One Stage目标检测
Posted dengshunge
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了One Stage目标检测相关的知识,希望对你有一定的参考价值。
在计算机视觉中,目标检测是一个难题。在大型项目中,首先需要先进行目标检测,得到对应类别和坐标后,才进行之后的各种分析。如人脸识别,通常是首先人脸检测,得到人脸的目标框,再对此目标框进行人脸识别。如果该物体都不能检测得到,则后续的分析就无从入手。因此,目标检测占据着十分重要的地位。在目标检测算法中,通常可以分成One-Stage单阶段和Two-Stage双阶段。而在实际中,我经常接触到的是One-Stage算法,如YOLO,SSD等。接下来,对常接触到的这部分One-stage单阶段目标检测算法进行小结。本文one stage检测算法包括有YOLO系列,SSD,FSSD,DSOD,Tiny DSOD,RefineNet,FCOS。
YOLO
YOLO可以说是最早的One-stage目标检测算法之一,经过作者的优化,存在3个版本。
-
YOLO V1
Yolo v1在《You Only Look Once: Unified, Real-Time Object Detection》中提出。在Yolo之前的目标检测算法,如R-CNN系列,其网络相对比较复杂,耗时大,难以优化(因为每个单独的部分是独立训练的)。因此,作者将目标检测认为是一个独立的回归任务,回归每个分离的预测框坐标及其对应的类别概率,使其具有以下的优点:
- 运行速度非常快。使用Yolo算法,其FPS为45,而Fast Yolo的FPS为150。同时,mAP也能达到以往实时目标检测系统的两倍。
- 使用全局信息进行推理。
- 可以学习到抽象的特征。
介绍完Yolo的优点后,我们来看看其思想,如下图所示。首先,Yolo将一张输入图片分成S*S格。如果GT框的中心落在某格(grid cell)上,则该格负责预测这个目标。每格会预测B个预测框及B个置信度得分。该置信度得分反映的是该格包含物体的置信度和这个预测框有多准。因此,对于该置信度得分,其定义为$Pr(Object)*IOU^{truth}_{pred}$。如果没有物体的中心在该格上,则该置信度得分为0;如果有物体的中心在该格上,则我们希望置信度得分等于IOU。因此,对于每个预测框而言,都会预测5个值,分别是中心点$(x,y)$,宽高$(w,h)$,和上述的置信度得分。
对于每格而言,除了预测B个预测框及其置信度外,还会预测C个类别的条件概率$Pr(Class_i|Object)$。以VOC0712为例,就会预测$C=20$个类别的概率。这个概率是条件概率,在存在目标的前提下,其为第i类的概率。每格会共用这样的概率,与B个预测框无关。在测试阶段,每格类别的置信度得分等于类别的条件概率乘以每格预测框的置信度得分:
$$Pr(Class_i|Object)*Pr(Object)*IOU^{truth}_{pred}=Pr(Class_i)*IOU^{truth}_{pred}$$
可以看出,每格类别的置信度不仅表示了这个类别出现的概率,而且也反映了预测框是否拟合GT框。
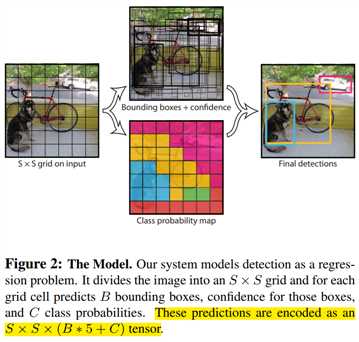
在该论文中,$S=7,B=2$,所以最后输出的是$7*7*30$的张量,可以看成是49个30维的向量,这30维的向量包含了如下图的信息。
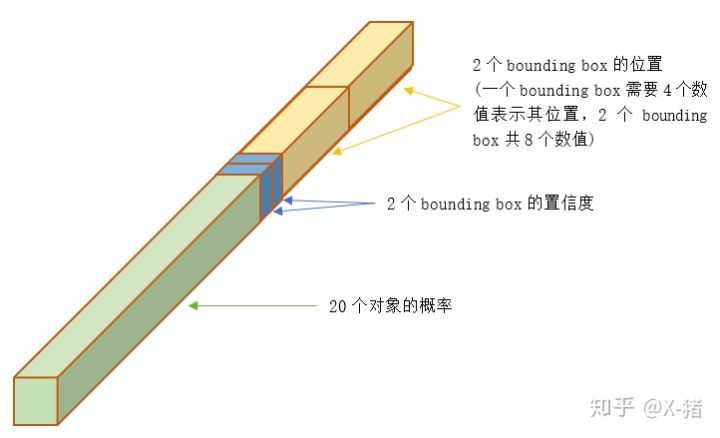
值得留意的是,Yolo并没有预设不同大小的anchor。网络进行前向运算后,每格会输出2个预测框,将该预测框与GT框进行匹对和计算IOU,此时才能确定使用IOU大的那个预测框来负责预测该对象。因此,Yolo的损失函数是各项误差平方和的一个加权:
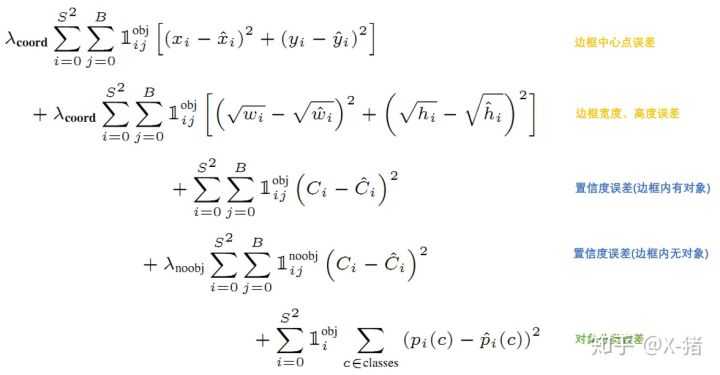
