DRBD 安装配置工作原理及故障恢复
Posted cy-8593
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了DRBD 安装配置工作原理及故障恢复相关的知识,希望对你有一定的参考价值。
DRBD 安装配置、工作原理及故障恢复
一、DRBD 简介
DRBD的全称为:Distributed ReplicatedBlock Device(DRBD)分布式块设备复制,DRBD是由内核模块和相关脚本而构成,用以构建高可用性的集群。其实现方式是通过网络来镜像整个设备。你可以把它看作是一种网络RAID。它允许用户在远程机器上建立一个本地块设备的实时镜像。
1. DRBD是如何工作的呢?
(DRBD Primary)负责接收数据,把数据写到本地磁盘并发送给另一台主机(DRBD Secondary)。另一个主机再将数据存到自己的磁盘中。目前,DRBD每次只允许对一个节点进行读写访问,但这对于通常的故障切换高可用集群来说已经足够用了。有可能以后的版本支持两个节点进行读写存取。
2. DRBD与HA的关系
一个DRBD系统由两个节点构成,与HA集群类似,也有主节点和备用节点之分,在带有主要设备的节点上,应用程序和操作系统可以运行和访问DRBD设备(/dev/drbd*)。在主节点写入的数据通过DRBD设备存储到主节点的磁盘设备中,同时,这个数据也会自动发送到备用节点对应的DRBD设备,最终写入备用节点的磁盘设备上,在备用节点上,DRBD只是将数据从DRBD设备写入到备用节点的磁盘中。现在大部分的高可用性集群都会使用共享存储,而DRBD也可以作为一个共享存储设备,使用DRBD不需要太多的硬件的投资。因为它在TCP/IP网络中运行,所以,利用DRBD作为共享存储设备,要节约很多成本,因为价格要比专用的存储网络便宜很多;其性能与稳定性方面也不错
3. DRBD复制模式
3.1 协议A:异步复制协议
异步复制协议。一旦本地磁盘写入已经完成,数据包已在发送队列中,则写被认为是完成的。在一个节点发生故障时,可能发生数据丢失,因为被写入到远程节点上的数据可能仍在发送队列。尽管,在故障转移节点上的数据是一致的,但没有及时更新。这通常是用于地理上分开的节点
3.2 协议B:内存同步(半同步)复制协议
内存同步(半同步)复制协议。一旦本地磁盘写入已完成且复制数据包达到了对等节点则认为写在主节点上被认为是完成的。数据丢失可能发生在参加的两个节点同时故障的情况下,因为在传输中的数据可能不会被提交到磁盘
3.3 协议C:同步复制协议
同步复制协议。只有在本地和远程节点的磁盘已经确认了写操作完成,写才被认为完成。没有任何数据丢失,所以这是一个群集节点的流行模式,但I / O吞吐量依赖于网络带宽
一般使用协议C,但选择C协议将影响流量,从而影响网络时延。为了数据可靠性,我们在生产环境使用时须慎重选项使用哪一种协议
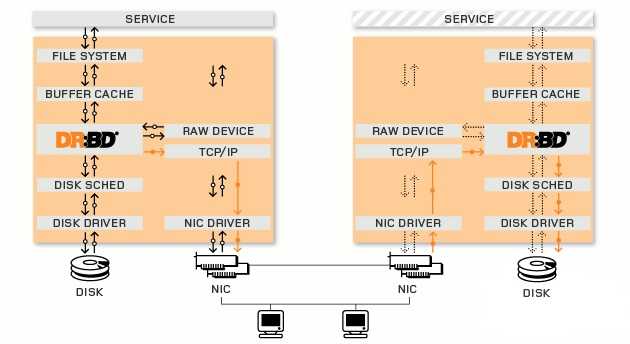
4. DRBD工作原理图
DRBD是linux的内核的存储层中的一个分布式存储系统,可用使用DRBD在两台Linux服务器之间共享块设备,共享文件系统和数据。类似于一个网络RAID-1的功能,如图所示:
二、环境介绍及安装前准备
1. 环境介绍:
系统版本:CentOS 6.4_x86_64
DRBD软件:drbd-8.4.3-33.el6.x86_64 drbd-kmdl-2.6.32-358.el6-8.4.3-33.el6.x86_64 下载地址:http://rpmfind.net
注意:这里两个软件的版本必须使用一致,而drbd-kmdl的版本要与当前系统的版本相对应,当然在实际应用中需要根据自己的系统平台下载符合需要的软件版本;
查看系统版本 uname -r
2. 安装前准备:
2.1 每个节点的主机名称须跟uname -n命令的执行结果一样
2.1.1 NOD1节点执行
sed -i ‘s@(HOSTNAME=).*@1nod1.allen.com@g‘ /etc/sysconfig/network
hostname nod1.allen.com
2.1.2 NOD2节点执行
sed -i ‘s@(HOSTNAME=).*@1nod2.allen.com@g‘ /etc/sysconfig/network
hostname nod2.allen.com
注释:修改文件须重启系统生效,这里先修改文件然后执行命令修改主机名称可以不用重启
2.2 两个节点的主机名称和对应的IP地址可以正常解析(在NOD1与NOD2节点执行)
cat > /etc/hosts << EOF
192.168.137.225 nod1.allen.com nod1
192.168.137.222 nod2.allen.com nod2
EOF2.3 配置epel的yum源
