降维线性判别分析LDA
Posted hhhuang
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了降维线性判别分析LDA相关的知识,希望对你有一定的参考价值。
降维,线性判别分析
本博客根据 百面机器学习,算法工程师带你去面试 一书总结归纳,公式都是出自该书.
本博客仅为个人总结学习,非商业用途,侵删.
网址 http://www.ptpress.com.cn
目录
- LDA推导
- LDA扩展到多维度
- PCA与LDA的区别
LDA原理
线性判别分析(Linear Discriminant Analysis, LDA) 是一种有监督学习算
法, 同时经常被用来对数据进行降维。
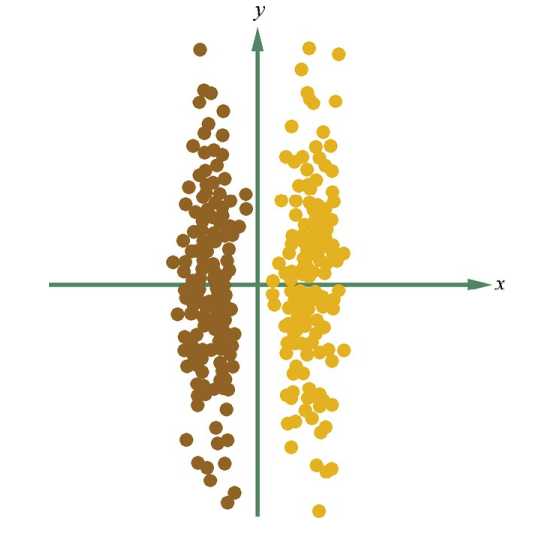
在PCA中, 算法没有考虑数据的标签(类别) , 只是把原数据映射到一些方差比较大的方向上而已。 如下图中,用不同的颜色标注C1、 C2两个不同类别的数据 ,根据PCA算法, 数据应该映射到方差最大的那个方向, 亦即y轴方向。 但是, C1, C2两个不同类别的数据就会完全混合在一起, 很难区分开。 所以, 使用PCA算法进行降维后再进行分类的效果会非常差。 但是, 如果使用LDA算法, 数据会映射到x轴方向。
LDA首先是为了分类服务的, 因此只要找到一个投影方向ω, 使得投影后的样
本尽可能按照原始类别分开。 我们可以从一个简单的二分类问题出发,有(C_1,C_2)两个类别的样本,两类的均值分别为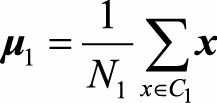 ,
,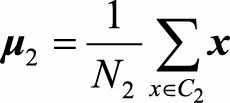 。我们希望投影之后两类之间的距离尽可能大,距离表示为:
。我们希望投影之后两类之间的距离尽可能大,距离表示为:
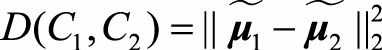
其中 , ,
, 表示两类的中心在ω方向上的投影向量,=(ω^Tμ_1), = (ω^Tμ_2),因此需要优化的问题为:
表示两类的中心在ω方向上的投影向量,=(ω^Tμ_1), = (ω^Tμ_2),因此需要优化的问题为:
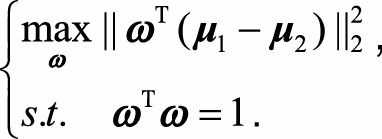
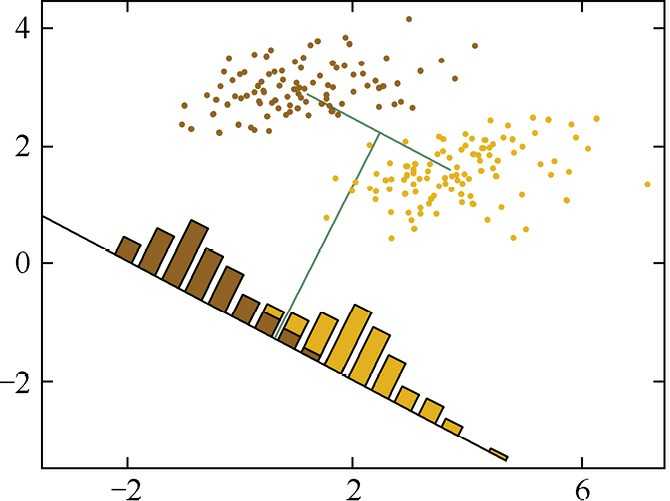
