03_特征清洗
Posted ziwh666
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了03_特征清洗相关的知识,希望对你有一定的参考价值。
1.缺失值
当数据缺失时出现的问题:
- 当有缺失值时有些算法没法work
- 即使是处理缺失数据的算法,如果不进行处理,模型也会导致不准确的结论
缺失机制:
- Missing Completely as Random:如果所有观测值丢失的概率相同,则变量完全随机丢失(MCAR)。当数据是MCAR时,那些丢失的数据点是数据的一个随机子集。没有任何额外的操作使得某些数据比其他数据更容易丢失。(当观测值是完全随机的时,忽略这些缺失也不会对结果有什么影响)
- Missing at Random:当观测值丢失的概率取决于数据集中的其他一些变量,而不取决于变量本身时。例如,如果男性比女性更愿意透露自己的体重,那么体重就是MAR。对于那些决定不透露自己体重的男性和女性来说,体重信息将会随机缺失,但由于男性更倾向于披露体重信息,女性的缺失值将比男性更多。在上述情况下,如果我们决定继续处理缺失值的变量,我们可能会受益于包括性别来控制缺失值的权重偏差。
- Missing Not At Random - Depends on Unobserved Predictors:缺失性依赖于没有记录的信息,这些信息也可以预测缺失的值。例如,如果一种特定的治疗方法引起不适,患者更有可能退出研究(而“不适”是没有测量的)。在这种情况下,如果我们去掉那些遗漏的案例,数据样本就会有偏差。
- Missing Not At Random - Depends on Missing Value Itself:缺失取决于(可能缺失的)变量本身。例如,收入高的人不太可能透露他们收入。
