基于内容的推荐算法
Posted wyb-mingtian
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了基于内容的推荐算法相关的知识,希望对你有一定的参考价值。
输入
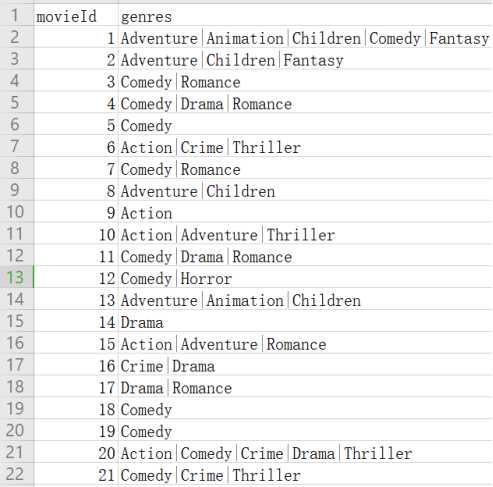
输入1:包含200部电影的数据集,集合中包含两列,一列为电影的id,一列为电影的流派集合,如下图所示:
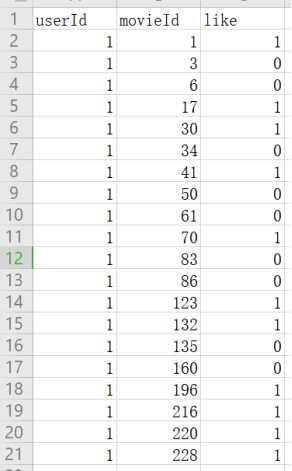
输入2:一个用户的电影兴趣记录,like字段为1表示喜欢,0表示不喜欢,如下图所示:
输出
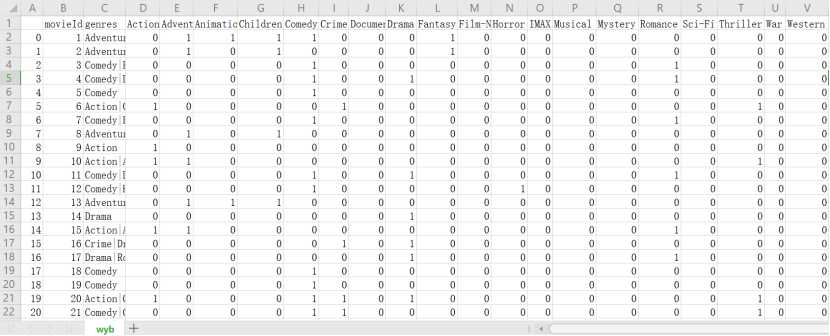
输出1:输入1的One-Hot编码形式,类似下图所示:
输出2:根据输入2和输出1,从电影数据集中给用户推荐用户没有看过的与用户相似度最高的k个电影。
前言
基于内容的推荐算法是一种比较经典的推荐算法,应用较广,可解释性强,准确率高,尤其是当今社会信息丰富,比如文本、音频等,有比较多的内容可以利用。但是对于一个一无所知的新用户而言,无法针对用户内容进行推荐,只能根据其他算法进行推荐,用户产生内容后才能很好的利用基于内容的推荐算法,这也就是冷启动问题,也是该算法的缺点。
原理
一、用户画像
做好一个推荐系统,分为以下3步:
- 认识用户
- 给用户推荐他感兴趣的东西
- 观察各项业务指标,一直迭代1,2,3循环下去
上面提到的认识用户就是用户画像,用户画像是一个比较抽象的概念,推荐系统的用户画像是给机器用的。推荐系统要在用户和物品之间建立连接,一般的连接方式是对用户和物品之间的匹配进行评分,也就是预测用户的偏好,我们首先要将用户和物品都表示成向量,这样才能让机器进行计算,用户向量化后的结果就是用户画像。
那么一般情况下怎么构建用户画像呢?按照对用户向量化的手段来分,用户画像的构建方法有以下3类:
- 查户口。直接使用原始的数据作为用户画像的内容,比如注册信息、购买历史,这种方法实现简单,尤其对于新用户有效,适用于冷启动等场景;
- 堆数据。统计用户的历史数据,先给物品打上标签,然后获取用户在这些标签上的行为,从标签维度做数据统计,用统计结果作为量化结果,这一类数据贡献了常见的用户画像;
- 机器学习的方法。学习出人类无法理解的稠密向量,比如使用矩阵分解得到的隐因子或者深度学习得到的Embedding向量,这一类用户画像数据通常可解释性较弱。
构建用户画像的关键因素有哪些呢?主要是以下两方面:
- 维度。每个维度的名称都是可理解的,比如对于一个人而言,维度可能有性别、年龄、学历等,有些维度值是固定的,有些是在不断变化的。
- 量化。对每个维度进行量化,比如性别男、年龄22、学历本科等,有一些维度的量化主观上给不准确,就需要把量化交给机器,根据推荐效果的好坏来繁项优化用户的画像,因为用户的兴趣爱好随着时间是变化的,比如原本喜欢文学的用户,某一天不喜欢看文学的书了(给他推荐了文学的书而没有购买或者是购买记录里没有文学相关的书籍),而是买了AI相关的书籍,那么推荐系统就可以给他推荐AI相关的书籍,如果用户发生了相关的购买行为,那么用户的读书偏好就要动态进行更新和量化。
二、挖掘标签
文本数据是互联网产品中常见的信息,挖掘兴趣标签主要处理的就是用户的一些操作行为产生的文本数据。
用户一端的文本数据,主要有:
- 注册资料中的一些信息;
- 用户自己产生的一些内容,比如评论、收藏、购买等行为;
- 与用户发生了联系的信息,比如阅读的内容等。
物品一段的文本数据,主要有:
- 物品本身的描述、介绍;
- 物品本身的内容和属性。
可以利用一些成熟的NLP算法分析物品端的文本信息提取一些关键词作为标签,常用的方法有TF-IDF等。
三、推荐操作
当我们有了物品的标签和用户的一些行为后,就可以根据这些信息给用户推荐产品,现住的问题是,到底是物品的哪些特性吸引了用户呢?一种方法是直接把用户产生过行为的物品标签累计在一起,作为用户的用户画像,计算用户与物品的相似度,给用户推荐最相似的TopN个物品。
python代码实现
