MHA部署实现高可用
Posted security-guard
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了MHA部署实现高可用相关的知识,希望对你有一定的参考价值。
三、修改密码后,配置主从
1、c731主服务器操作
vim /etc/my.cnf [mysqld] server-id=1 log-bin=mysql-bin relay_log_purge=0 //禁止mysql自动删除relaylog功能 gtid_mode = on //mysql 5.6的特性,开启gtid,必须主从全开 enforce_gtid_consistency = 1 log_slave_updates = 1
重启mysql
systemctl restart mysql
创建同步的用户
mysql -p123456 mysql> grant all privileges on *.* to mha@‘192.168.37.%‘ identified by ‘mha‘; mysql> flush privileges;
查看mysql主库的master状态
mysql> show master statusG *************************** 1. row *************************** File: mysql-bin.000001 Position: 151
查看GTID状态
mysql> show global variables like ‘%gtid%‘; +---------------------------------+------------------------------------------+ | Variable_name | Value | +---------------------------------+------------------------------------------+ | binlog_gtid_simple_recovery | OFF | | enforce_gtid_consistency | ON | | gtid_executed | f27d0522-4e44-11ea-a692-000c2918e47a:1-2 | | gtid_mode | ON | | gtid_owned | | | gtid_purged | | | simplified_binlog_gtid_recovery | OFF | +---------------------------------+------------------------------------------+ 7 rows in set (0.00 sec)
2、c732从服务器操作
vim /etc/my.cnf [mysqld] server-id=2 log-bin=mysql-bin relay_log_purge = 0 gtid_mode = on enforce_gtid_consistency = 1 log_slave_updates = 1
重启mysql
systemctl restart mysql
创建同步的用户
mysql -uroot -p123456 mysql> grant replication slave on *.* to ‘rep‘@‘192.168.37.%‘ identified by ‘123456‘; Query OK, 0 rows affected (0.00 sec) mysql> flush privileges; Query OK, 0 rows affected (0.00 sec)
关闭从服务器的复制功能
mysql -p123456
mysql> stop slave;
配置从服务器指向master
mysql> stop slave; Query OK, 0 rows affected, 1 warning (0.00 sec) mysql> change master to master_host=‘192.168.37.31‘, -> master_user=‘rep‘, -> master_password=‘123456‘, -> master_log_file=‘mysql-bin.000001‘, -> master_log_pos=534; Query OK, 0 rows affected, 2 warnings (0.01 sec)
