Spark core 总结
Posted wyh-study
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了Spark core 总结相关的知识,希望对你有一定的参考价值。
Spark
RDD五大特性
1、RDD由一组partition组成
2、每一个分区由一个task来处理
3、RDD之间有一些列依赖关系
4、分区类算子必须作用在kv格式得RDD上
5、spark为task执行提供了最佳计算位置,尽量将task发送到数据所在节点执行
spark 快的原因
1、spark 尽量将数据放在内存
spark容易出现OOM
2、粗粒度资源申请
在应用程序启动的时候就会申请所有资源
3、DAG有向无环图
优化转换过程
Driver
spark 程序的主程序
1、负责申请资源
new SparkContext
2、负责任务调度
发送task到Excutor中执行
Excutor
spark应用程序执行器
standalone
worker所在节点启动
yarn
NodeManager所在节点启动
执行task任务,向Driver汇报task执行情况
环境搭建
local
本地测试
需要本地安装hadoop
standalone
使用spark自带资源管理框架
Driver向Master申请资源
节点组成
master
管理资源和分配资源
存在单点问题
client
在本地打印运行日志
一般用于上线前测试
Driver在本地(提交任务的节点)启动
Driver即负责资源申请也负责任务调度
cluster
日志不再本地打印
Driver在集群中启动
随便选择一个Worker中启动Driver