1 import numpy as np 2 import pandas as pd 3 4 movieFile = ‘./movies.csv‘ 5 movieData = pd.read_csv(movieFile,encoding=‘gb2312‘) 6 print(‘len:{}‘.format(len(movieData))) 7 8 # 将genres转化为One-Hot编码的形式 9 genre_iter = (set(x.split(‘|‘)) for x in movieData.genres) 10 genres = sorted(set.union(*genre_iter)) 11 tmpDF = pd.DataFrame(np.zeros(((len(movieData),len(genres)))), columns=genres) 12 for i , gens in enumerate(movieData.genres): 13 tmpDF.ix[i,gens.split(‘|‘)] = 1 14 15 # 把tmpDF合并到movieData 16 movieData = movieData.join(tmpDF) 17 movieData.to_csv(‘wyb.csv‘) 18 19 # 读取样本数据 20 samplesFile = ‘./samples.csv‘ 21 samplesData = pd.read_csv(samplesFile,encoding=‘gb2312‘) 22 print(‘len:{}‘.format(len(samplesData))) 23 # 把genres得到的One-Hot编码形式的数据合并到样本中,为了后面计算用户的特征向量使用 24 samplesData = samplesData[samplesData[‘like‘] == 1] 25 mergeData = pd.merge(samplesData, movieData, on=‘movieId‘, how=‘left‘) 26 mergeData.to_csv(‘ctt.csv‘) 27 # 计算样本用户的特征向量 28 userFeatureVector = [] 29 for label in genres: 30 userFeatureVector.append(mergeData[label].sum()) 31 userFeatureVector = np.array(userFeatureVector) 32 # 在移除用户已经看过的电影,只推荐用户没有看过的 33 movieData = movieData[~movieData[‘movieId‘].isin(mergeData[‘movieId‘])] 34 # 键为电影ID,值为电影与用户的余弦相似度 35 info_recom = {} 36 for row in range(0, len(movieData)): 37 rowData = movieData.iloc[row, 2:21] 38 itemId = movieData.iloc[row, 0] 39 itemFeatureVec = np.array(rowData) 40 similarity = np.dot(itemFeatureVec, userFeatureVector)/(np.linalg.norm(itemFeatureVec) * np.linalg.norm(userFeatureVector)) 41 info_recom[itemId] = similarity 42 43 # 字典元素按值大小从大到小排序 44 result = sorted(info_recom.items(),key=lambda x:x[1], reverse=True) 45 # 推荐最相似的10部电影 46 topTen = 10 47 for index in range(0,topTen): 48 print(‘recom top[{}]:{}‘.format(index, result[index][0]))
代码运行结果
本文代码是在已知电影集标签和一个用户的兴趣记录的情况下,给一个用户推荐的相似度前10的电影。推荐的电影id为:
1 recom top[0]:4 2 recom top[1]:11 3 recom top[2]:45 4 recom top[3]:52 5 recom top[4]:58 6 recom top[5]:94 7 recom top[6]:195 8 recom top[7]:224 9 recom top[8]:232 10 recom top[9]:72
以上是关于基于内容的推荐算法的主要内容,如果未能解决你的问题,请参考以下文章