在NOD1与NOD2节点安装;获取路径自行网络搜索。
rpm -ivh epel-release-6-8.noarch.rpm
2.4 创建分区
需要为两个节点分别提供大小相同的分区
2.4.1 在NOD1节点上创建分区,分区大小必须与NOD2节点保持一样
[root@nod1 ~]# fdisk /dev/sda
Command (m for help): n
Command action
e extended
p primary partition (1-4)
p
Partition number (1-4): 3
First cylinder (7859-15665, default 7859):
Using default value 7859
Last cylinder, +cylinders or +size{K,M,G} (7859-15665, default 15665): +2G
Command (m for help): w
[root@nod1 ~]# partx /dev/sda #让内核重新读取分区
######查看内核有没有识别分区,如果没有需要重新启动,这里没有识别需要重启系统
[root@nod1 ~]# cat /proc/partitions
major minor #blocks name
8 0 125829120 sda
8 1 204800 sda1
8 2 62914560 sda2
253 0 20971520 dm-0
253 1 2097152 dm-1
253 2 10485760 dm-2
253 3 20971520 dm-3
[root@nod1 ~]# reboot2.4.2 在NOD2节点上创建分区,分区大小必须与NOD1节点保持一样
[root@nod2 ~]# fdisk /dev/sda
Command (m for help): n
Command action
e extended
p primary partition (1-4)
p
Partition number (1-4): 3
First cylinder (7859-15665, default 7859):
Using default value 7859
Last cylinder, +cylinders or +size{K,M,G} (7859-15665, default 15665): +2G
Command (m for help): w
[root@nod2 ~]# partx /dev/sda #让内核重新读取分区
######查看内核有没有识别分区,如果没有需要重新启动,这里没有识别需要重启系统
[root@nod2 ~]# cat /proc/partitions
major minor #blocks name
8 0 125829120 sda
8 1 204800 sda1
8 2 62914560 sda2
253 0 20971520 dm-0
253 1 2097152 dm-1
253 2 10485760 dm-2
253 3 20971520 dm-3
[root@nod2 ~]# reboot三、安装并配置DRBD
1. 安装DRBD软件包
需在NOD1与NOD2节点上安装DRBD软件包
######NOD1
[root@nod1 ~]# ls drbd-*
drbd-8.4.3-33.el6.x86_64.rpm drbd-kmdl-2.6.32-358.el6-8.4.3-33.el6.x86_64.rpm
[root@nod1 ~]# yum -y install drbd-*.rpm
######NOD2
[root@nod2 ~]# ls drbd-*
drbd-8.4.3-33.el6.x86_64.rpm drbd-kmdl-2.6.32-358.el6-8.4.3-33.el6.x86_64.rpm
[root@nod2 ~]# yum -y install drbd-*.rpm2. 查看DRBD配置文件
ll /etc/drbd.conf;ll /etc/drbd.d/
-rw-r--r-- 1 root root 133 May 14 21:12 /etc/drbd.conf #主配置文件
total 4
-rw-r--r-- 1 root root 1836 May 14 21:12 global_common.conf #全局配置文件
######查看主配置文件内容
cat /etc/drbd.conf
######主配置文件中包含了全局配置文件及"drbd.d/"目录下以.res结尾的文件
# You can find an example in /usr/share/doc/drbd.../drbd.conf.example
include "drbd.d/global_common.conf";