开启从服务器的复制功能 mysql> start slave; Query OK, 0 rows affected (0.00 sec)
开启slave后,默认有relay-log日志了
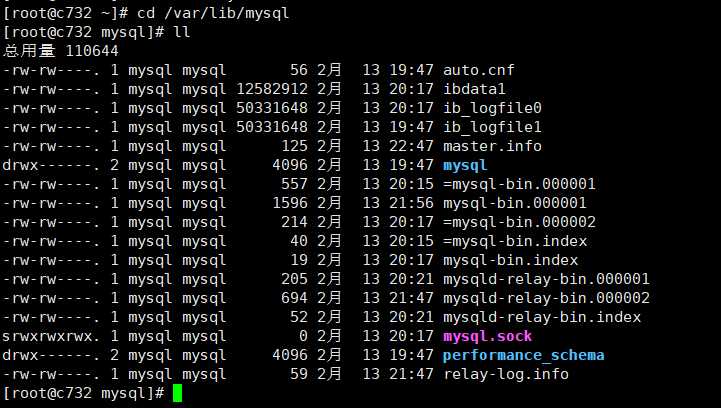
查看从服务器的状态
mysql> show slave status G *************************** 1. row *************************** Slave_IO_State: Waiting for master to send event Master_Host: 192.168.37.31 Master_User: rep Master_Port: 3306 Connect_Retry: 60 Master_Log_File: mysql-bin.000001 Read_Master_Log_Pos: 534 Relay_Log_File: mysqld-relay-bin.000002 Relay_Log_Pos: 314 Relay_Master_Log_File: mysql-bin.000001 Slave_IO_Running: Yes Slave_SQL_Running: Yes
其中启动slave时可能会出现MySQL的ERROR 1872,导致slave无法正常启动
解决办法:
使用RESET SLAVE 语句,清除master信息和relay日志的信息,删除所有relay日志文件,并开始创建一个全新的中继日志
mysql>stop slave;
mysql>reset slave;
3、c733从服务器操作
vim /etc/my.cnf [mysqld] server-id=3 log-bin=mysql-bin relay_log_purge = 0 gtid_mode = on enforce_gtid_consistency = 1 log_slave_updates = 1 重启mysql systemctl restart mysql
创建同步的用户
mysql> grant replication slave on *.* to ‘rep‘@‘192.168.37.31‘ identified by ‘123456‘; Query OK, 0 rows affected (0.00 sec) mysql> flush privileges; Query OK, 0 rows affected (0.00 sec)
关闭从服务器的复制功能 mysql> stop slave; Query OK, 0 rows affected, 1 warning (0.00 sec)
配置从服务器指向master mysql> change master to master_host=‘192.168.37.31‘, -> master_user=‘rep‘, -> master_password=‘123456‘, -> master_log_file=‘mysql-bin.000001‘, -> master_log_pos=534; Query OK, 0 rows affected, 2 warnings (0.02 sec) mysql> start slave ; Query OK, 0 rows affected (0.00 sec)
查看状态
mysql> show slave status G *************************** 1. row *************************** Slave_IO_State: Waiting for master to send event Master_Host: 192.168.37.31 Master_User: rep Master_Port: 3306 Connect_Retry: 60 Master_Log_File: mysql-bin.000001 Read_Master_Log_Pos: 534 Relay_Log_File: mysqld-relay-bin.000002 Relay_Log_Pos: 314 Relay_Master_Log_File: mysql-bin.000001 Slave_IO_Running: Yes Slave_SQL_Running: Yes