其中,$1^{obj}_i$表示物体的中心是否位于第i格,$1^{obj}_{ij}$表示第i个格子的第j个预测框中存在对象,$1^{noobj}_{ij}$表示第i格子的第j个预测框中不存在对象。损失函数的第一项表示当第i个格子的第j个预测框中存在对象时,其中心点偏移的误差;第二项表示当第i个格子的第j个预测框中存在对象时,宽高的误差;第三项表示当第i个格子的第j个预测框中存在对象时,其置信度得分误差,真实的$C_i$应该等于IOU;第四项表示当第i格子的第j个预测框中不存在对象时,其置信度得分误差,真实的$C_i$应该等于0;第五项表示当物体中心在第i格时,其类别误差。其中,还有$lambda _{coord}$调整预测框位置误差的权重,$lambda _{noobject}$调整不存在目标的预测框的置信度权重,一般是调低不存在对象的预测框的置信度误差的权重。
Yolo v1的不足:
- 当密集场景或者小目标时,检测效果不佳。因为一个格子只负责预测两个框,一个类别。
- 定位误差大。
- 召回率低。
参考资料:
-
YOLO V2
Yolo v2在《YOLO9000: Better, Faster, Stronger》中提出。为了解决Yolo v1的不足,作者使用了融合了多种思路来提高了网络的性能,使得mAP得到大幅度提升;为了加快推理速度,使用新的模型结构;为了能检测出更多的对象,提出了新的联合训练机制,结合分类数据集(如ImageNet)和检测数据集(如COCO和VOC),使得YOLO V2能检测出更多的类别。
在提高网络性能上,作者使用了以下的思路:
- Batch Normalization。在所有卷积层后面加上BN层,使得Yolo算法有2%的mAP提升。同时,因为有了BN层,可以去除dropout层。
- High Resolution Classifier。在Yolo v1中,先使用224*224的输入图片训练分类网络,然后再使用448*448的输入图片训练检测网络。这样意味着Yolo v1必须同时切换去检测任务和调整网络以适应新的输入。因此,在v2版本中,直接使用448*448的输入图片先训练分类网络,然后再微调网络来适应检测任务。
- Convolutional with anchor boxes。在Yolo v1中,每个cell中预测两个预测框,这两个预测框是直接对坐标和置信度进行预测的。在v2版本中,借鉴了锚点框的思想,对每个cell设置锚点框,对锚点框的偏差进行预测。这样能简化问题,而且使网络更容易学习。
- Dimension clusters。使用聚类算法来设计锚点框。在Faster R-CNN中,锚点框是手工设计,这样的设计方式不一定很好适配检测任务。如果锚点框的初始化设置比较好,能使网络更容易得到好的检测结果。因此,使用k-means聚类算法来设计锚点框。在聚类算法中,最重要的是如何设计两个框之间的“距离”,这里使用$d(box,centroid)=1-IOU(box,centroid)$作为距离度量的方式,当IOU越大时,两个框之间的“距离”越小。在v2版本中,使用5种边框种类就能与Faster RCNN中的9种边框种类的效果相近。(同时,在工作中我也发现,一个较好的锚点框设置,能较大幅度提高检测效果)
- Direct location prediction。在Faster RCNN中,由于没有对预测框进行限制,所以预测框的中心可能会出现在任何位置,导致训练早期不稳定。因此,Yolo v2在使用锚点框后,对锚点框的预测进行了限制,将预测框的中心约束在该cell中。
- Fine-Grained Features。与SSD不同,Yolo v2使用一种不同的方式来提高小目标的检测效果,引入了pass through层来保留更加细节的信息。具体做法是,在最后一个pool层之前,其特征图大小是26*26*512,将其一拆成四,变成13*13*2048,直接传递到pool层之后,与13*13*1024的特征图进行concat起来,构成13*13*3072的特征图。
- Multi-Scale Training。由于Yolo v2只有卷积层和池化层,所以其对输入图片的大小没有限制。作者想让Yolo具有更强大的鲁棒性,所以使用不同大小的输入图片来训练网络,每训练10个batch,就随机更换输入图片的尺寸。这种做法,有点类似图像金字塔。
