ThreadLocal 作为数据收集器使用
Posted pmh905001
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了ThreadLocal 作为数据收集器使用相关的知识,希望对你有一定的参考价值。
接到一个很特殊的需求:
系统用户存在两种类型,一种是普通的,另外一种称之为admin,admin用户很特殊。对于普通用户,当系统修改他自身属性(包含很多属性,比如:性别、绑定的信用卡、身份证、出生日期等)系统不仅要保存用户信息,而且还需要保存数据的变化(这称之为audit log,比如用户修改了出生日期,那么audit log需要保存之前的出生日期以及修改后的出生日期)。 对admin用户的操作与普通用户不一样,当系统检测到产生audit log之后,需要暂停当前流程弹出一个对话框提示用户,选中yes之后生成audit log继续流程;选中no之后则不生成audit log继续流程。
如果从正向实现的角度,该需求几乎无法实现,原因如下:
在我们当前系统中,Web服务器与Application Server是通过远程调用方式进行单向交互。生成audit log只是大事务中很小的一个步骤,集中在Application server 中处理。如下图所示
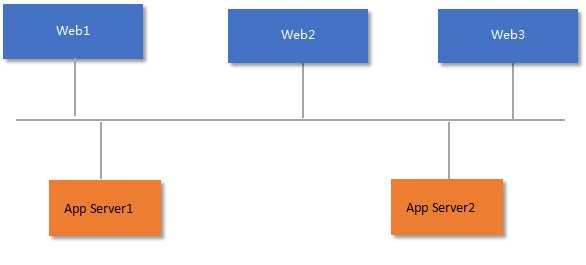
如果单独把audit log做生一个服务给提取出来则会破坏大事务的完整性,造成沉重代码改动量。
实际上我们可以换一个角度来实现该需求,既然audit log是大事务中的小步骤,那么我们可以先让该流程继续走下去让audit log继续生成,只需要一个收集器记录audit log ID列表,调用执行完成后返回给客户端web server。当选择为No的时候我们就把已经存在的audit log删除就好。 我们可以远程调用的拦截器初始化一个收集器存放在ThreadLocal中,当生成一个audit log记录的时候(事务未提交),将audit log ID 放入到收集器中。这样就可以轻松实现该需求了。
以上是关于ThreadLocal 作为数据收集器使用的主要内容,如果未能解决你的问题,请参考以下文章