容易发现, 当ω方向与((μ_1?μ_2))一致的时候, 该距离达到最大值。例如对下图中的黄棕两种类别的样本点进行降维时, 若按照最大化两类投影中心距离的准则, 会将样本点投影到下方的黑线上。 但是原本可以被线性划分的两类样本,
经过投影后有了一定程度的重叠。
我们希望投影后的结果如下图中所示,虽然两类的中心在投影之后的距离有所减小,但确使投影之后样本的可区分性提高了。
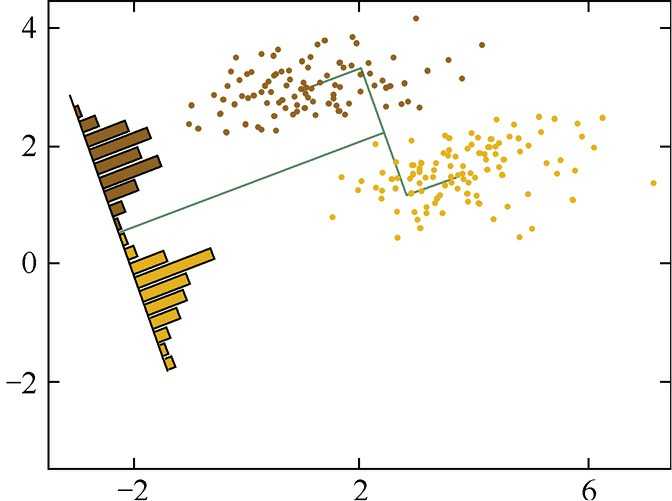
由此,我们可以观察两种投影的方式,发现第二种投影后的样本点似乎在每一类中分布得更为集中了。所以LDA得中心思想就是--最大化类间距离和最小化类内距离。
在前面我们已经找到了类间距离尽可能大的投影方式,现在只需要同时优化类内方差,使其尽可能小。
我们将整个数据集的类内方差定义为各个类内方差之和, 将目标函数定义为类间距离和类内距离的比值, 于是引出我们需要最大化的目标
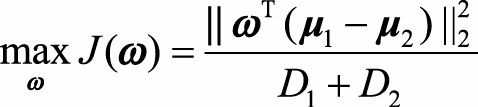
其中ω为单位向量, (D_1,D_2)分别表示两类投影后的方差,两个类内方差公式为:
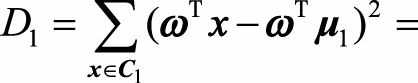
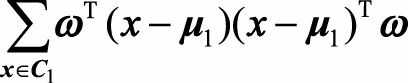
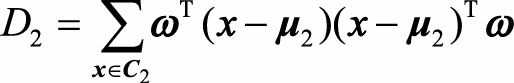
因此J(ω)可以写成
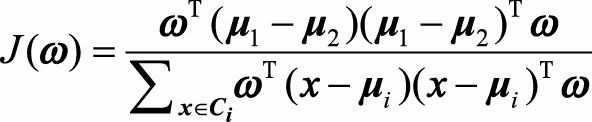
定义类间散度矩阵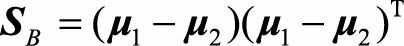 ,类内散度矩阵
,类内散度矩阵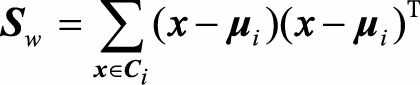 。则目标式子可以写为:
。则目标式子可以写为:
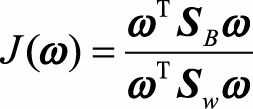
我们要最大化J(ω), 只需对ω求偏导, 并令导数等于零
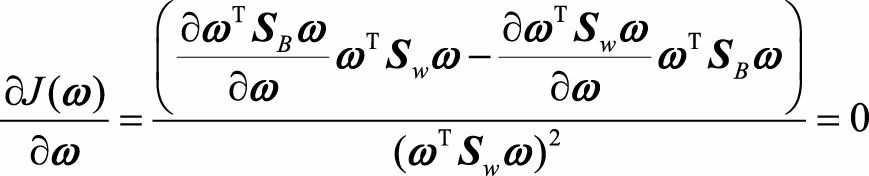
于是得出, 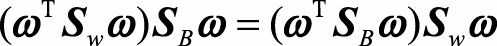
由于在简化的二分类问题中(ω^TS_wω)和(ω^TS_Bω)是两个数,我们令:
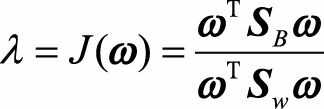 ,
,
于是可以把结果写成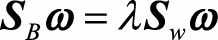 ,整理得
,整理得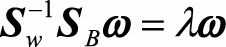
