-adversarial training
Motivation
来自不同 domain 的数据分布可能会如下图的 (a) 子图所示,对于数量庞大的 Source data 会有很好的区分性(蓝色),而对于 Target data 的区分度则非常小(红色),这会导致迁移性能非常差,故我们希望网络能够消除 domain 差异所带来的影响(如 b 子图所示)。
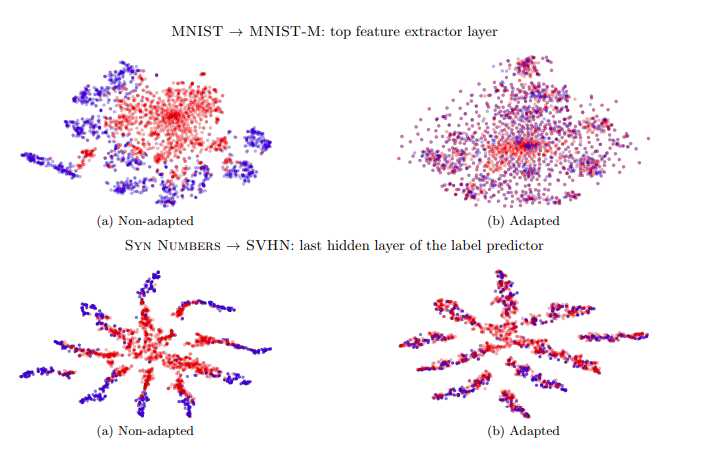
所以 Domain-adversarial training 要做的就是在特征提取阶段将特征的 domain 特性去除掉。
Method
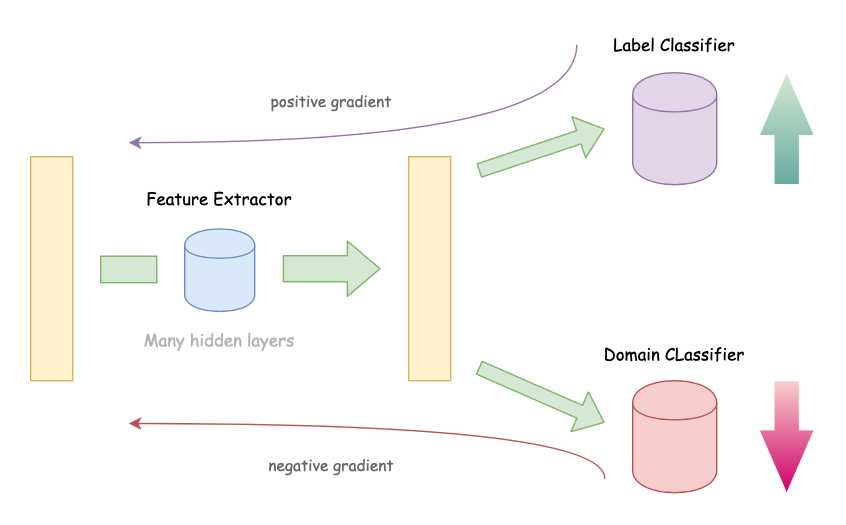
常规的网络流程就是特征提取后接上标记分类。此时我们往这个 “鱼塘” 里加一条 “鲶鱼”。这条鲶鱼的作用就是与特征提取的去 domain 特性做斗争,这条鲶鱼(命名为 domain classifier)必须很强,这样才能充分激发鱼塘里面小鱼的活力(挖掘特征提取器的去 domain 特性)。具体实现方法也很简单,仅仅是在反向传播过程中传播 domain classifier 给出梯度的相反数。
Zero-shot Learning
与 Domain-adversarial training 不同的是,Zero-shot 所处理的 Source data 和 Target data 都是来源于不同任务的。
两个例子
语音识别中,不直接将 acoustic feature 映射到具体的某个 word,而是先将 acoustic feature 映射到 phoneme,然后通过 phoneme 到 word 的映射来确定最终的结果。影像识别中,不直接将影像映射到某个具体的对象,而是映射到对象的特性。比如识别动物的任务中,建立一个动物的属性表(四条腿、毛茸茸、长尾巴、长嘴巴等等),继而识别动物转化成识别各种动物属性。有时候动物属性集非常庞大,我们就可以用属性空间来表示,新来样本计算 KNN 即可。
Method
- Represent each class by its attributes,学习的类别转化成类别不同的属性。
- Attribute embedding + word embedding,每张 image 通过 transformer 转化成 embedding space 里面的一个点,attributes 也转化成 embedding space 上的一个点,进而通过距离计算结果。
- Convex combination of semantic embedding,算出某张图属于各个类别的概率,进而在 embedding space 里用线性加权计算出最终的结果。
Unlabeled Source & Labeled Target
Self-taught learning
虽然 Source data 没有标记,但是可以通过它们来训练一个 Feature Extractor。换言之,用它们来训练一个 Representation。
以上是关于迁移学习的主要内容,如果未能解决你的问题,请参考以下文章