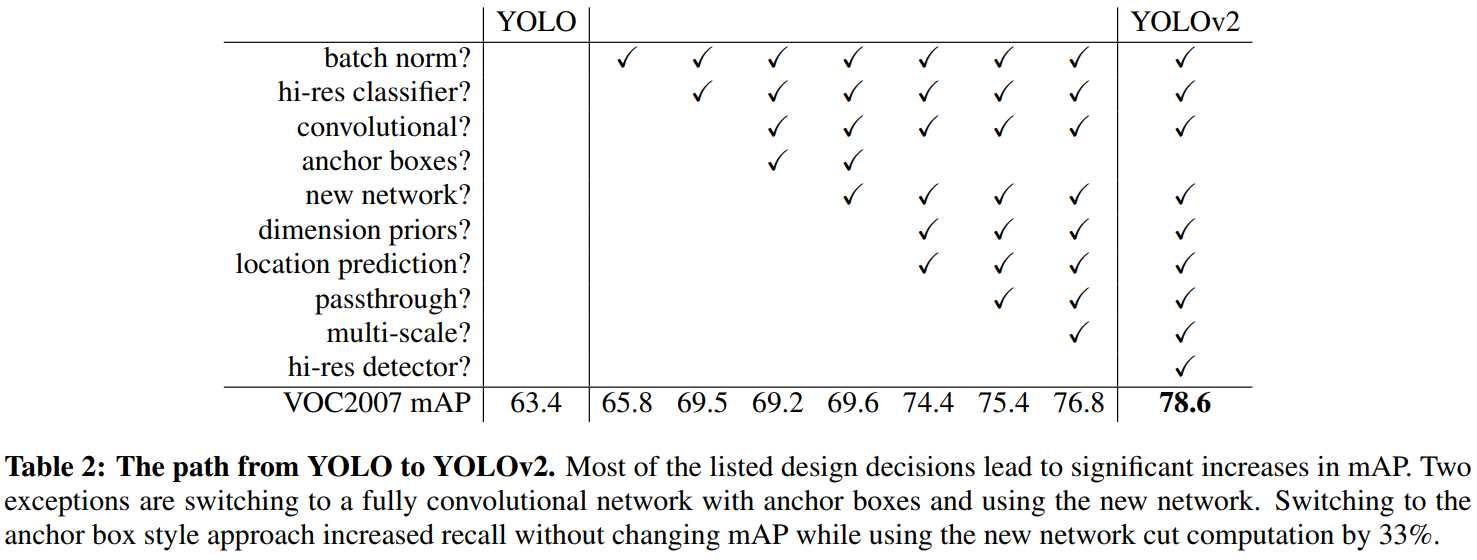
将上述的思想融合起来,最终的实验效果如下图所示。实验效果的增幅还是挺明显的,将v2提高了近15个点的mAP。
作者不仅想让Yolo v2的mAP更高,而且还想让其更快。在v1中,使用的网络结构是基于Inception的,其速度比VGG快,但性能略逊色于VGG。因此,作者提出了新的分类网络,Darknet-19,作为Yolo v2的主干网络,如下图所示。该网络中含有19个卷积层和5个池化层。
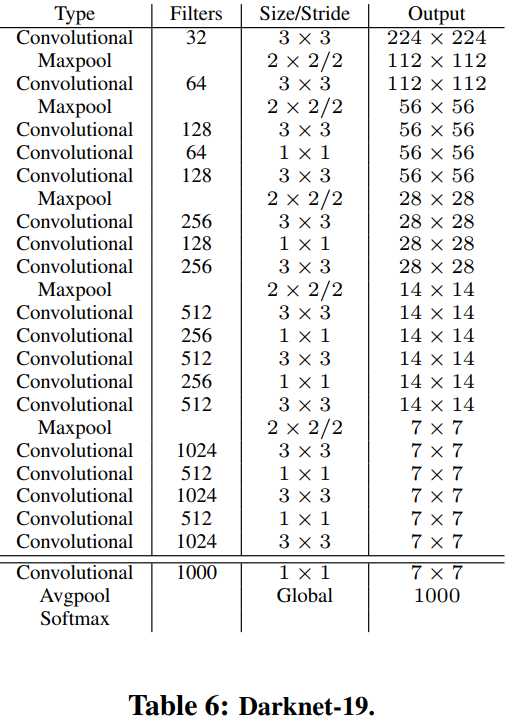
YOLO v2的训练主要包括三个阶段。第一阶段就是先在ImageNet分类数据集上预训练Darknet-19,此时模型输入为224*224 ,共训练160个epochs。然后第二阶段将网络的输入调整为448*448 ,继续在ImageNet数据集上finetune分类模型,训练10个epochs,此时分类模型的top-1准确度为76.5%,而top-5准确度为93.3%。第三个阶段就是修改Darknet-19分类模型为检测模型,移除最后一个卷积层、global avgpooling层以及softmax层,并且新增了三个 3*3*1024卷积层,同时增加了一个pass through层,最后使用 1*1 卷积层输出预测结果,输出的channels数为:num_anchors*(5+num_classes) ,和训练采用的数据集有关系。由于anchors数为5,对于VOC数据集(20种分类对象)输出的channels数就是125,最终的预测矩阵T的shape为 (batch_size, 13, 13, 125),可以先将其reshape为 (batch_size, 13, 13, 5, 25) ,其中 T[:, :, :, :, 0:4] 为边界框的位置和大小$(t_x,t_y,t_w,t_y)$,T[:, :, :, :, 4] 为边界框的置信度,而 T[:, :, :, :, 5:] 为类别预测值。
在VOC数据集中,只有20类物体可以进行检测。但实际生活中,物体的类别数是远远大于20种的。因此作者想结合分类数据集和检测数据集来进行联合训练,使得检测的类别数能大幅度提高。这种联合训练方式的基本思想是,如果是检测样本,其loss就包含分类误差和定位误差;如果是分类样本,其loss就只包含分类误差。
由于我没有对这一块做过多研究,了解不深。但该方法最主要的是构建Word Tree。因为数据集的不同,导致每个标签之间不是互斥的,存在包含关系,例如在COCO数据集中的一个类别是“狗”,而在ImageNet中包含了多种狗的标签。所以,通过构建word tree来将所有标签信息串联起来,类似于“树”的结构,父节点包含了不同类别的子结构。
参考资料:
-
YOLO V3
Yolo v3提出于《YOLOv3: An Incremental Improvement》中,在v2版本上,进一步进行了改进,总体来说,改进力度有限,下面来分别看看这些改进措施。
首先,在预测类别时,不使用softmax,而是使用logistic进行预测。因为这样有利于多标签预测。当使用复杂领域的数据集时,可能会出现标签不互斥的情况(如woman和person),使用多标签的方法会更加有利于模型,即使用logistic
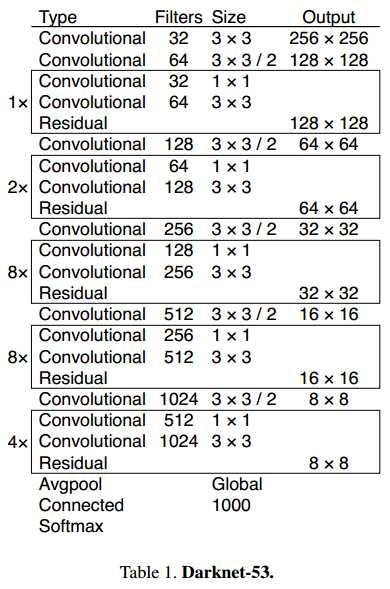
第二,使用了新的网络Darknet-53,如下图所示。在v2中,使用的backbone是Darknet-19,而在v3中,不仅网络层数增加了,而且还借鉴了ResNet的思想,使用多个连续的3*3和1*1卷积层,并且带有shortcut连接。根据作者提供的实验比较,在ImageNet中,Darknet-53具有与ResNet-152相似的准确率,但速度是其两倍。
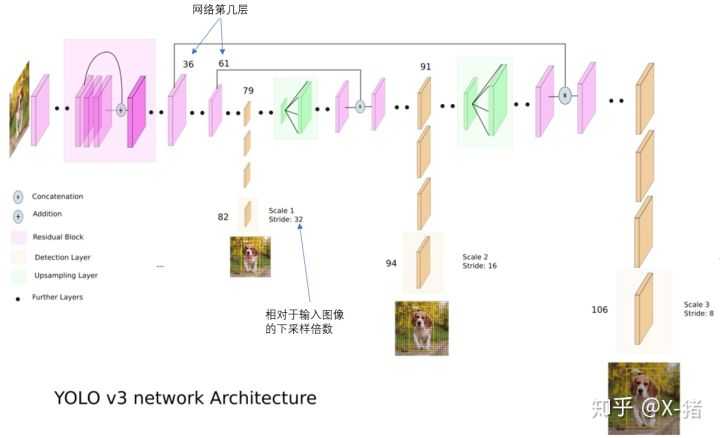
第三,利用多尺度信息来进行预测。这里借用一下这位博主的图,其整体的网络结构,如下图所示。在v3中,利用了不同尺度的信息进行预测,我认为作者的这种方式,其应该是借鉴了FPN的思想。使用3个尺度的特征图进行预测,如图上黄色方块表示的一样,在第79层后,进行上采样,上采样得到的特征图与第61层的特征图进行融合,再进行上采样,与第36层的特征图融合。