从这里我们可以看出,我们最大化的目标对应了一个矩阵的特征值,于是LDA降维变成了一个求矩阵特征向量的问题。J(ω)就对应了矩阵 (S_w^{?1}S_B)最大的特征值, 而投影方向就是这个特征值对应的特征向量。
对于二分类这一问题, 由于(S_B)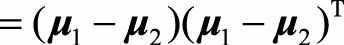 ,因此(S_Bω)的方向始终与((μ_1?μ_2))一致,如果只考虑ω的方向,不考虑其长度,可以得到(ω=S_w^{?1})(μ_1?μ_2)$。换句话说,我们只需求样本均值和类内方差,就可以马上得到最佳的投影方向ω。
,因此(S_Bω)的方向始终与((μ_1?μ_2))一致,如果只考虑ω的方向,不考虑其长度,可以得到(ω=S_w^{?1})(μ_1?μ_2)$。换句话说,我们只需求样本均值和类内方差,就可以马上得到最佳的投影方向ω。
将LDA扩展到多类高维的情况
假设有N个类别, 并需要最终将特征降维至d维。 因此, 我们要找到一个d维投影超平面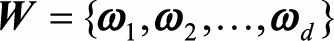 ,使得投影后的样本点满足LDA的目标--最大化类间距离和最小化类内距离。
,使得投影后的样本点满足LDA的目标--最大化类间距离和最小化类内距离。
对两个散度矩阵,类内散度矩阵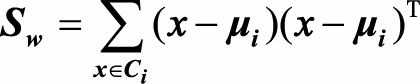 在类别增加至N时仍满足定义, 而之前两类问题的类间散度矩阵 在类别增加后就无法按照原始定义。
在类别增加至N时仍满足定义, 而之前两类问题的类间散度矩阵 在类别增加后就无法按照原始定义。
如下图中是三类样本的分布情况,其中(μ_1,μ_2,μ_3)分别表示棕绿黄三类样本
的中心, μ表示这三个中心的均值(也即全部样本的中心) , (S_{wi})表示第i类的类内散度。
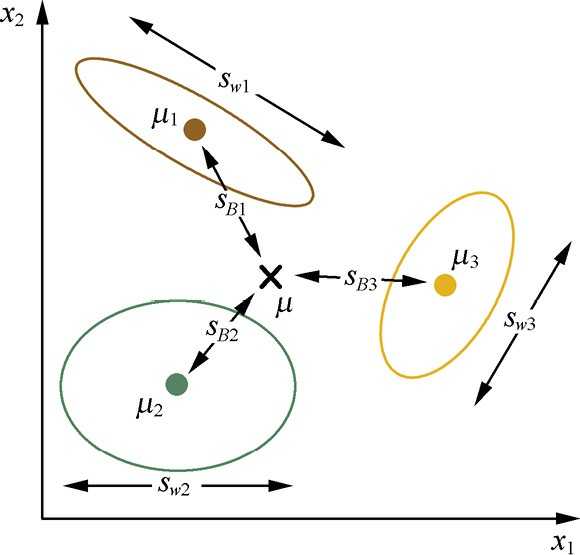
由上图,我们可以定义一个新的矩阵(S_t),来表示全局整体的散度,成为全局散度矩阵:
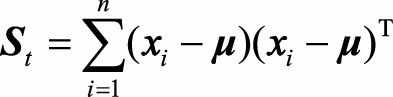
如果把全局散度定义为类内散度与类间散度之和, 即(S_t=S_b+S_w), 那么类间散度矩阵可表示为
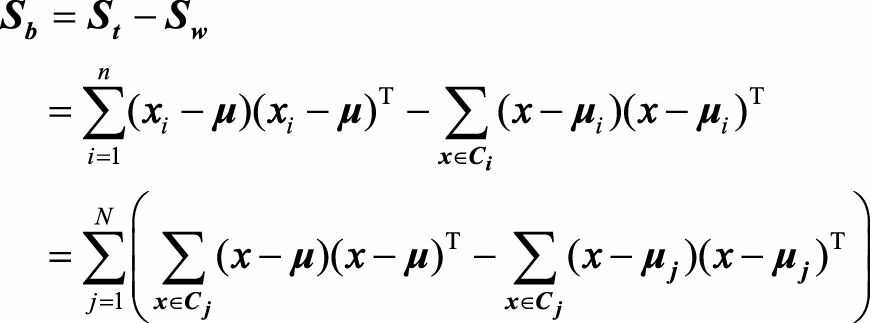
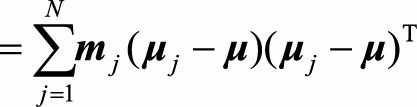 其中(m_j)是第j个类别中的样本个数, N是总的类别个数。
