压缩感知
Posted wangyinan0214
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了压缩感知相关的知识,希望对你有一定的参考价值。
恢复算法
1、L1 minimization

这是一个凸优化问题,类似于统计学中的LASSO。
优化算法有:

特点:
![]()
L1最小化的其他形式:

2、Matching Pursuit
MP算法(匹配追踪算法)
算法描述:
作为对信号进行稀疏分解的方法之一,将信号在完备字典库上进行分解。假定被表示的信号为y,其长度为n。假定H表示Hilbert空间,在这个空间H里,由一组向量{x1,x2,…,xn}构成字典矩阵D,其中每个向量可以称为原子(atom),其长度与被表示信号y的长度n相同,而且这些向量已作为归一化处理,即||xi||=1,也就是单位向量长度为1。MP算法的基本思想:从字典矩阵D(也称为过完备原子库中),选择一个与信号y最匹配的原子(也就是某列),构建一个稀疏逼近,并求出信号残差,然后继续选择与信号残差最匹配的原子,反复迭代,信号y可以由这些原子来线性和,再加上最后的残差值来表示。很显然,如果残差值在可以忽略的范围内,则信号y就是这些原子的线性组合。MP进行信号分解的步骤:
1)计算信号y与字典矩阵中每列(原子)的内积,选择绝对值最大的一个原子,它就是与信号y在本次迭代运算中最匹配的。用专业术语来描述:令信号y∈H,从字典矩阵中选择一个最为匹配的原子,满足|<y,xr0>|=supi∈(1,…,k) |<y,xi>|,r0表示一个字典矩阵的列索引。这样,信号y就被分解为在最匹配原子xr0的垂直投影分量和残值两部分,即:y=<y,xr0>xr0+R1f。
2)对残值R1f进行步骤1)同样的分解,那么第K步可以得到:
Rkf=<Rkf ,xrk+1> xrk+1+ Rrk+1f,
其中xrk+1满足|<Rkf, xrk+1>|=supi∈(1,…,k) |<Rkf, xi>|。
Note:
(1)为什么要假定在Hilbert空间中?Hilbert空间就是定义了完备的内积空。很显然,MP中的计算使用向量的内积运算,所以在在Hilbert空间中进行信号分解理所当然了。
(2)为什么原子要事先被归一化处理了,即上面的描述。内积常用于计算一个矢量在一个方向上的投影长度,这时方向的矢量必须是单位矢量。MP中选择最匹配的原子是,是选择内积最大的一个,也就是信号(或是残值)在原子(单位的)垂直投影长度最长的一个。
(3)MP算法是收敛的,因为得出的每一个残值比上一次的小,故而收敛。
MP算法的缺点:
如上所述,如果信号(残值)在已选择的原子进行垂直投影是非正交性的,这会使得每次迭代的结果并不少最优的而是次最优的,收敛需要很多次迭代。举个例子说明一下:在二维空间上,有一个信号y被D=[x1, x2]来表达,MP算法迭代会发现总是在x1和x2上反复迭代,即这个就是信号(残值)在已选择的原子进行垂直投影的非正交性导致的。由于MP仅能保证,所以一般情况下是次优的。不是说MP一定得到不到最优解,而且其前面描述的特性导致一般得到不到最优解而是次优解。
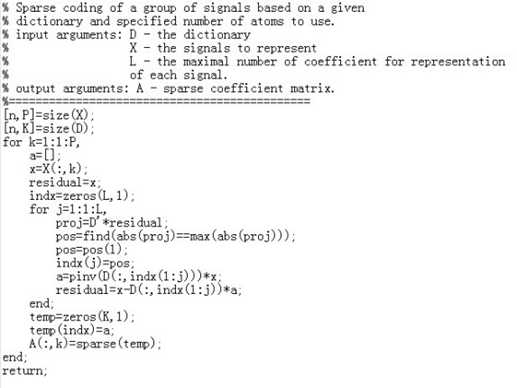
3、OMP算法
算法描述:
OMP算法的改进之处在于:在分解的每一步对所选择的全部原子进行正交化处理,这使得在精度要求相同的情况下,OMP算法的收敛速度更快。
算法伪代码:

矩阵描述:


算法程序代码:
国外学者的描述(更为严谨):

特点:

以上是关于压缩感知的主要内容,如果未能解决你的问题,请参考以下文章