第四,使用K-means聚类得到锚点框的尺寸。和v2版本采用方法一致,v3这里使用了3个不同尺寸的特征图进行预测,在每层特征图中使用3种不同尺寸的锚点框,如下图所示。为小尺寸的特征图分配大尺寸的锚点框,适合检测大目标;为大尺寸的特征图分配小尺寸的锚点框,适合检测小目标。

以COCO为例,v3使用3个特征图来进行预测,每个特征图会对应3种锚点框,因此,对于每层特征图,其输出的tensor为$N*N*[3*(4+1+80)]$,其中,$N$表示特征图的尺寸,$3$表示3个锚点框,$4$表示4个坐标值,$1$表示是否包含物体的置信度(v3的置信度貌似与v1中的置信度不一样),$80$表示COCO数据集的类别总数。
参考资料:
SSD
SSD算法提出于《SSD:Single Shot MultiBox Detector》 中,同样是一篇非常经典的one stage目标检测算法,其框架也衍生出了很多系列。之前,我曾经对SSD进行过总结和代码复现,想仔细了解的可以参考来阅读以下,这里主要是概括性回顾以下。
如下图所示,是SSD的框架网络,其使用了6个不同尺寸的特征图来进行预测,分别是$(38*38),(19*19),(10*10),(5*5),(3*3),(1*1)$。这6个特征层会分别经过3*3的卷积后分成分类头和检测头,分别用于预测坐标偏差值和类别置信度(包含背景)。相比于YOLO V1和YOLO V2,SSD使用了多个特征层,更适合检测多种不同尺度的目标。
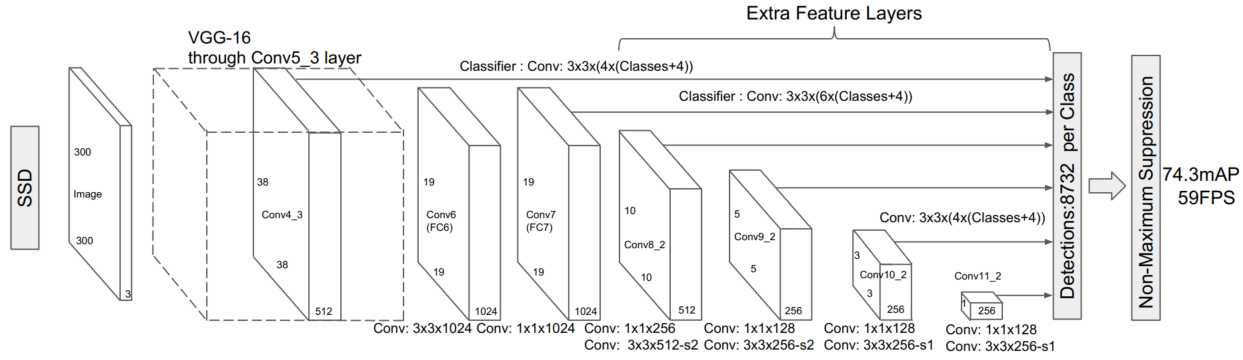
其次,在这6个不同尺寸的特征图中,还使用了不同大小和宽高比的锚点框。每个特征图使用不同于其他层的锚点框尺寸,而在该尺寸上又设置4种或者6种不同的宽高比。在大尺寸特征图是同小尺寸的锚点框,来检测小目标;在小尺寸的特征图使用大尺寸的锚点框,来检测大目标。这样的设置方式,往后很多SSD系列都采取这种方式。因此,整个SSD中,会检测8732个锚点框的坐标偏差值和类别置信度。
第三,使用了OHEM进行难例挖掘,来缓解正负样本的不平衡。在SSD中,并没有使用所有的负样本,而是将这些匹配上背景的样本根据置信度损失进行降序排列,将损失较大的样本认为是难例(hard negative),需要模型重点学习。选取损失最大的前N个样本作为负样本,正样本与负样本的比例控制在1:3左右,对于那些没有选上的样本,label设置成-1,不参与训练当中。
作者还强调了数据增强对网络性能有着明显提升。可以这么理解,通过数据增强,间接提高了数据量和样本之间的多样性,从而提高了模型的鲁棒性。另外,空洞卷积同样可以提高了SSD的mAP,通过空洞卷积,是能在参数量不变的前提下感受野变大,使网络能“看”到的东西更多。
FSSD
FSSD提出于《FSSD: Feature Fusion Single Shot Multibox Detector》中,使用了轻量化的FPN结构,来提高SSD的小目标检测效果。
在SSD中,对小目标的检测效果不佳,召回率低。因为小目标通常是浅层网络来进行预测的,特征抽象能力不足,缺乏语义信息;其次,小目标检测通常严重依赖于上下文信息。因此,FPN的提出是为了使浅层特征和深层特征进行融合,更好的辅助浅层特征来进行目标检测,进而提高小目标的检测效果。FPN的结构如下图的(c)所示。(b)是YOLO v1和v2系列的结构示意图;(d)是SSD系列的结构示意图。
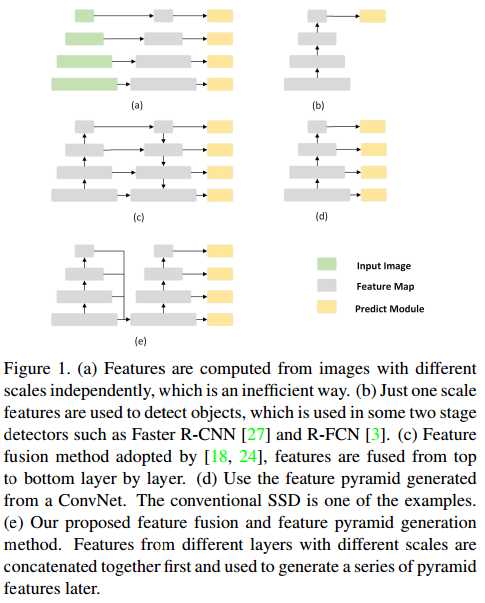
在FPN结构中,右边的特征层是只由上一层的右边特征层和同一层的左边特征层进行融合的,缺乏不同层特征层之间的融合;其次,上一层的右边特征层和同一层的左边特征层的融合是十分耗时的。因此,在FPN的基础上,作者提出了一种轻量化的FPN结构,与SSD进行结合,构成了FSSD,如上图的(e)所示。FSSD的主要思想是,以合适的方式一次性融合所有不同层级的特征层,然后基于此特征层来生成特征金字塔。
