运维常说的 5个94个93个9 的可靠性,到底是什么鬼?
Posted 05-hust
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了运维常说的 5个94个93个9 的可靠性,到底是什么鬼?相关的知识,希望对你有一定的参考价值。
·
运维常说的 5个9、4个9、3个9 的可靠性,到底是什么鬼?
在系统的高可靠性(也称为可用性,英文描述为HA,High Available)里有个衡量其可靠性的标准——X个9,这个X是代表数字3~5。X个9表示在系统1年时间的使用过程中,系统可以正常使用时间与总时间(1年)之比,我们通过下面的计算来感受下X个9在不同级别的可靠性差异。
-
3个9:(1-99.9%)*365*24=8.76小时,表示该系统在连续运行1年时间里最多可能的业务中断时间是8.76小时。
-
4个9:(1-99.99%)*365*24=0.876小时=52.6分钟,表示该系统在连续运行1年时间里最多可能的业务中断时间是52.6分钟。
-
5个9:(1-99.999%)*365*24*60=5.26分钟,表示该系统在连续运行1年时间里最多可能的业务中断时间是5.26分钟。
那么X个9里的X只代表数字3~5,为什么没有1~2,也没有大于6的呢?我们接着往下计算:
-
1个9:(1-90%)*365=36.5天
-
2个9:(1-99%)*365=3.65天
-
6个9:(1-99.9999%)*365*24*60*60=31秒
可以看到1个9和、2个9分别表示一年时间内业务可能中断的时间是36.5天、3.65天,这种级别的可靠性或许还不配使用“可靠性”这个词;而6个9则表示一年内业务中断时间最多是31秒,那么这个级别的可靠性并非实现不了,而是要做到从“5个9” 到“6个9”的可靠性提升的话,后者需要付出比前者几倍的成本。
|
可用度A |
9的个数 |
年停机时间(分钟) |
适用产品 |
备注 |
|
0.99 |
两个9 【不同的衡量标准,频率】 |
88天次/年--平均4.2天出现一次故障 【某天出现0.1秒问题也算当天有故障】 |
【目前80%以上的企业生产环境的 注:下方都是某一个方面,如仅仅是服务器不停机 |
|
|
0.999 |
三个9 |
500 |
电脑或服务器 |
测试环境,非常不稳定 |
|
0.9999 |
四个9 |
50 |
企业级设备 |
生产环境最低要求 Standard |
|
0.99999 |
五个9 |
5 |
一般电信级设备 |
大型商城级等应用 Good |
|
0.999999 |
六个9 |
0.5 |
更高要求电信级设备 |
金融级服务器 |



【1、MTBF】MTBF,即平均故障间隔时间,英文全称是“Mean Time Between Failure”。是衡量一个产品(尤其是电器产品)的可靠性指标。单位为“小时”。具体来说,是指相邻两次故障之间的平均工作时间,也称为平均故障间隔。概括地说,产品故障少的就是可靠性高,产品的故障总数与寿命单位总数之比叫“故障率”(Failure rate)。它仅适用于可维修产品。同时也规定产品在总的使用阶段累计工作时间与故障次数的比值为MTBF。磁盘阵列产品一般MTBF不能低于50000小时。
【2、失效率】失效率是指工作到某一时刻尚未失效的产品,在该时刻后,单位时间内发生失效的概率。一般记为λ,它也是时间t的函数,故也记为λ(t),称为失效率函数,有时也称为故障率函数或风险函数。
失效率λ=1/MTBF,单位1FITs=10-9(1/h)
【3、MTTR】MTTR,全称是Mean Time To Repair,即平均修复时间。是指可修复产品的平均修复时间,就是从出现故障到修复中间的这段时间。MTTR越短表示易恢复性越好。
MTTR也必须包含获得配件的时间,维修团队的响应时间,记录所有任务的时间,还有将设备重新投入使用的时间。是一个缩写的平均时间恢复或平均修复时间代表的平均时间将有缺陷的部件或系统恢复工作秩序。 它是衡量一个系统的可维护性和可预测的平均所需的时间让系统工作的情况下再次出现系统故障。 MTTR可以从几个毫秒,如不间断电源(UPS)的许多数小时甚至数天的情况下的应用软件或复杂的机制。
【4、修复率】修复率(μ) repair rate 产品维修性的一种基本参数。修理时间已达到某个时刻但尚未修复的产品,在该时刻后的单位时间内完成修理的概率。
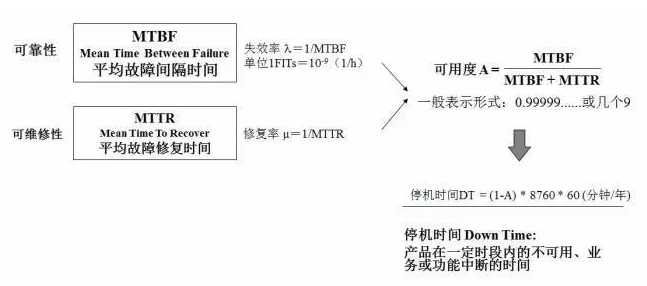
经常用到所谓4个9或者5个9,也就是99.99%与99.999%。那么,4个9或者5个9的差距有多大,差距是0.009%,还不到0.01%。但对于系统而言,恰恰是这不到0.01%的差距,决定了系统完全不在一个档次上。
所谓5个9的系统,一年内不能正常工作的时间少于5分15秒。对应4个9的系统是不超过52分36秒。这些都是理论上的数据,在实际工作中有些故障导致的宕机时间远超过5分钟,即使采用大型主机,也有宕机4个多小时的惨痛教训。问题出在哪里?
一个系统的可靠性并不完全取决于硬件,而由软件和硬件共同来决定,如果是软件问题,最好的解决办法就是打补丁、升级,再好的硬件也没有办法解决软件的问题。要提高系统的可靠性,软件是没有太好办法的,只有依靠厂商服务来解决问题。用户可以选择的只有硬件,其中,包括网络、服务器以及存储设备。其中,网络可以借助多运营商接入来解决,存储有RAID、快照等应对技术,通过备份来提高数据安全性。但对于服务器来说,更多用户的选择是采用双机集群的方法。
采用双机集群的方案是达不到5个9的要求的。原因很简单,双机集群是通过集群软件来构建方案的,当其中的一台服务器产生故障的时候,切换到备份主机继续工作,保持业务连续性。设备之间也可以依靠心跳线连接对故障进行判定。对于集群而言,故障切换是有严格要求的,要求主机、备用机的环境是一致的。在应用实践中,要求管理要到位,例如同步升级、升级,打补丁。如果管理不到位,很有可能会导致切换失败。这也是为什么,系统可以在演示环境下成功切换,但现实中往往做不到的原因。
·
以上是关于运维常说的 5个94个93个9 的可靠性,到底是什么鬼?的主要内容,如果未能解决你的问题,请参考以下文章