04_特征工程
Posted ziwh666
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了04_特征工程相关的知识,希望对你有一定的参考价值。
1.Feature Scaling
对数据的自变量或特征范围进行标准化的一种方法。在数据处理中,它也称为数据规范化,通常在数据预处理步骤中执行。
为什么要进行Feature Scaling:
- 如果输入范围变化,在某些算法中,对象函数将不能正常工作。
- 梯度下降收敛得更快,与特征缩放完成。梯度下降法是逻辑回归、支持向量机、神经网络等常用的优化算法。
- 涉及距离计算的算法如KNN、聚类算法也受特征量的影响。只要考虑欧几里德距离是如何计算的:取观测值之间差异平方和的平方根。变量之间的尺度差异会对这个距离产生很大的影响。
- 基于树的算法几乎是唯一不受输入大小影响的算法,我们可以很容易地从树的构建方式中看到这一点。当决定如何分割时,树算法会查找“特征值是否为X>3.0”这样的决策,并计算分割后子节点的纯度,因此不考虑特征的规模。
如何进行Feature Scaling:
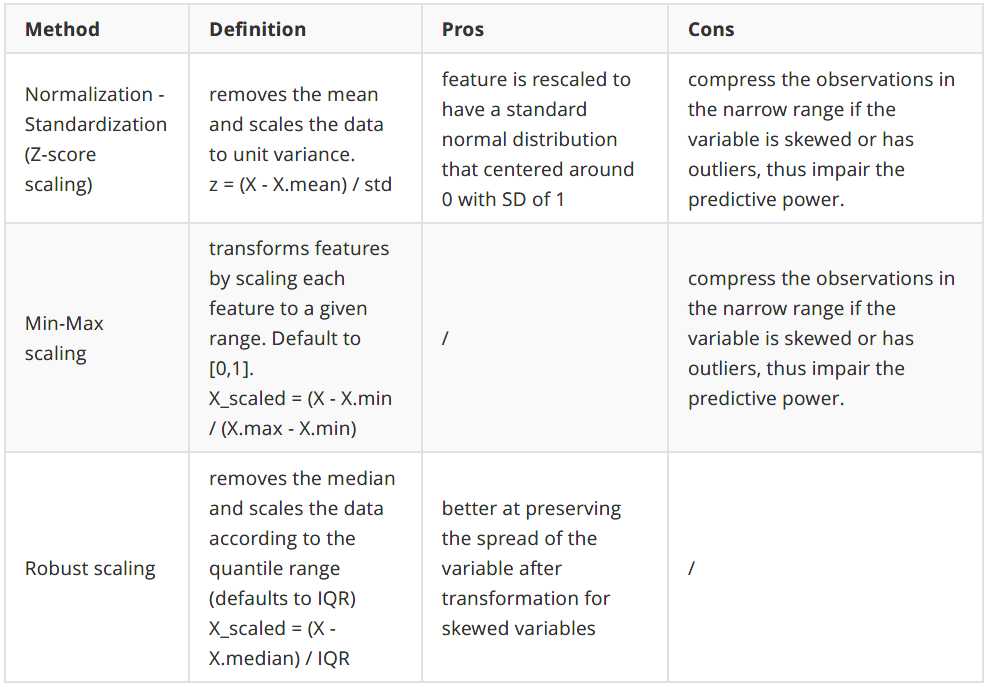
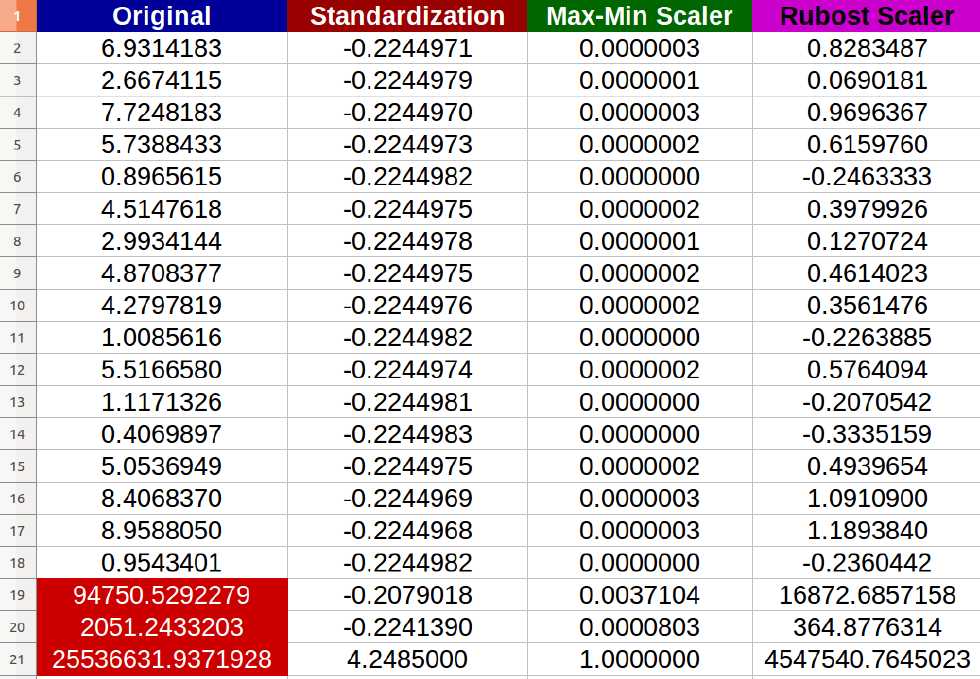