一般用于上线运行
yarn
使用hadoop的yarn作为资源管理框架
提交任务 Driver去ResourceManasger中申请资源
通过实现applicationMaster接口往yarn里面提交任务
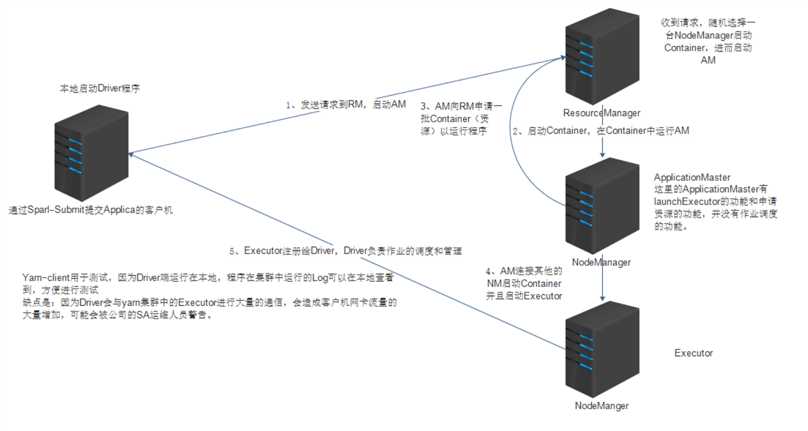
yarn-client
在本地打印运行日志
一般用于上线前测试
Driver在本地(提交任务的节点)启动
Driver只负责任务调度
启动ApplicationMaster 为spark应用程序申请资源
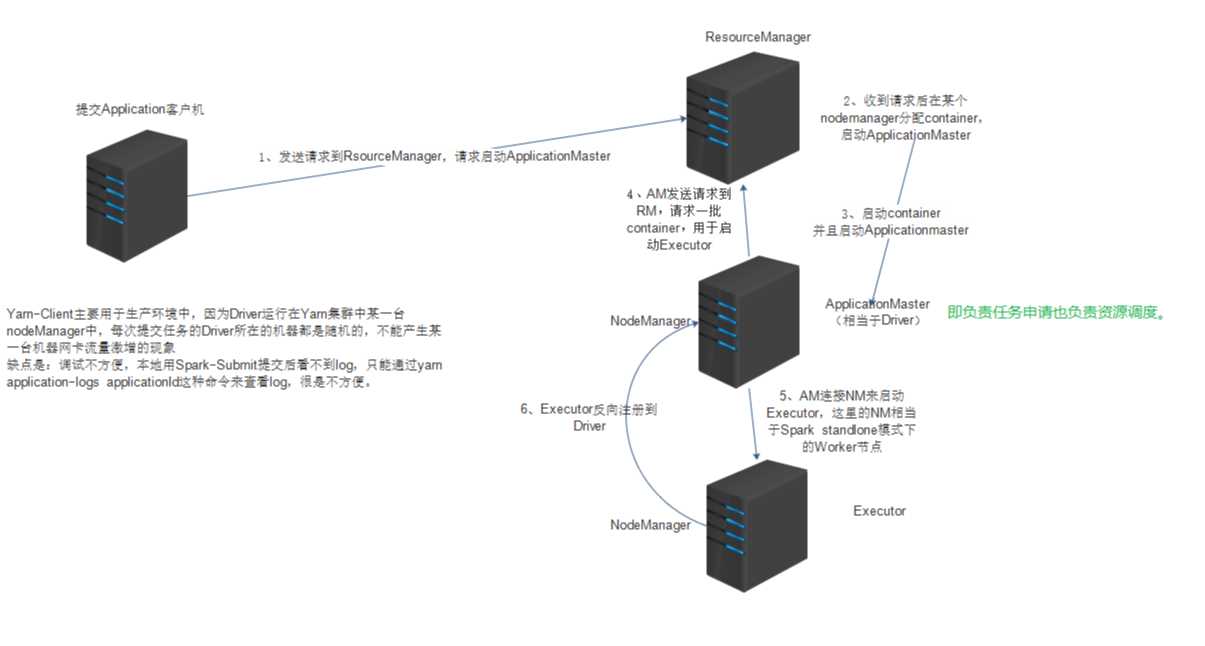
yarn-cluster
日志不再本地打印
一般用于上线运行
Driver(ApplicationMaster)在集群启动
Driver即负责资源申请也负责任务调度
常用算子
transformations算子
map
传入一个对象返回一个对象
flatMap
Filter
返回true保留数据,返回false过滤数据
groupByKey,groupBy
reduceBykey
reduceByKey在map端进行预聚合
union
join
sample
sortBy, sortByKey
rePartition ,partitionBy(自定义分区器)
重新分区,会产生shuffle
mapValues
action算子
foreach
reduce
在map预聚合
save
collect collectAsMap
分区
1、第一个RDD分区数有block数量决定(和mr一样), inputformat
2、后续rdd分区数量
1、默认数去数量等于前一个rdd分区数量