FSSD的网络结构如下图所示。作者认为当特征图的尺寸小于$10*10$时,信息特征太少,对特征融合增益不大,因此,使用了conv3_3,conv4_3,fc_7和conv7_2四个特征层来进行融合(图中只画了3个)。首先对这4个特征层进行$1*1$卷积来降低通道数,降低到256维。然后以conv4_3的特征图尺寸$38*38$为基础,其它特征层进行下采样或者上采样来是特征图的尺寸变成$38*38$,至此,所有图中黄色的特征图都有了相同的特征图空间尺寸了。
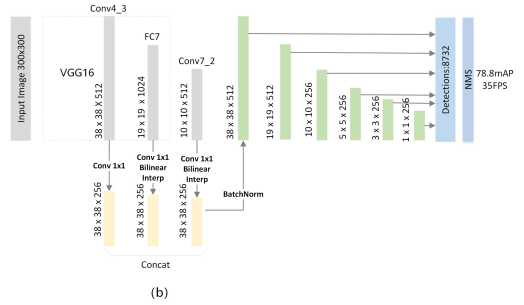
然后对这4个黄色特征图进行融合,融合方式有两种:concat或者ele-sum。通过实验发现,concat的效果更好。因此,将这4个黄色特征图进行concat起来,构成了$38*38*1024$的tensor。由于不同层的特征图的分布是不一致的,因此,对这$38*38*1024$的tensor进行BN操作。最后对融合后的特征层进行下采样(论文中使用bottlenet结构来进行下采样),产生绿色的特征层,使用这些不同尺寸的绿色特征层来进行目标检测。
最终实验表明在牺牲少量速度的前提下,FSSD的mAP比原版的SSD要高,特别是对小目标的召回率提高了很多。
DSOD
DSOD提出于《DSOD: Learning Deeply Supervised Object Detectors from Scratch》中。目前,大部分目标检测算法都需要使用预训练模型来提高检测效果。但是由于分类任务和检测任务的损失函数的类别分布不同,使用预训练模型会引入学习偏差;同时当分类场景和检测场景具有很大差异时,使用预训练模型的效果也不佳。因此,最好的办法是对检测网络进行从头训练,不使用预训练模型。为此,作者提出了DSOD模型来解决从头开始训练的问题。
DSOD的结构如下图的右边所示,左边是SSD的网络结构,右边是DSOD的网络结构。可以看出,DSOD的结构与SSD十分类似,但其主干网络是DenseNet。前面两个特征层是DenseNet主干网络生成的,第1个特征层一路直接送到预测中,另外一路经过pool和conv层后,与第2个特征成concat后再送入预测。随后,会分成2条支路,一路流经pool和conv来进行dowm-sample,另外一路输入到$1*1$和$3*3$的卷积中;两路进行concat后再送入预测。
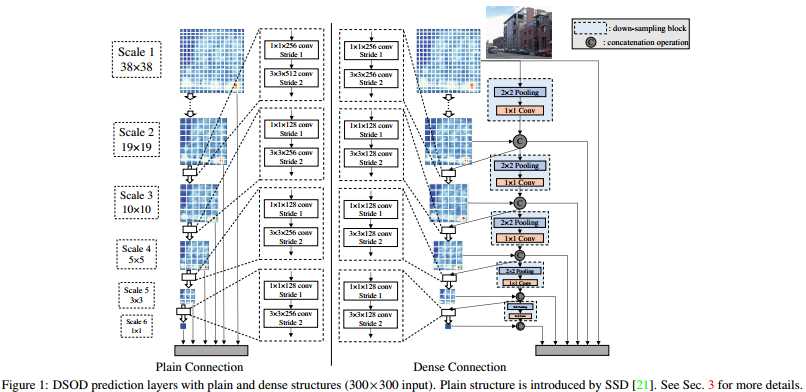
最后,作者总结了下,解决从头训练问题的几条原则:
- Proposal-free。作者发现,当使用了SS算法或者RPN算法来推荐候选区域时,不使用预训练模型会导致模型不收敛。这可能是由于ROI pooling引起的问题,因为ROI pooling从推荐候选区域中生成特征,但这样会阻碍梯度平滑地从region-level回传到卷积特征图中。
- Deep Supervison。深度监督网络,如Inception,DenseNet等,能直接监控更多的隐藏层,而不只是监督最后的输出层。在proposal-free检测框架中,包含了分类损失和定位损失,因此需要增加侧路层来为每个隐藏层引入“共同”的目标。而DenseNet网络使用了skip connections,网络学习一半特征、复用一半特征,因此所有隐藏层能够通过目标函数来接收到额外的监督。
- Stem Block。作者通过更换DenseNet的Stem Block,可以明显提高检测性能。新的Stem Block能够减少原始输入图片的特征损失。
- Dense Prediction Structure。在DSOD中,除了第一个特征层外,其余特征层均是学习一半特征,复用一半特征。这样的方式能够产生更高精度的结构。
综上所述,作者利用DenseNet作为主干网络,提出了DSOD算法,解决了从头训练的问题。
Tiny DSOD