- 如果你的特征不是高斯分布,比如,有偏态分布或者有异常值,归一化标准化不是一个好的选择,因为它会将大多数数据压缩到一个很窄的范围内。然而,我们可以将特征转换成高斯like,然后使用归一化-标准化。特征变换将在3.4节中讨论
- 在进行距离或协方差计算(如聚类、PCA和LDA等算法)时,最好使用Normalization - Standardization ,因为它可以消除尺度对方差和协方差的影响。
- Min-Max scale与规范化-标准化具有相同的缺点,并且新数据可能不会被限制到[0,1],因为它们可能超出原始范围。一些算法,例如一些深度学习网络更喜欢0-1范围的输入所以这是一个很好的选择
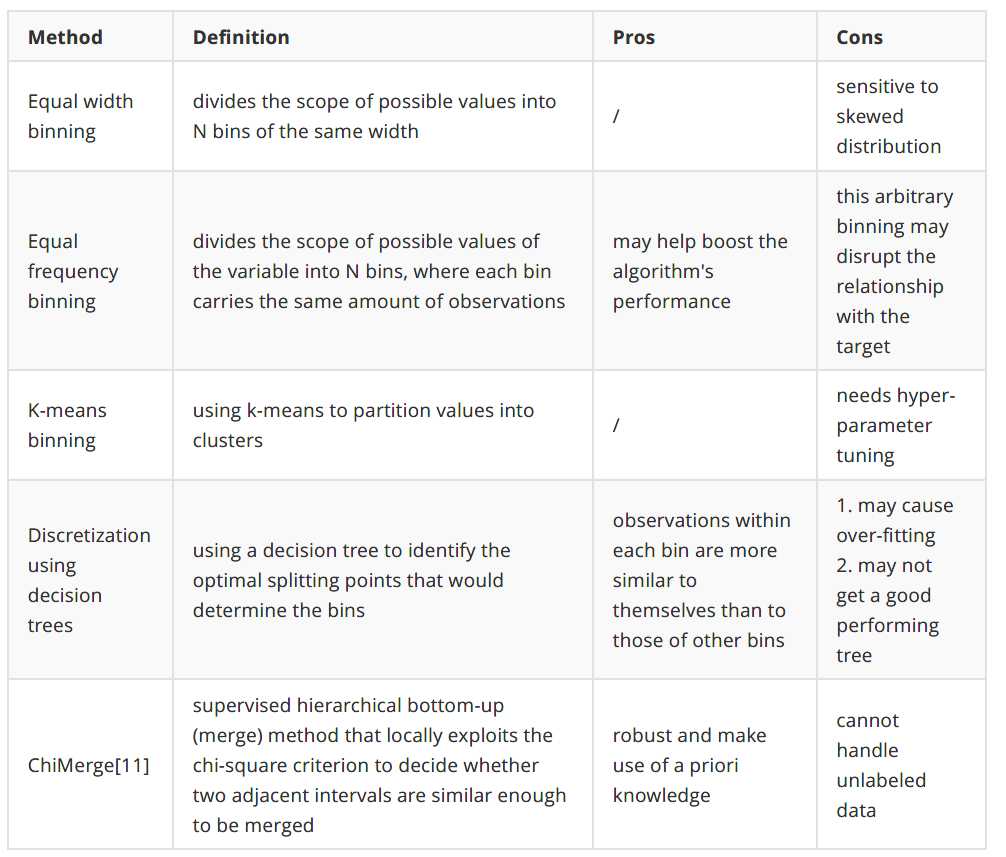
2.Discretize
离散化是通过创建一组跨越变量值范围的连续区间将连续变量转换为离散变量的过程。
为什么要离散化:
- 通过将具有相似预测能力的相似属性分组来帮助改进模型性能
- 引入非线性,从而提高模型的拟合能力
- 使用分组值增强可解释性
- 尽量减少极值/极少值的影响
- 防止数值变量可能的过拟合
- 允许连续变量之间的特征交互
如何离散化:
一般来说,没有最佳的离散化方法。它真的取决于数据集和下面的学习算法。在做决定之前,仔细研究你的特征和背景。您还可以尝试不同的方法并比较模型性能
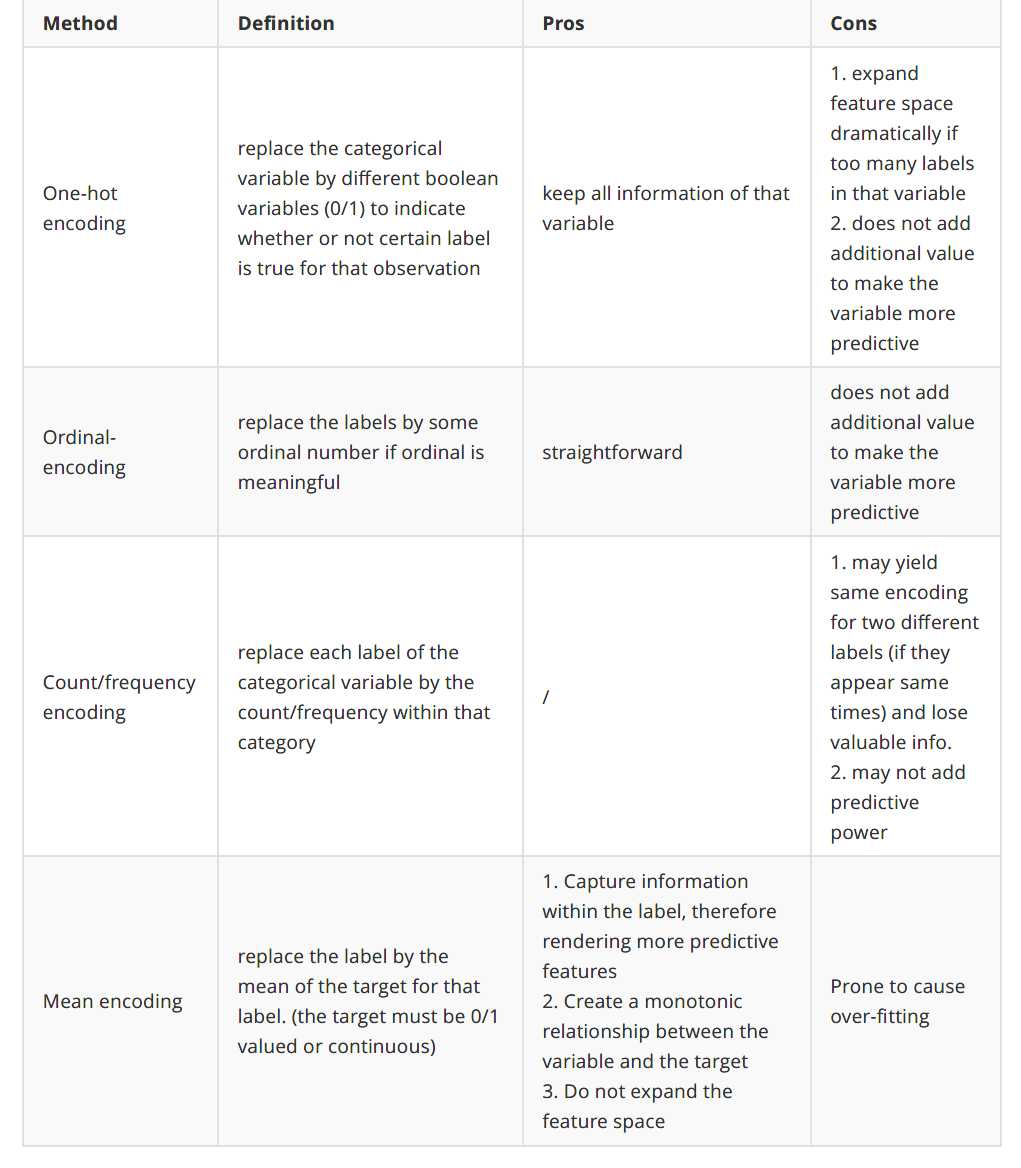