2、在使用shuffle类算子得时候可以执行分区数量
缓存
1、RDD默认不保存数据 2,懒执行
cache
是一个转换算子,不会触发job,需要接收
将数据放Excutor内存中, persist(StorageLevel.MEMORY_ONLY)
persist
可以指定缓存级别
1、是否放内存
2、是否放磁盘
3、是否放堆外内存
4、是否序列化
压缩
1、好处:数据量变小,占用空间更小
2、缺点:序列化和反序列化需要浪费cpu执行时间
5、副本数
选择缓存级别
1、内存充足
MEMORY_ONLY
2、内存不是很多
MEMORY_AND_DISK_SER
尽量将数据压缩之后i放内存
3、内存不足
DISK_ONLY
既然已经放磁盘了,就不必要压缩了
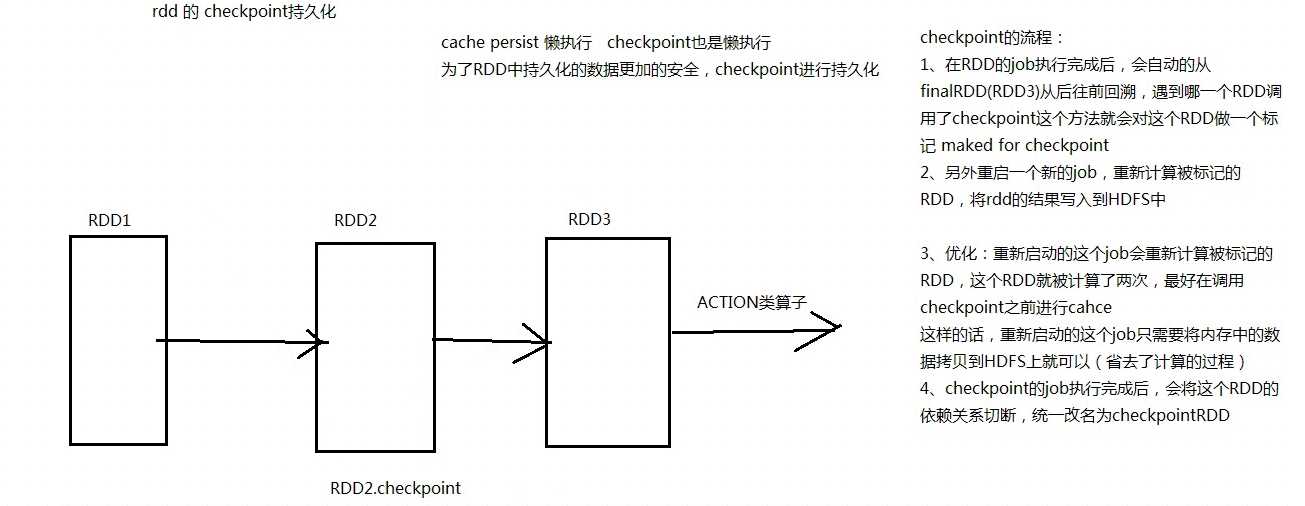
checkpoint
1、将RDD得数据写入hdfs
2,checkpoing会切断RDD依赖关系
3、从最后一个RDD向前回溯,对checkpoint的RDD进行标记,另启动一个job重新计算rdd的数据,并rdd数据写入hdfs(也就是遇到actions算子后启动一个job进行回溯,遇到checkpoint再次启动一个job)
优化:在checkpoint之前先进行cache(避免重读计算)
pagerank
网页排名
计算过程
1、每个网页一个初始值
2、通过不断迭代计算新的pr值
资源调度和任务调度
资源调度
1、细粒度资源调度
MapReduce
每一个task都需要单独申请资源
task启动速度较慢
资源充分利用
2、粗粒度资源调度
spark