include "drbd.d/*.res";3. 修改配置文件如下
[root@nod1 ~]#vim /etc/drbd.d/global_common.conf
global {
usage-count no; #是否参加DRBD使用统计,默认为yes
# minor-count dialog-refresh disable-ip-verification
}
common {
protocol C; #使用DRBD的同步协议
handlers {
# These are EXAMPLE handlers only.
# They may have severe implications,
# like hard resetting the node under certain circumstances.
# Be careful when chosing your poison.
pri-on-incon-degr "/usr/lib/drbd/notify-pri-on-incon-degr.sh; /usr/lib/drbd/notify-emergency-reboot.sh; echo b > /proc/sysrq-trigger ; reboot -f";
pri-lost-after-sb "/usr/lib/drbd/notify-pri-lost-after-sb.sh; /usr/lib/drbd/notify-emergency-reboot.sh; echo b > /proc/sysrq-trigger ; reboot -f";
local-io-error "/usr/lib/drbd/notify-io-error.sh; /usr/lib/drbd/notify-emergency-shutdown.sh; echo o > /proc/sysrq-trigger ; halt -f";
# fence-peer "/usr/lib/drbd/crm-fence-peer.sh";
# split-brain "/usr/lib/drbd/notify-split-brain.sh root";
# out-of-sync "/usr/lib/drbd/notify-out-of-sync.sh root";
# before-resync-target "/usr/lib/drbd/snapshot-resync-target-lvm.sh -p 15 -- -c 16k";
# after-resync-target /usr/lib/drbd/unsnapshot-resync-target-lvm.sh;
}
startup {
# wfc-timeout degr-wfc-timeout outdated-wfc-timeout wait-after-sb
}
options {
# cpu-mask on-no-data-accessible
}
disk {
on-io-error detach; #配置I/O错误处理策略为分离
# size max-bio-bvecs on-io-error fencing disk-barrier disk-flushes
# disk-drain md-flushes resync-rate resync-after al-extents
# c-plan-ahead c-delay-target c-fill-target c-max-rate
# c-min-rate disk-timeout
}
net {
cram-hmac-alg "sha1"; #设置加密算法
shared-secret "allendrbd"; #设置加密密钥
# protocol timeout max-epoch-size max-buffers unplug-watermark
# connect-int ping-int sndbuf-size rcvbuf-size ko-count
# allow-two-primaries cram-hmac-alg shared-secret after-sb-0pri
# after-sb-1pri after-sb-2pri always-asbp rr-conflict
# ping-timeout data-integrity-alg tcp-cork on-congestion
# congestion-fill congestion-extents csums-alg verify-alg
# use-rle
}
syncer {
rate 1024M; #设置主备节点同步时的网络速率
}
}注释:on-io-error <strategy>策略可能为以下选项之一
detach 分离:这是默认和推荐的选项,如果在节点上发生底层的硬盘I/O错误,它会将设备运行在Diskless无盘模式下
pass_on:DRBD会将I/O错误报告到上层,在主节点上,它会将其报告给挂载的文件系统,但是在此节点上就往往忽略(因此此节点上没有可以报告的上层)
-local-in-error:调用本地磁盘I/O处理程序定义的命令;这需要有相应的local-io-error调用的资源处理程序处理错误的命令;这就给管理员有足够自由的权力命令命令或是脚本调用local-io-error处理I/O错误
4. 添加资源文件
[root@nod1 ~]# vim /etc/drbd.d/drbd.res
resource drbd {
on nod1.allen.com { #第个主机说明以on开头,后面是主机名称
device /dev/drbd0;#DRBD设备名称
disk /dev/sda3; #drbd0使用的磁盘分区为"sda3"
address 192.168.137.225:7789; #设置DRBD监听地址与端口
meta-disk internal;
}
on nod2.allen.com {
device /dev/drbd0;
disk /dev/sda3;
address 192.168.137.222:7789;
meta-disk internal;
}
}5. 将配置文件为NOD2提供一份
[root@nod1 ~]# scp /etc/drbd.d/{global_common.conf,drbd.res} nod2:/etc/drbd.d/
The authenticity of host 'nod2 (192.168.137.222)' can't be established.