如何假设一个缺失的机制:
- bussiness understanding:在许多情况下,我们可以通过探究该变量背后的业务逻辑来假定该机制。
- statcstical test:将数据集分为有/无缺失的数据集,并进行t检验,看看是否存在显著差异。如果有,我们可以假设失踪不是随机完成的。
- 但是我们应该记住,我们几乎不能100%确定数据是MCAR、MAR或MNAR,因为未观察到的预测因子(隐藏的变量)是未观察到的。
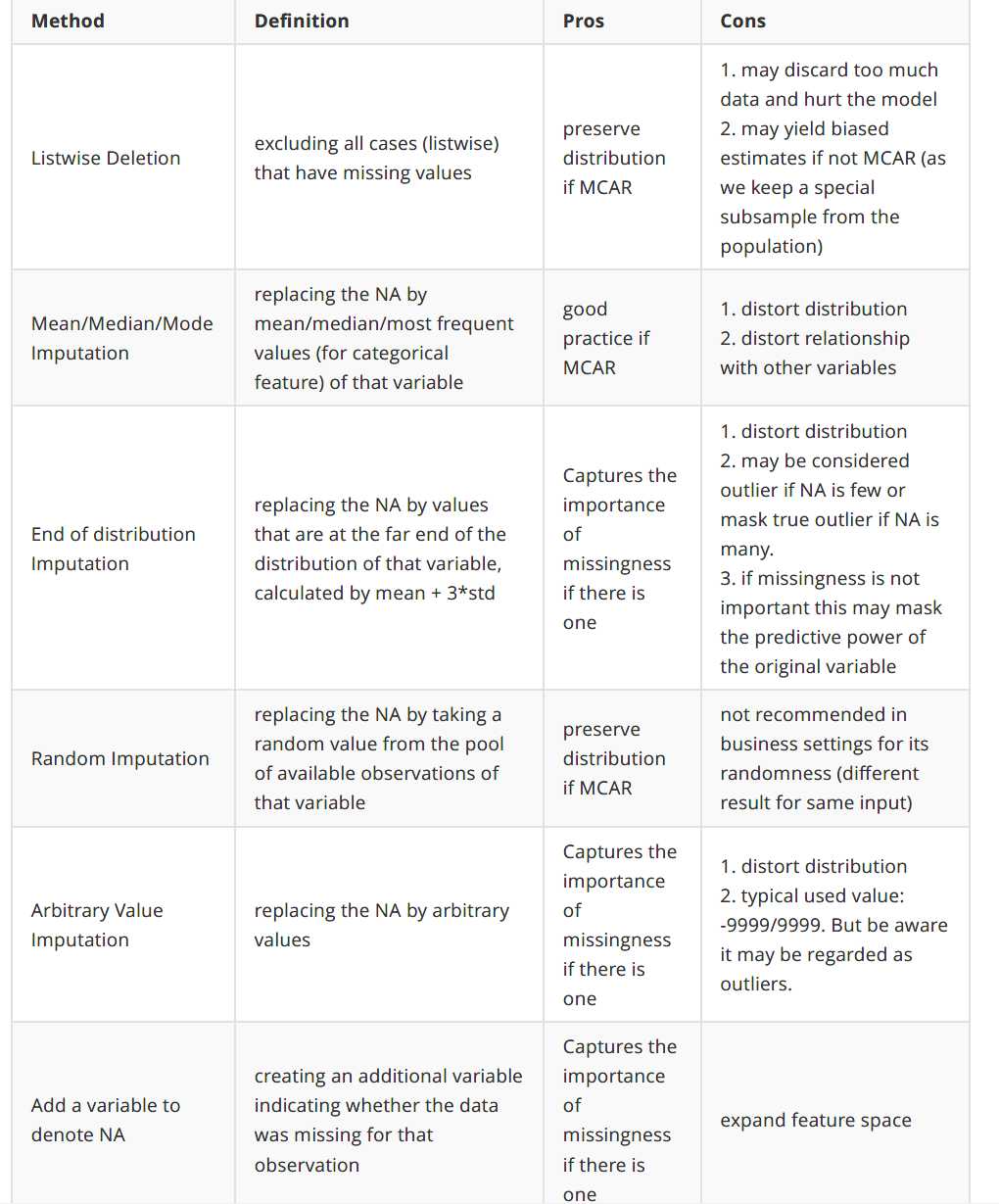
如何处理Missing Data:
在实际环境中,当很难确定缺失的机制或几乎没有时间深入研究每个缺失的变量时,最流行的方法是采用:

2.Outliers
离群值是一种观测值,它与其他观测值相差甚远,以至于使人怀疑它是由另一种机制引起的。根据上下文,异常值要么值得特别注意,要么应该完全忽略。例如,信用卡上不寻常的交易通常是欺诈活动的标志,而高度的一个人的1600厘米很可能是由于测量误差,应该被过滤掉或用其他值代替
离群值的问题:
- 使算法没法很好的工作,有些算法对异常值非常敏感,任何依赖均值/方差的算法都对异常值非常敏感,而产生泛化能力差的模型
- 往数据中加入了噪声
- 降低了样本的代表性
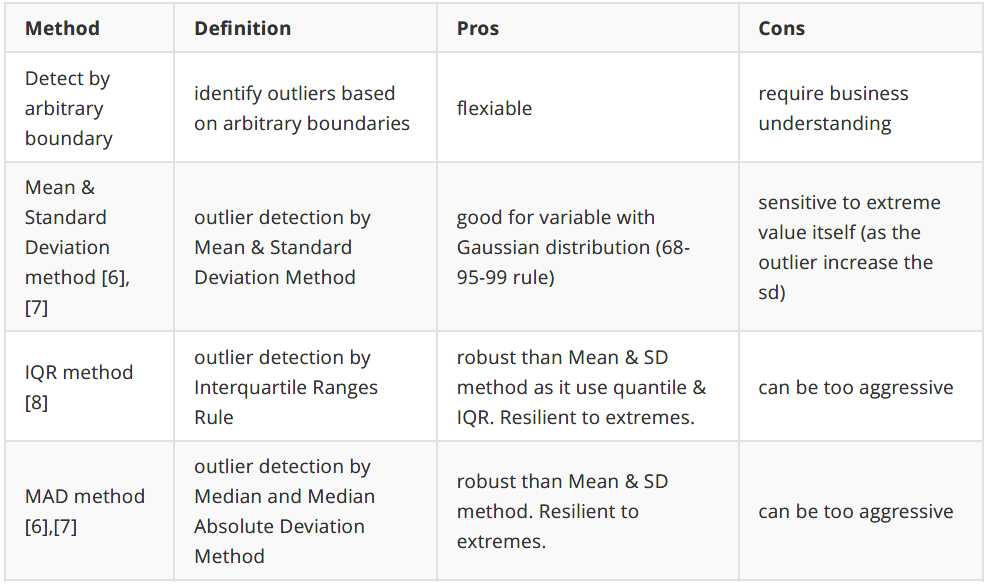
离群点检测:
应该根据上下文如何定义和对这些异常值做出反应。你的反应的意义应该由潜在的上下文决定,而不是数字本身
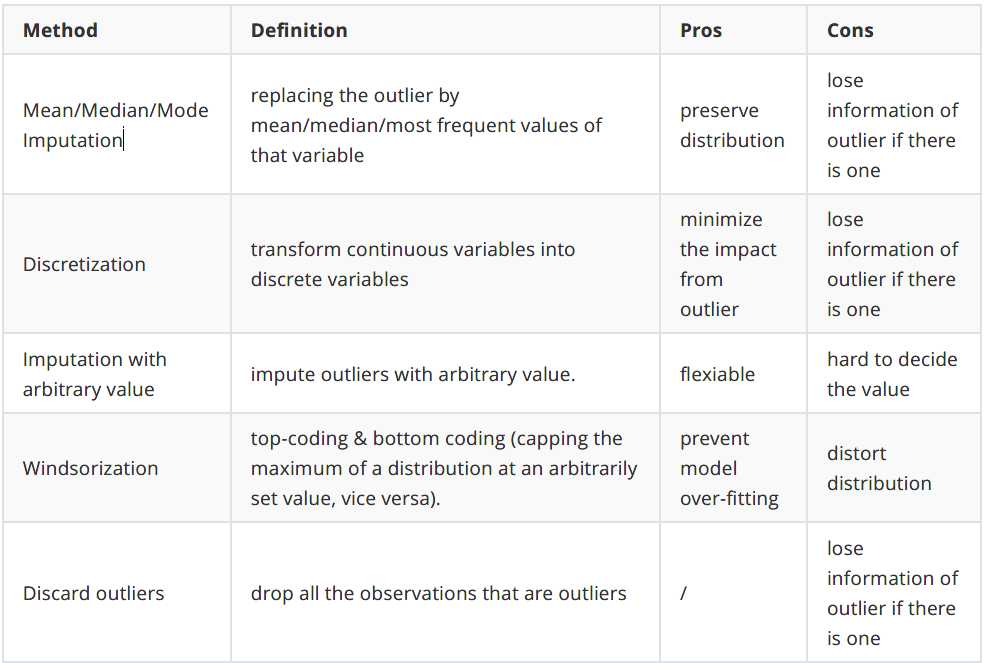
离群点处理:
3.Rare Values:
很少出现的值,在某些情况下,罕见值(如离群值)可能包含有价值的数据集信息,因此需要特别注意。例如,交易中罕见的值可能表示欺诈。而其他情况下,罕见值或许应该去除或者用其他值代替。
罕见值的问题:
- 分类问题中罕见值容易导致过拟合,比如基于树的方法的时候
- 大量的非频繁标签增加了噪声,信息量少,导致过拟合
- 罕见值或许只出现在training set或testing set,导致某个数据集过拟合
如何处理罕见值:

- 当变量中有一个占主导地位的类别(超过90%)时:观察该变量与目标之间的关系,然后要么放弃该变量,要么保持该变量不变。在这种情况下,变量通常对预测没有帮助,因为它是准常量(稍后我们将在特征选择部分看到这一点)。
- 当只有少量类别时:保持原样。因为只有很少的类别不太可能带来这么多的噪音。
- 当基数较大时:尝试上面的两个方法。但它并不能保证比原始变量得到更好的结果。
4.高基数
如果一个特征是用来表示类别/定性的(categorical),而且这个特征的可能值非常多,通常用0-n的离散整数来表示,那么它就是高基数类别特征
高基数的问题:
- 标签太多的变量往往比标签很少的变量占优势,特别是在基于树的算法中。
- 一个变量内的大量标签可能会在几乎没有信息的情况下引入噪声,从而使机器学习模型容易过度拟合。
- 有些标签可能只出现在训练数据集中,而没有出现在测试集中,从而导致算法对训练集过拟合。
- 相反,新的标签可能出现在测试集中,而训练集中没有出现,因此算法无法对新的实例进行计算
如何处理高基数:
- 对具有业务理解的标签进行分组
- 将罕见的标签归入一个类别
- 使用决策树对标签进行分组:所有这些方法都试图对一些标签进行分组并减少基数,目的是将标签合并成更多同质的组,将罕见的标签归类为一个类别。
以上是关于03_特征清洗的主要内容,如果未能解决你的问题,请参考以下文章