在应用程序启动的时候就会将所有需要的资源全部申请下来,后面task执行变快
资源浪费(资源没有充分的利用,在执行的过程中无法进行释放,只有当作业全部进行完毕后才释放)
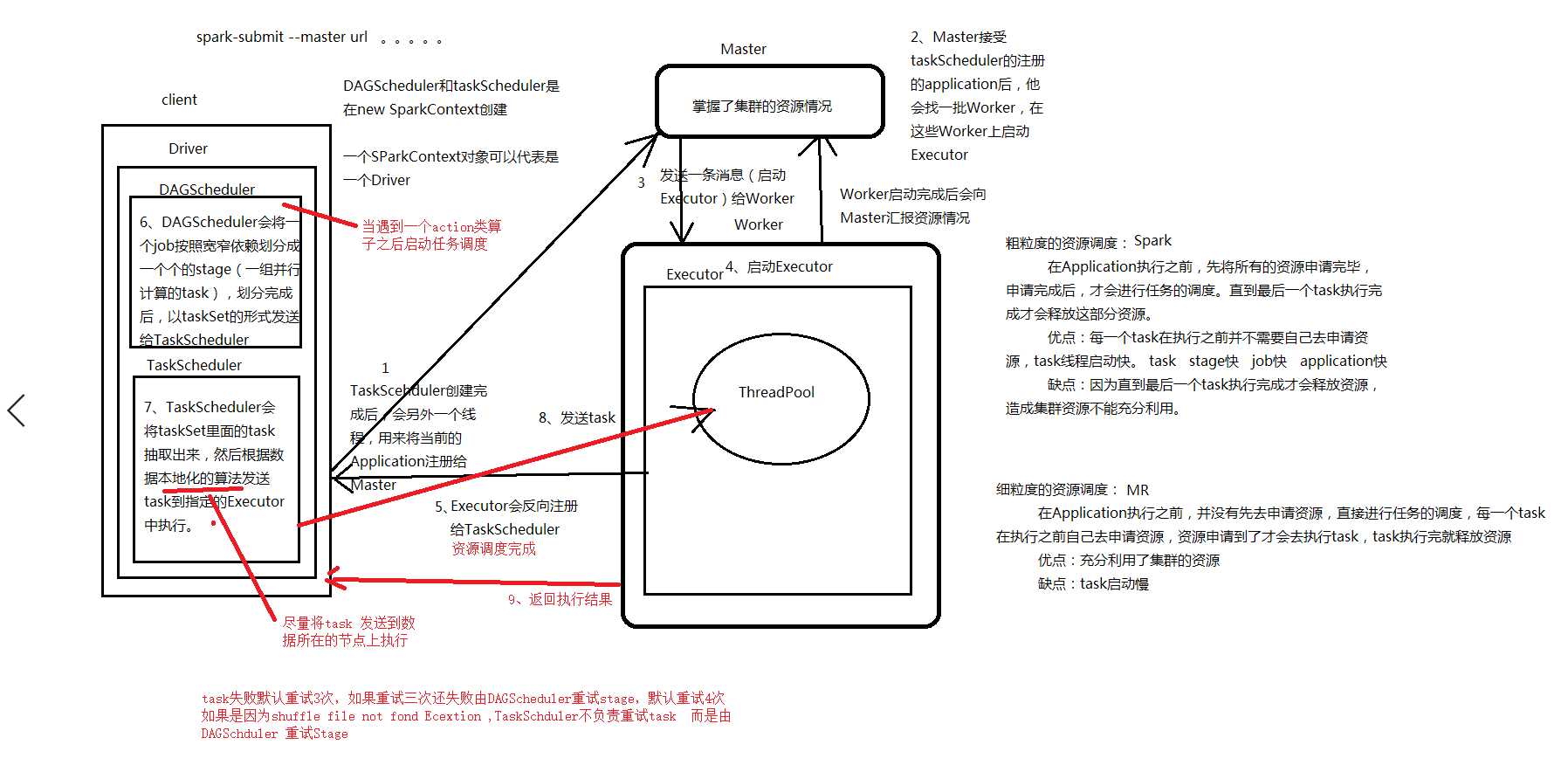
3、spark资源调度流程 yarn-cluster
1、通过spark-submit提交任务
2、在本地启动Driver val sc = new SparkContext(conf)
3、Driver发请求给RM 启动AM
4、RM分配资源启动AM
5、AM向RM申请资源启动Excutor
6、AM分配资源启动Excutor
7、Excutor反向注册给Driver
8、开始任务调度(action算子触发)
任务调度
1、当遇到一个action算子,启动job,开始任务调度
2、构建DAG有向无环图
3、DAGScheduler 根据宽窄依赖切分Stage (stage是一个可以并行计算的task)
4、DAGScheduler 将stage以taskSet的形式发送给TaskScheduler
5、TaskScheduler 根据本地化算法将task发送到数据所在节点去执行
6、TaskScheduler收集tasK执行情况
如果task失败TaskScheduler默认重试3次
如果重试3次之后还失败,由DAGScheduler重试stage 默认重试4次
如果是因为shuffle过程中拉去文件失败发生的异常,TaskScheduler不负责重试task,而是由DAGScheduler重试上一个stage
TaskScheduler 推测执行
如果有一个task执行很慢,TaskScheduler会在启动一个task去竞争,谁先执行完,以谁的为准