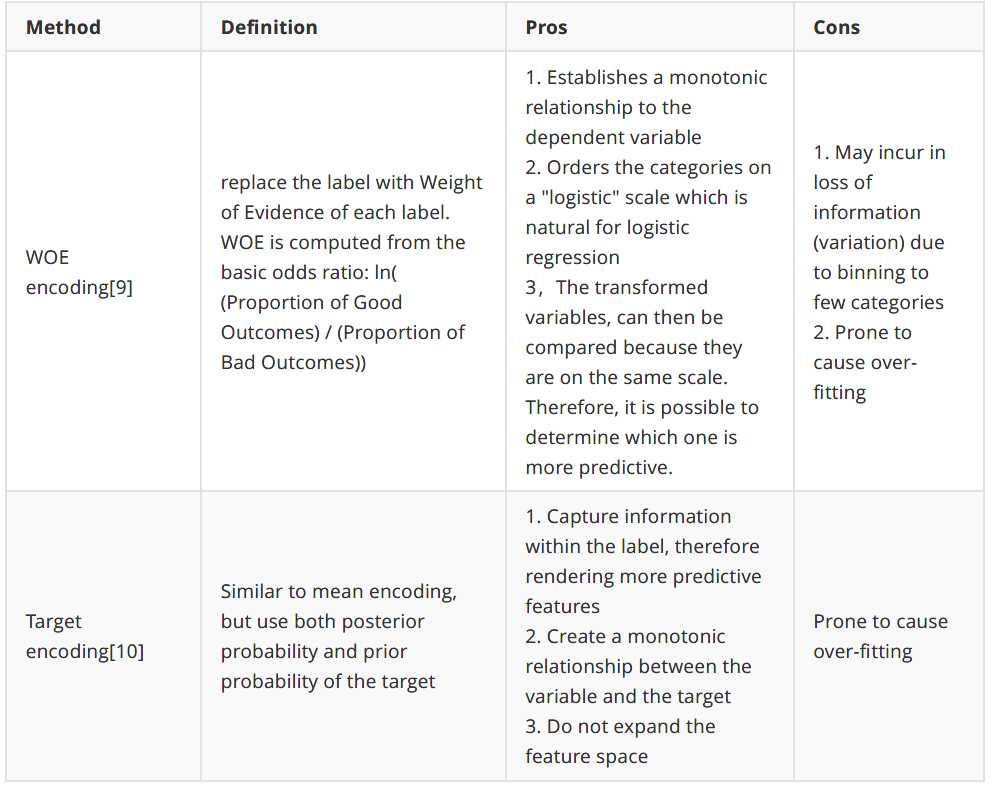
3.Feature Enconding
我们必须将分类变量的字符串转换成数字,这样算法才能处理这些值。即使您看到一个算法可以接受分类输入,该算法也很可能包含编码过程。
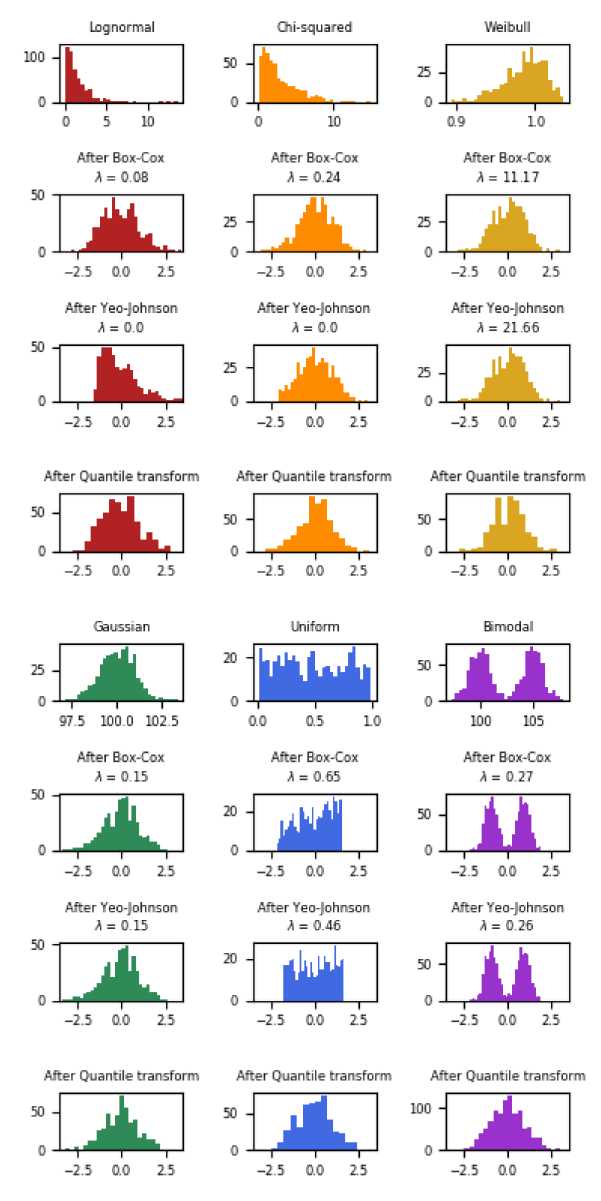
4.Feature Transformation
为什么要进行feature transformation:
- 当用linear regression时数据应符合线性回归条件
- 有时会假设数据符合正态分布,当数据不符合正态分布时结果不行。为什么模型可以从“高斯分布”中受益?在正态分布的变量中,可以用来预测Y的X的观测值在更大的范围内变化,即X的值为“散布”在更大的范围内。在上述情况下,对原变量进行变换可以使变量更接近于钟形的高斯分布。
如何进行feature transformation:


5.Feature Generation
将现有特征组合起来创建新特征。这是向数据集添加领域知识的好方法
例如:
- 我们可以为丢失数据添加binary feature(0/1)来说明数据是否缺失
- 通过统计添加统计特征:以通话记录为例,我们可以创建如下新功能:通话次数、呼入/呼出次数、平均通话时长、每月平均通话时长、最大通话时长等。
- count/sum