Tiny DSOD提出于《Tiny-DSOD: Lightweight Object Detection for Resource-Restricted Usages》。目前很多目标检测算法对计算资源有限的硬件设备都不太有友好,因此,作者在DSOD的基础上,提出了轻量化的目标检测网络Tiny DSOD。该Tiny DSOD引入了两个创新且高效的结构:depthwise dense block (DDB)和depthwise feature-pyramid-network (D-FPN)。
首先,在DSOD中,使用的主干网络是DenseNet,其结构如下图所示。输入分成两路,经过$1*1*C$和$3*3*C/4$的卷积后,输出C/4个通道的tensor,然后与输入进行concat。这样做的计算成本大。
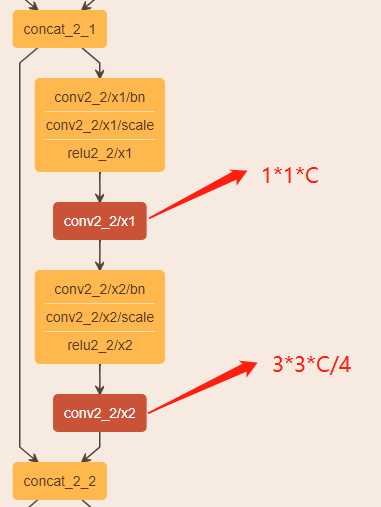
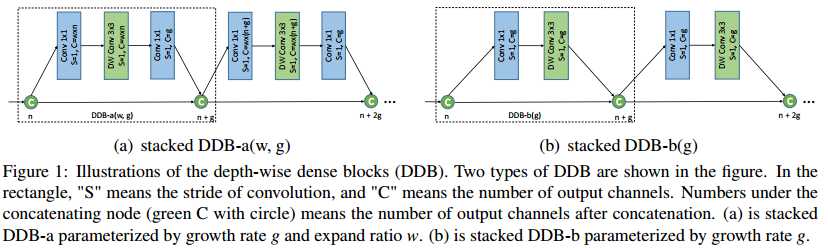
受到MobileNet的启发,作者将深度可分离卷积融合进DenseNet中,并命名为DDB结构。该DDB结构有两种形式,如下图所示。其中,DDB-a中含有倒残差结构的思想,先将有n个通道的输入扩大至$w*n$个通道,$w$表示人为设置的超参,用于控制扩张倍数;然后进行$3*3$的卷积;接着进行$1*1$的卷积,但通道数降至$g$;最后将两者进行concat,形成$n+g$个通道的特征图。可以认为$g$表示DDB-a的增长率。但是,这种结构DDB-a的复杂度是$O(L^3g^2)$,随着网络层数$L$的增加,计算资源消耗也会快速增加,所以要控制增长率$g$,将$g$约束在较小的值。然而,增长率$g$较小,又会使模型的泛化能力变差。
基于上述的考虑,又提出了DDB-b这种结构。输入首先会压缩成$g$维,然后进行$3*3$的卷积,最后将两者进行concat起来,形成$n+g$维的输出。因此,整体的复杂度为$O(L^2g^2)$。在实验中发现,DDB-b这种结构不仅更加高效,而且在资源有限的情况下准确率更高。因此,在Tiny DSOD中,使用了DDB-b这种结构。
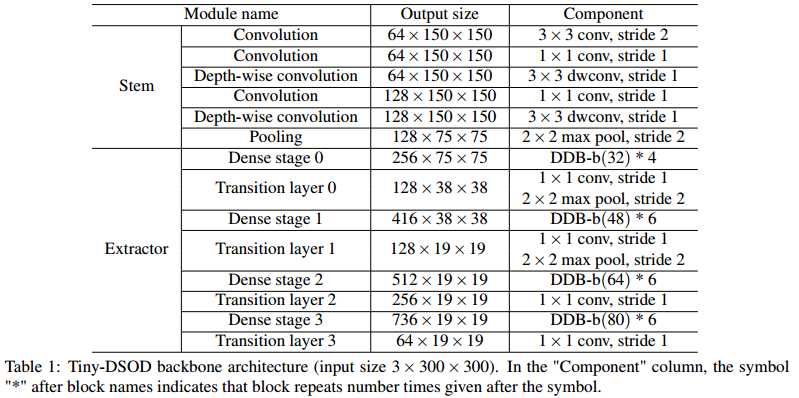
因此,Tiny DSOD的网络结构如下图所示。对于增长率$g$值而言,作者采用了浅层网络使用小$g$值、深层网络采用大$g$值得策略。因为浅层网络的特征图尺寸大,需要消耗更多的计算资源,而$g$值比较小时,能节省部分计算计算。
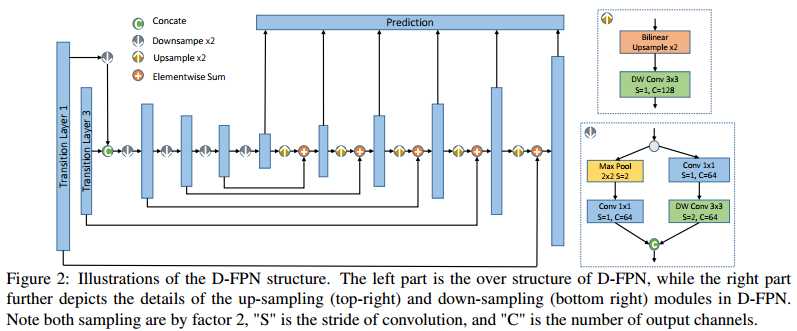
Tiny DSOD的另外一个结构是D-FPN,如下图所示。结合了FPN的思想,设计了一种轻量化的D-FPN结构,来使深层次的语义信息与浅层特征进行融合。这里的downsample结构与DSOD的结构类似,利用多分枝思想,融合不同感受野的信息,但是与DSOD不同的是,输出的通道维数变小了和使用了深度可分离卷积。
综上所示,在DSOD基础上,Tiny DSOD融合了DDB结构和FPN结构,降低计算资源的前提下,同时也提高检测效果。
RefineDet
RefineDet提出于《Single-Shot Refinement Neural Network for Object Detection》中。总所周知,two stage目标检测器能实现较高的精度,而FPS较慢;one stage目标检测器的FPS很高,但却牺牲一定精度。two stage能取得较高的精度,是因为:
- 使用了二级结构的采样结构来解决正负样本不平衡问题;
- 对预测框进行两次回归;
- 使用两段特征来描述物体。
因此,作者对one stage和two stage目标检测器进行取长补短,提出了RefineDet,结构如下图所示,能实现比two stage检测器更高的精度,且能保持较好的运行效率。其中,主要由两个模块组成:anchor refiement module (ARM)和object detection module (ODM)。
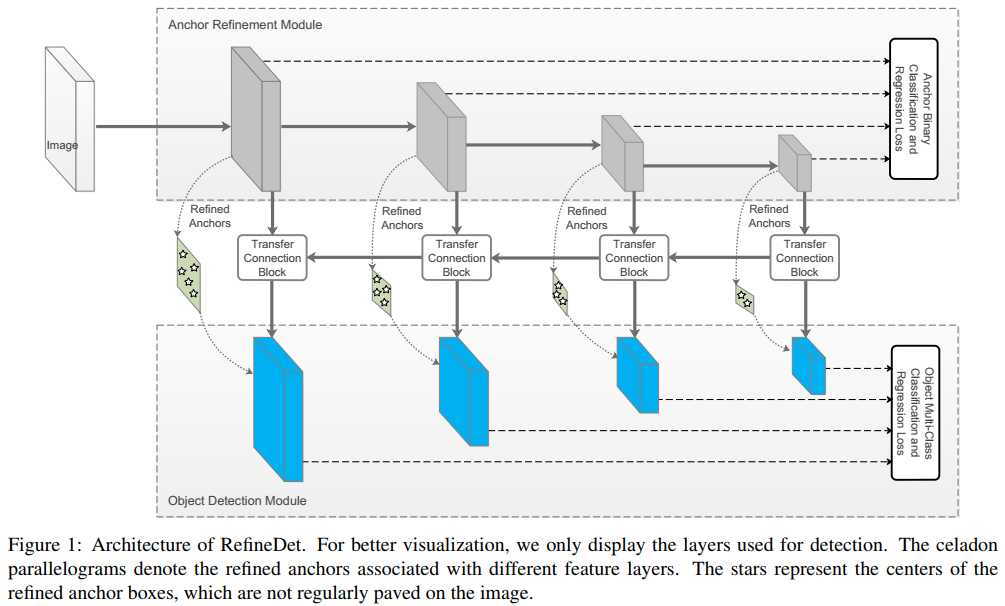
ARM模块主要负责:
- 识别和移除负例锚点框,以此来为分类器减少搜索空间;
- 大致地锚点框的位置和大小,为接下来的回归提供更好的初始化。