RSA key fingerprint is 29:d3:28:85:20:a1:1f:2a:11:e5:88:cd:25:d0:95:c7.
Are you sure you want to continue connecting (yes/no)? yes
Warning: Permanently added 'nod2' (RSA) to the list of known hosts.
root@nod2's password:
global_common.conf 100% 1943 1.9KB/s 00:00
drbd.res 100% 318 0.3KB/s 00:006. 初始化资源并启动服务
######在NOD1节点上初始化资源并启动服务
[root@nod1 ~]# drbdadm create-md drbd
Writing meta data...
initializing activity log
NOT initializing bitmap
lk_bdev_save(/var/lib/drbd/drbd-minor-0.lkbd) failed: No such file or directory
New drbd meta data block successfully created. #提示已经创建成功
lk_bdev_save(/var/lib/drbd/drbd-minor-0.lkbd) failed: No such file or directory
######启动服务
[root@nod1 ~]# service drbd start
Starting DRBD resources: [
create res: drbd
prepare disk: drbd
adjust disk: drbd
adjust net: drbd
]
..........
***************************************************************
DRBD's startup script waits for the peer node(s) to appear.
- In case this node was already a degraded cluster before the
reboot the timeout is 0 seconds. [degr-wfc-timeout]
- If the peer was available before the reboot the timeout will
expire after 0 seconds. [wfc-timeout]
(These values are for resource 'drbd'; 0 sec -> wait forever)
To abort waiting enter 'yes' [ 12]: yes
######查看监听端口
[root@nod1 ~]# ss -tanl |grep 7789
LISTEN 0 5 192.168.137.225:7789 *:*
######在NOD2节点上初始化资源并启动服务
[root@nod2 ~]# drbdadm create-md drbd
Writing meta data...
initializing activity log
NOT initializing bitmap
lk_bdev_save(/var/lib/drbd/drbd-minor-0.lkbd) failed: No such file or directory
New drbd meta data block successfully created.