- average/median/mode
- max/min/stddev/variance/range/IQR/coefficient of Variation
- time span/ interval
- feature crossing: 将derived feature互相交叉,用于交叉的常见维度包括:时间,区域,业务类型。还是以通话记录为例,我们可以交叉使用以下功能:夜间/白天的通话次数、不同业务类型(银行/出租车服务/旅行/医院)下的通话次数、过去3个月的通话次数等。第3.5.2节中提到的许多统计计算可以再次用于创建更多的特性
- ratios and proportions:例如,为了预测一个分支机构信用卡销售的未来表现,像信用卡销售/销售人员或信用卡销售/营销支出这样的比率比仅仅使用分支机构所销售的信用卡的绝对数量更有效。
- cross Products between categorical features:考虑一个分类特征a,它有两个可能的值{A1, A2}。设B为可能性为{B1的特征,B2}。然后,a和B之间的特征交叉会取以下值之一:{(A1, B1), (A1, B2), (A2, B1),(A2, B2)}。你基本上可以给这些“组合”起任何你喜欢的名字。只需记住,每个组合表示a和B的相应值所包含的信息之间的协同作用。这是一个非常有用的技术,当某些特征一起表示一个属性时比单独表示它们更好。从数学上讲,你是在做分类特征所有可能值的叉乘。这一概念与3.5.3节中的特征交叉相似,但这一概念特别指的是两个范畴特征之间的交叉
- Polynomial Expansion:积也适用于数值特性,导致一个新的交互功能a和b之间可以很容易地sklearn PolynomialFeatures,生成一个新的特性集组成的所有多项式组合特性的程度小于或等于指定的程度。例如,三个原始特征{X1, X2, X3}可以生成{1,X1X2, X1X3, X2X3,X1X2X3},度为2
- Feature Learning by Trees:在基于树的算法中,每个样本将被分配到一个特定的叶节点。每个节点的决策路径可以看作是一个新的非线性特征,我们可以创建N个新的二进制特征,其中N等于树或树总体中的叶节点总数。然后可以将这些特征输入其他算法,如逻辑回归。本文首先介绍了Facebook使用树算法生成新特征的思想。这种方法的优点是我们可以得到几个特征的复杂组合,这是有信息性的(由树的学习算法构造)。与手工交叉相比,节省了大量的时间,在网络广告行业的点击率中得到了广泛的应用。
- Feature Learning by Deep Networks:这些特征的可解释性有限,深度学习需要更多的数据才能提取出高质量的结果。
以上是关于04_特征工程的主要内容,如果未能解决你的问题,请参考以下文章