ARM模块会先对锚点框进行判断,判断锚点框内是否含有物体,属于二分类;然后再粗调锚点框的位置,来传递给ODM来进一步二次回归。其实这ARM的作用,有点类似Faster R-CNN中的RPN模块。如果ARM中预测出该锚点框属于背景的置信度大于一定阈值时,就会忽略这个锚点框。也就是ARM模块只会给ODM模块传递粗调过的难负例锚点框和粗调过的正锚点框。
而ODM模块主要负责将粗调过的锚点框来对其进行二次坐标回归和类别预测。如图中绿色带星星的方块图,星星表示粗调后的锚点框,传递给ODM,ODM在这基础上来进一步预测。
同时,作者还借鉴了FPN的思想,设计了transfer connection block (TCB)来将ARM中的特征传递给ODM,可以看到,其将深层语义与浅层语义进行融合,这样应该会进一步提高模型的性能。
FCOS
FCOS提出于《FCOS: Fully Convolutional One-Stage Object Detection》中,是一种anchor-free的检测模型。目前,大部分检测模型都是基于预设的锚点框,如SSD系列,作者就思考:目标检测算法是否一定需要锚点框才能取得较好的性能?而基于锚点框的目标检测算法,具有以下的不足:
- 锚点框的数量、宽高比和尺寸都对检测的效果有很大影响,因此这些超参都需要进行调整;
- 即使锚点框经过了进行设计,检测器也很难去处理具有较大形状变化的物体,如小目标;
- 为了提高召回率,基于锚点框的检测器需要在原图上放置很多密集的锚点框,也就是需要密集采样。但大部分锚点框都是负样本,从而又会引起正负样本之间的不平衡;
- 锚点框通常需要涉及到复杂的计算,例如IOU计算。
因此,作者基于全卷积网络,提出FOCS检测模型。该FCOS会在每层特征图的每个特征点上预测四维向量和类别,如下图的左边所示。这四维向量是$(l,t,r,b)$,分别表示该点到检测框四条边的相对距离。同时,当该像素点远离GT框的中心点位置时,会产生很多低质量的预测框。为了抑制这些低质量的预测框,在网络中引入了一个分支“center-ness”,来预测像素点到目标框中心的偏移程度,以此来降低低质量预测框的权重。

因此,FCOS的网络结构,如下图所示。FCOS结合了FPN模块,并对FPN模块进行了相应的修改,$(P6,P7)$是通过$P5$下采样得到的。然后会分成分类头和回归头,分别是4组卷积。最后在分类头处,还有一个Center-ness的分支。
对于特征图$F_i$的每个位置$(x,y)$,会映射回原图的$left (left lfloor frac{s}{2} ight floor +xs,left lfloor frac{s}{2} ight floor +ys ight )$,其中$s$表示该特征层的下采样率。当映射回去后,如果该点位于GT框内,则认为其是正样本,与GT框的标签一致,直接进行回归与预测。如果改变位于多个GT框的交集区域,就将该点指定给面积最小的那个GT框。由于回归的值总是正值,因此在回归头处采用了$e^x$对坐标值进行映射。使用anchor-free这种方式,使负样本的数量减少,有利于正负样本之间的平衡。同时,对于anchor-based的方式,每个特征点有6个或者9个锚点框需要预测,而anchor-free则只需回归一次,整体输出少了9倍左右。
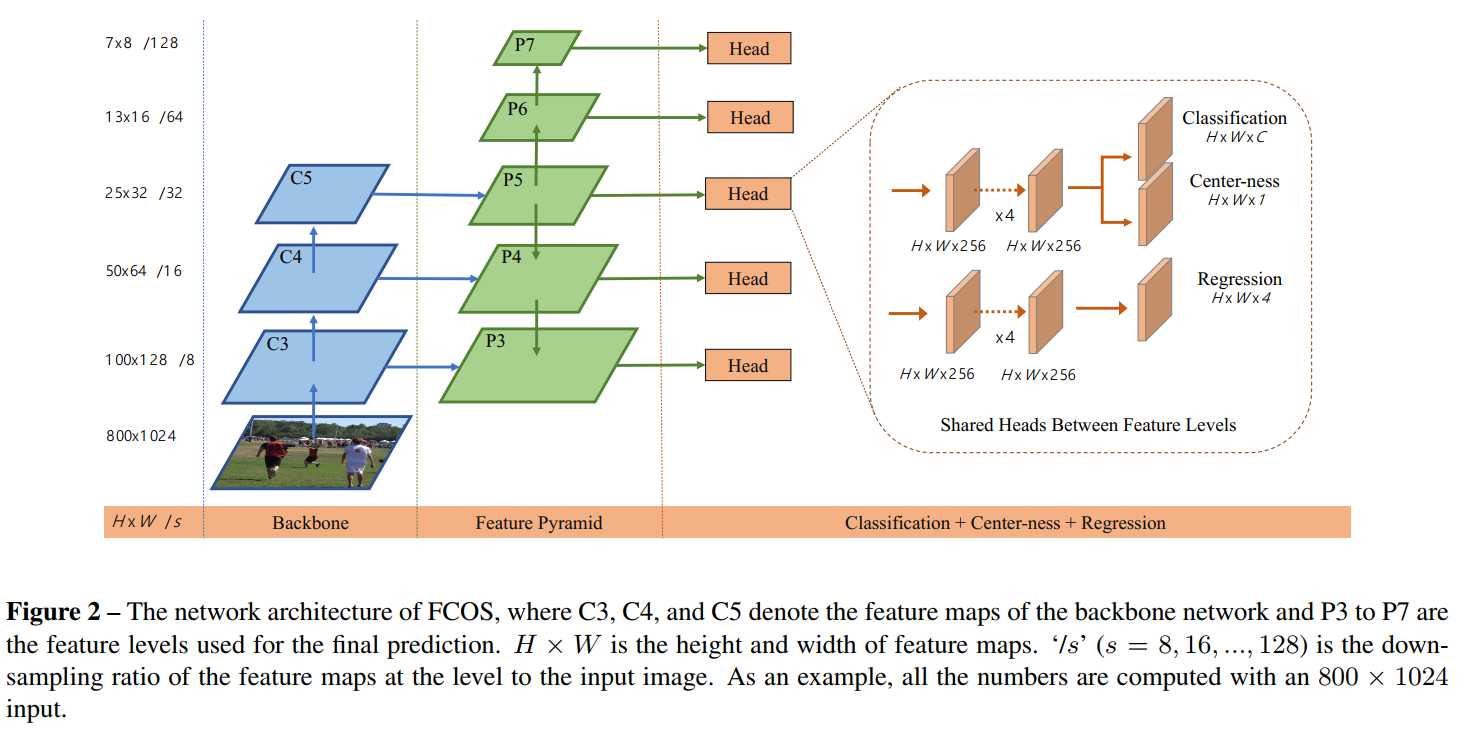
在FCOS中的FPN起到了很重要的作用,主要解决了以下两个大问题:
- 当特征图的下采样率(即stride)较大时,可能会导致较低的最大可能召回率(BPR)。在anchor-based中,可以通过降低IOU得分来缓解这个问题。而对于FCOS来说,直觉上来说,BPR可能会比anchor-based的检测器要低,因为如果下采样后,对应的点都找不到了,就无法映射回原图,就回归不了了。但作者通过大量实验证明,即使是很大的下采样率,使用了FPN的FCOS依然能拥有不错的BPR,甚至超越了RetinaNet。所以,BPR对于FCOS来说不是问题。(这里的结论是作者通过实验做出来的,和对照组的网络配置有关,感觉上FCOS在这方面应该确实是不如anchor-based检测器的。)