lk_bdev_save(/var/lib/drbd/drbd-minor-0.lkbd) failed: No such file or directory
######启动服务
[root@nod2 ~]# service drbd start
Starting DRBD resources: [
create res: drbd
prepare disk: drbd
adjust disk: drbd
adjust net: drbd
]
######查看监听地址与端口
[root@nod2 ~]# netstat -anput|grep 7789
tcp 0 0 192.168.137.222:42345 192.168.137.225:7789 ESTABLISHED -
tcp 0 0 192.168.137.222:7789 192.168.137.225:42325 ESTABLISHED -
######查看DRBD启动状态
[root@nod2 ~]# drbd-overview
0:drbd/0 Connected Secondary/Secondary Inconsistent/Inconsistent C r-----7. 资源的连接状态详细介绍
7.1 查看资源连接状态
[root@nod1 ~]# drbdadm cstate drbd #drbd为资源名称
Connected7.2 资源的连接状态
一个资源可能有以下连接状态中的一种
- StandAlone 独立的:网络配置不可用;资源还没有被连接或是被管理断开(使用 drbdadm disconnect 命令),或是由于出现认证失败或是脑裂的情况
- Disconnecting 断开:断开只是临时状态,下一个状态是StandAlone独立的
- Unconnected 悬空:是尝试连接前的临时状态,可能下一个状态为WFconnection和WFReportParams
- Timeout 超时:与对等节点连接超时,也是临时状态,下一个状态为Unconected悬空
- BrokerPipe:与对等节点连接丢失,也是临时状态,下一个状态为Unconected悬空
- NetworkFailure:与对等节点推动连接后的临时状态,下一个状态为Unconected悬空
- ProtocolError:与对等节点推动连接后的临时状态,下一个状态为Unconected悬空
- TearDown 拆解:临时状态,对等节点关闭,下一个状态为Unconected悬空
- WFConnection:等待和对等节点建立网络连接
- WFReportParams:已经建立TCP连接,本节点等待从对等节点传来的第一个网络包
- Connected 连接:DRBD已经建立连接,数据镜像现在可用,节点处于正常状态
- StartingSyncS:完全同步,有管理员发起的刚刚开始同步,未来可能的状态为SyncSource或PausedSyncS
- StartingSyncT:完全同步,有管理员发起的刚刚开始同步,下一状态为WFSyncUUID
- WFBitMapS:部分同步刚刚开始,下一步可能的状态为SyncSource或PausedSyncS
- WFBitMapT:部分同步刚刚开始,下一步可能的状态为WFSyncUUID
- WFSyncUUID:同步即将开始,下一步可能的状态为SyncTarget或PausedSyncT
- SyncSource:以本节点为同步源的同步正在进行
- SyncTarget:以本节点为同步目标的同步正在进行
- PausedSyncS:以本地节点是一个持续同步的源,但是目前同步已经暂停,可能是因为另外一个同步正在进行或是使用命令(drbdadm pause-sync)暂停了同步
- PausedSyncT:以本地节点为持续同步的目标,但是目前同步已经暂停,这可以是因为另外一个同步正在进行或是使用命令(drbdadm pause-sync)暂停了同步
- VerifyS:以本地节点为验证源的线上设备验证正在执行
- VerifyT:以本地节点为验证目标的线上设备验证正在执行
7.3 资源角色
查看资源角色命令
[root@nod1 ~]# drbdadm role drbd
Secondary/Secondary
[root@nod1 ~]# cat /proc/drbd
version: 8.4.3 (api:1/proto:86-101)
GIT-hash: 89a294209144b68adb3ee85a73221f964d3ee515 build by gardner@, 2013-05-27 04:30:21
0: cs:Connected ro:Secondary/Secondary ds:Inconsistent/Inconsistent C r-----
ns:0 nr:0 dw:0 dr:0 al:0 bm:0 lo:0 pe:0 ua:0 ap:0 ep:1 wo:f oos:2103412注释:
Parimary 主:资源目前为主,并且可能正在被读取或写入,如果不是双主只会出现在两个节点中的其中一个节点上
Secondary 次:资源目前为次,正常接收对等节点的更新
Unknown 未知:资源角色目前未知,本地的资源不会出现这种状态
7.4 硬盘状态
查看硬盘状态命令
[root@nod1 ~]# drbdadm dstate drbd
Inconsistent/Inconsistent本地和对等节点的硬盘有可能为下列状态之一:
- Diskless 无盘:本地没有块设备分配给DRBD使用,这表示没有可用的设备,或者使用drbdadm命令手工分离或是底层的I/O错误导致自动分离
- Attaching:读取无数据时候的瞬间状态