其中(m_j)是第j个类别中的样本个数, N是总的类别个数。
从上式看出,类间散度表示的就是每个类别中心到全局中心的一种加权距离。我们最大化类间散度实际上优化的是每个类别的中心经过投影后离全局中心的投影足够远。
根据LDA的原理, 可以将最大化的目标定义为
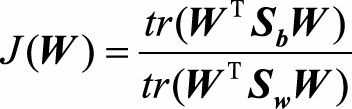
其中W是需要求解的投影超平面,(W^TW = I),根据前面问题的讨论,我们可以推导出最大化J(W)对应了以下广义特征值求解的问题
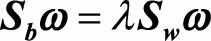
求解最佳投影平面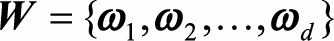 即求解(S_w^-1S_b)矩阵特征值前d大对应的特征向量组成的矩阵, 这就将原始的特征空间投影到了新的d维空间中。我们可以得到下面的求解LDA步骤:
即求解(S_w^-1S_b)矩阵特征值前d大对应的特征向量组成的矩阵, 这就将原始的特征空间投影到了新的d维空间中。我们可以得到下面的求解LDA步骤:
1 计算数据集中每个类别样本的均值向量(μ_j), 及总体均值向量μ。
2 计算类内散度矩阵(S_w), 全局散度矩阵(S_t), 并得到类间散度矩阵(S_b=S_t-S_w)。
3 对矩阵(S_w^-1S_b)进行特征值分解, 将特征值从大到小排列
4 取特征值前d大的对应的特征向量
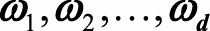 ,通过以下映射将n维样本
,通过以下映射将n维样本
映射到d维
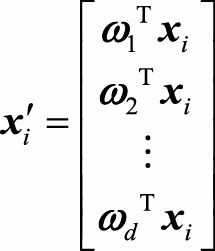
PCA与LDA的区别
从PCA和LDA两种降维方法的求解过程来看, 它们确实有着很大的相似性,但对应的原理却有所区别。
从目标角度
- PCA选择的是投影后数据方差最大的方向。由于它是无监督的, 因此PCA假设方差越大, 信息量越多, 用主成分来表示原始数据可以去除冗余的维度, 达到降维。
- 而LDA选择的是投影后类内方差小、 类间方差大的方向。 其用到了类别标签信息, 为了找到数据中具有判别性的维度, 使得原始数据在这些方向上投影后, 不同类别尽可能区分开。
从应用的角度,可以掌握一个基本的原则——对无监督的任务使用PCA进行降维, 对有监督的则应用LDA。
以上是关于降维线性判别分析LDA的主要内容,如果未能解决你的问题,请参考以下文章
机器学习——降维(主成分分析PCA线性判别分析LDA奇异值分解SVD局部线性嵌入LLE)