GTID讲解:

四、准备MHA,首先下载rpm包,其次配置环境
!!!三台机器同时操作以下步骤
1.1、安装依赖
yum install perl-DBD-MySQL -y
yum install -y perl-Config-Tiny epel-release perl-Log-Dispatch perl-Parallel-ForkManager perl-Time-HiRes
1.2、授权MHA管理用户
grant all privileges on *.* to mha@‘192.168.37.%‘ identified by ‘mha‘; flush privileges;
1.3、安装MHA node节点
上传mha4mysql-node-0.58-0.el7.centos.noarch.rpm ,然后安装 rpm -ivh mha4mysql-node-0.58-0.el7.centos.noarch.rpm
切记安装依赖,也可以使用nodeps (不推荐使用)
rpm -ivh mha4mysql-manager-0.58-0.el7.centos.noarch.rpm --nodeps --force
2.1、安装MHA管理节点
安装MHA管理端,这里选择c733(永远不会切换为主库的节点)
注意:MHA不要安装到mysql主从库上,否则会在后面出现vip无法漂移等情况
rpm -ivh mha4mysql-manager-0.58-0.el7.centos.noarch.rpm
2.2、配置MHA
创建两个文件夹
mkdir -p /etc/mha mkdir -p /var/log/mha/app1
编辑MHA配置文件
[server default] manager_log=/var/log/mha/app1/manager.log manager_workdir=/var/log/mha/app1 master_binlog_dir=/var/lib/mysql #binlog的目录,如果说miysql的环境不一样,binlog位置不同,每台服务器的binlog的位置写在server标签里面即可 user=mha password=mha ping_interval=2 repl_password=123456 repl_user=rep ssh_user=root [server1] hostname=192.168.37.31 port=3306 [server2] hostname=192.168.37.32 port=3306 [server3] hostname=192.168.37.33 port=3306 ignore_fail=1 #如果这个节点挂了,mha将不可用,加上这个参数,slave挂了一样可以用 no_master=1 #从不将这台主机转换为master #candidate_master=1 #如果候选master有延迟的话,relay日志超过100m,failover切换不能成功,加上此参数后会忽略延迟日志大小。 #check_repl_delay=0 #用防止master故障时,切换时slave有延迟,卡在那里切不过来
在配置文件后面不要有空格和注释,推荐用 d+$ 删除行后所有字符
2.3、启动测试
ssh检查检测
[root@c733 ~]# masterha_check_ssh --conf=/etc/mha/app1.cnf
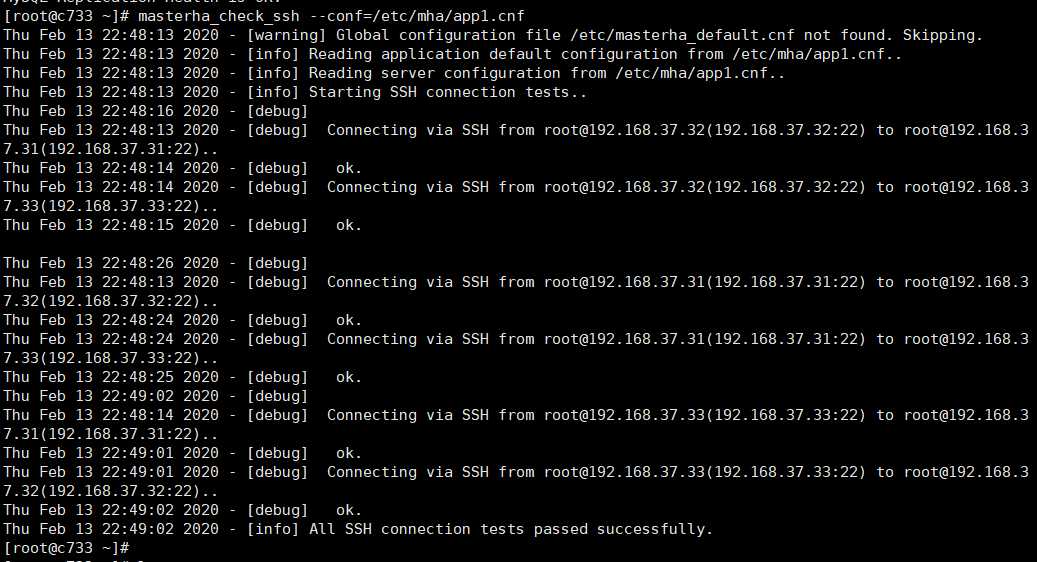
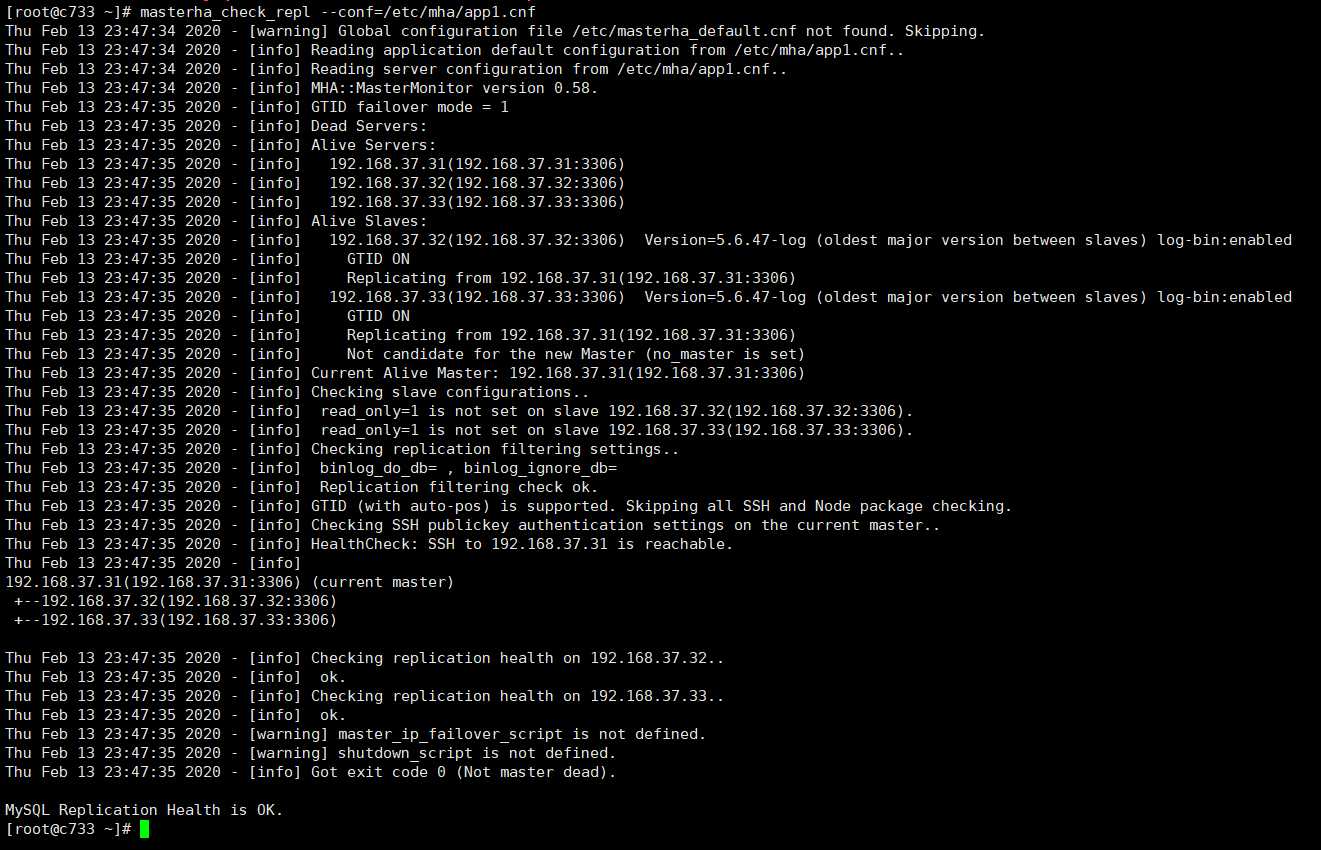
主从复制检测
[root@c733 ~]# masterha_check_repl --conf=/etc/mha/app1.cnf
以上是关于MHA部署实现高可用的主要内容,如果未能解决你的问题,请参考以下文章