- Failed 失败:本地块设备报告I/O错误的下一个状态,其下一个状态为Diskless无盘
- Negotiating:在已经连接的DRBD设置进行Attach读取无数据前的瞬间状态
- Inconsistent:数据是不一致的,在两个节点上(初始的完全同步前)这种状态出现后立即创建一个新的资源。此外,在同步期间(同步目标)在一个节点上出现这种状态
- Outdated:数据资源是一致的,但是已经过时
- DUnknown:当对等节点网络连接不可用时出现这种状态
- Consistent:一个没有连接的节点数据一致,当建立连接时,它决定数据是UpToDate或是Outdated
- UpToDate:一致的最新的数据状态,这个状态为正常状态
7.5 启用和禁用资源
######手动启用资源
drbdadm up <resource>
######手动禁用资源
drbdadm down <resource>注释:
resource:为资源名称;当然也可以使用all表示[停用|启用]所有资源
7.6 升级和降级资源
######升级资源
drbdadm primary <resource>
######降级资源
drbdadm secondary <resource>注释:在单主模式下的DRBD,两个节点同时处于连接状态,任何一个节点都可以在特定的时间内变成主;但两个节点中只能一为主,如果已经有一个主,需先降级才可能升级;在双主模式下没有这个限制
8. 初始化设备同步
选择一个初始同步源;如果是新初始化的或是空盘,这个选择可以是任意的,但是如果其中的一个节点已经在使用并包含有用的数据,那么选择同步源是至关重要的;如果选错了初始化同步方向,就会造成数据丢失,因此需要十分小心
启动初始化完全同步,这一步只能在初始化资源配置的一个节点上进行,并作为同步源选择的节点上;命令如下:
[root@nod1 ~]# drbdadm -- --overwrite-data-of-peer primary drbd
[root@nod1 ~]# cat /proc/drbd #查看同步进度
version: 8.4.3 (api:1/proto:86-101)
GIT-hash: 89a294209144b68adb3ee85a73221f964d3ee515 build by gardner@, 2013-05-27 04:30:21
0: cs:SyncSource ro:Primary/Secondary ds:UpToDate/Inconsistent C r---n-
ns:1897624 nr:0 dw:0 dr:1901216 al:0 bm:115 lo:0 pe:3 ua:3 ap:0 ep:1 wo:f oos:207988
[=================>..] sync'ed: 90.3% (207988/2103412)K
finish: 0:00:07 speed: 26,792 (27,076) K/sec
######当同步完成时如以下状态
version: 8.4.3 (api:1/proto:86-101)
GIT-hash: 89a294209144b68adb3ee85a73221f964d3ee515 build by gardner@, 2013-05-27 04:30:21
0: cs:Connected ro:Primary/Secondary ds:UpToDate/UpToDate C r-----
ns:2103412 nr:0 dw:0 dr:2104084 al:0 bm:129 lo:0 pe:0 ua:0 ap:0 ep:1 wo:f oos:0
注释: drbd:为资源名称
######查看同步进度也可使用以下命令
drbd-overview9. 创建文件系统
9.1、文件系统只能挂载在主(Primary)节点上,因此在设置好主节点后才可以对DRBD设备进行格式化操作
######格式化文件系统
[root@nod1 ~]# mkfs.ext4 /dev/drbd0
######挂载文件系统
[root@nod1 ~]# mount /dev/drbd0 /mnt/
######查看挂载
[root@nod1 ~]# mount |grep drbd0
/dev/drbd0 on /mnt type ext4 (rw)
注释:
"/dev/drbd0"为资源中定义已定义的资源名称
######查看DRBD状态
[root@nod1 ~]# drbd-overview
0:drbd/0 Connected Primary/Secondary UpToDate/UpToDate C r-----注释:
Primary:当前节点为主;在前面为当前节点
Secondary:备用节点为次
9.2、在挂载目录中创建一个测试文件并卸载;然后
[root@nod1 ~]# mkdir /mnt/test
[root@nod1 ~]# ls /mnt/
lost+found test
######在切换主节点时必须保证资源不在使用
[root@nod1 ~]# umount /mnt/9.3、切换主备节点
######先把当前主节点降级为次
[root@nod1 ~]# drbdadm secondary drbd
######查看DRBD状态
[root@nod1 ~]# drbd-overview
0:drbd/0 Connected Secondary/Secondary UpToDate/UpToDate C r-----
######在NOD2节点升级
[root@nod2 ~]# drbdadm primary drbd
######查看DRBD状态
[root@nod2 ~]# drbd-overview