- 在多个GT框交集的区域,会出现混淆的现象,即不确定该点应该回归哪个GT框。在这个问题上,作者依然通过实验证明,对于FCOS来说,使用了FPN同样能较好解决这个问题。(感觉作者没有解释清楚这个原因。)
使用了FPN的FCOS,需要在不同特征层处预测不同大小的物体。不像anchor-based那样,为每层特征层指定不同大小的锚点框。FCOS则是首先为每个特征图的位置点计算需要回归的距离$(l^*,t^*,r^*,b^*)$。当$m_{i-1}<max(l^*,t^*,r^*,b^*)<m_i$时,才会认为该点是正样本,送入回归。其中,$m_i$表示第$i$层特征图的最大回归距离。即回归的4个值中的最大值需要位于两个特征层的最大回归距离之间。也可以理解成该特征层只对大小为$[m_{i-1},m_i]$的物体进行回归。当这个最大值超出最大回归距离范围之间时,就认为是负样本,不进行训练。这样做是因为应该对回归进行限制,不可能无限制的回归,进行大值回归可能效果不好,与锚点框的思想一致。
在最后进行预测和回归的时候,FPN中不同特征层共享同一个head(即那4组卷积),这样做不仅节省了参数,而且还提高了检测性能。但是,不同特征层用来回归不同尺寸的目标,让所有特征层共享一个head似乎不太合理。因此,作者使用了一组可以训练的变量$s_i$来为每层特征层自动调整指数函数的底,所以,在回归头处使用的指数函数不再是$e^x$,而是$e^{s_ix}$。
即使使用了FPN,FCOS的性能依然与anchor-based的检测器有差距,原因是远离目标中的为位置会产生大量低质量的预测框,就是离目标中心越远,预测框的效果反而更差。因此,作者想要在不引入超参的情况下,抑制这些低质量的检测框,其做法就是引入了一条分支Center-ness。这条Center-ness分支输出一个$H imes W imes 1$的tensor,表示该点到目标中心点的“距离权重”,如下图所示,“距离权重”的值在$[0,1]$之间。在测试的时候,最终输出的分数应该是Center-ness与分类置信度的得分进行相乘。所以,Center-ness能起到降低远离目标中心的得分权重的作用。而Center-ness的另一种替代形式是只使用真实框中心的附近点作为正样本,人为引入一个超参来抑制远距离的特征点的影响。作者发现,将这两种方式进行结合起来使用,能取得更佳的效果。
$$centerness^*=sqrt{frac{min(l^*,r^*)}{max(l^*,r^*)} imes frac{min(t^*,b^*)}{max(t^*,b^*)}}$$

最终损失函数的组成应该有3部分,分别是置信度损失、回归损失和centerness损失(二值交叉熵损失)。其中,$lambda $和$alpha $分别平衡两者的权重。可以看出,损失函数中都是只是用正样本参与计算。在源码中计算损失函数时,centerness层的值除了计算二值交叉熵损失外,还会与回归损失进行结合,降低远离中心点的特征点的回归损失。而在测试时,centerness层的值直接与置信度相乘,使用相乘后的置信度来进行后处理。
$$Loss=frac{1}{N_{pos}}sum_{x,y}L_{cls}(p_{x,y},c^*_{x,y})+frac{lambda }{N_{pos}}sum_{x,y}mathbb{I}_{c^*_{x,y}}L_{reg}(t_{x,y},t^*_{x,y})+alpha L_{center-ness}(d,d^*)$$
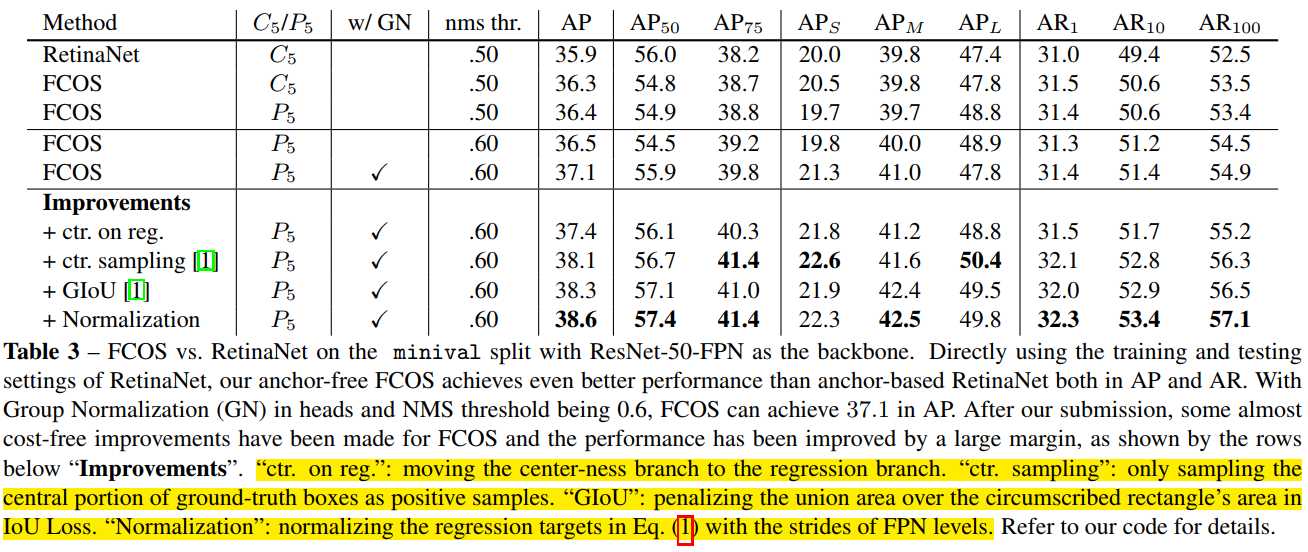
下图是FCOS算法的性能,可以看出,在不采取改进措施的前提下,FCOS已经能和RetinaNet媲美了。在使用了(a)center-ness层放在回归头处、(b)只在目标框的中心附近采样、(c)使用GIOU作为回归损失函数、(d)标准化目标回归函数,等改进措施后,性能更是进一步提高。
参考资料:
以上我是在觉得在one stage目标检测中比较经典的算法,为此特意准备回顾了一下。欢迎批评指教。
以上是关于One Stage目标检测的主要内容,如果未能解决你的问题,请参考以下文章
为什么二阶段(two-stage)目标检测算法比一阶段(one-stage)目标检测算法精度高