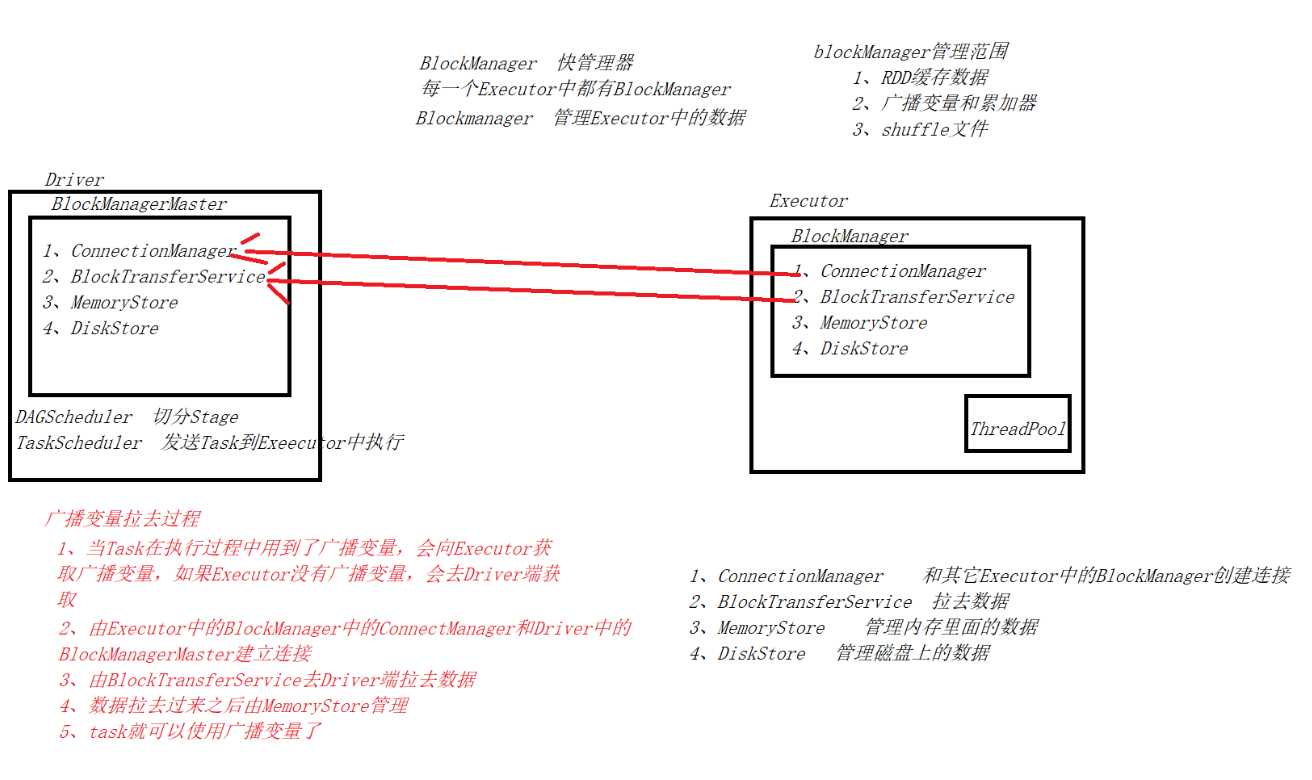
广播变量
如果不使用广播变量变量副本等于task数量
如果使用广播变量变量副本等于Executor数量
广播变量只能在Driver定义,在Executor端读取
rdd 算子里面不能使用其它rdd

累加器
全局累加变量
1、只能在Driver端定义
2、只能Executor端累加
3、只能在Driver读取
spark shuffle
hash shuffle
产生小文件的数量:m*r
hash shuffle manager
产生小文件的数量:c*r
sort shuffle 默认
产生小文件的数量:2*m
sort shuffle bypass机制
产生小文件的数量:2*m
数据在map端不会排序
当 reduce数量小于 spark.shuffle.sort.bypassMergeThreshold=200触发bypass机制
快的原因
尽量将数据放到内存里面进行计算
粗粒度资源调度
DAG有向无环图
切分Stoge
RDD五大特性
1、RDD由一组partition组成
2、函数操作实际是作用在每个partition上
3、RDD之间由一系列依赖关系
4、分区类算子必须作用在kv格式的rdd上
reducebeykey,groupbykey
5、spark为task执行提供了最佳计算位置
BlockManager
每个Executor中都有一个
管理数据
1、RDD缓存数据
2、shuffle数据
3、广播变量和累加器

以上是关于Spark core 总结的主要内容,如果未能解决你的问题,请参考以下文章