0:drbd/0 Connected Primary/Secondary UpToDate/UpToDate C r-----9.4、挂载设备并验证文件是否存在
[root@nod2 ~]# mount /dev/drbd0 /mnt/
[root@nod2 ~]# ls /mnt/
lost+found test四、DRBD脑裂的模拟及修复
注释:我们还接着上面的实验继续进行,现在NOD2为主节点而NOD1为备节点
1. 断开主(parmary)节点
关机、断开网络或重新配置其他的IP都可以;这里选择的是断开网络
2. 查看两节点状态
[root@nod2 ~]# drbd-overview
0:drbd/0 WFConnection Primary/Unknown UpToDate/DUnknown C r----- /mnt ext4 2.0G 68M 1.9G 4%
[root@nod1 ~]# drbd-overview
0:drbd/0 StandAlone Secondary/Unknown UpToDate/DUnknown r-----
######由上可以看到两个节点已经无法通信;NOD2为主节点,NOD1为备节点3. 将NOD1节点升级为主(primary)节点并挂载资源
[root@nod1 ~]# drbdadm primary drbd
[root@nod1 ~]# drbd-overview
0:drbd/0 StandAlone Primary/Unknown UpToDate/DUnknown r-----
[root@nod1 ~]# mount /dev/drbd0 /mnt/
[root@nod1 ~]# mount | grep drbd0
/dev/drbd0 on /mnt type ext4 (rw)4. 恢复主(primary)节点
假如原来的主(primary)节点修复好重新上线了,这时出现了脑裂情况
[root@nod2 ~]# tail -f /var/log/messages
Sep 19 01:56:06 nod2 kernel: d-con drbd: Terminating drbd_a_drbd
Sep 19 01:56:06 nod2 kernel: block drbd0: helper command: /sbin/drbdadm initial-split-brain minor-0 exit code 0 (0x0)
Sep 19 01:56:06 nod2 kernel: block drbd0: Split-Brain detected but unresolved, dropping connection!
Sep 19 01:56:06 nod2 kernel: block drbd0: helper command: /sbin/drbdadm split-brain minor-0
Sep 19 01:56:06 nod2 kernel: block drbd0: helper command: /sbin/drbdadm split-brain minor-0 exit code 0 (0x0)
Sep 19 01:56:06 nod2 kernel: d-con drbd: conn( NetworkFailure -> Disconnecting )
Sep 19 01:56:06 nod2 kernel: d-con drbd: error receiving ReportState, e: -5 l: 0!
Sep 19 01:56:06 nod2 kernel: d-con drbd: Connection closed
Sep 19 01:56:06 nod2 kernel: d-con drbd: conn( Disconnecting -> StandAlone )
Sep 19 01:56:06 nod2 kernel: d-con drbd: receiver terminated
Sep 19 01:56:06 nod2 kernel: d-con drbd: Terminating drbd_r_drbd
Sep 19 01:56:18 nod2 kernel: block drbd0: role( Primary -> Secondary )5. 再次查看两节点的状态
[root@nod1 ~]# drbdadm role drbd
Primary/Unknown
[root@nod2 ~]# drbdadm role drbd
Primary/Unknown6. 查看NOD1与NOD2连接状态
[root@nod1 ~]# drbd-overview
0:drbd/0 StandAlone Primary/Unknown UpToDate/DUnknown r----- /mnt ext4 2.0G 68M 1.9G 4%
[root@nod2 ~]# drbd-overview
0:drbd/0 WFConnection Primary/Unknown UpToDate/DUnknown C r----- /mnt ext4 2.0G 68M 1.9G 4%
######由上可见,状态为StandAlone时,主备节点是不会通信的7. 查看DRBD的服务状态
[root@nod1 ~]# service drbd status
drbd driver loaded OK; device status:
version: 8.4.3 (api:1/proto:86-101)
GIT-hash: 89a294209144b68adb3ee85a73221f964d3ee515 build by gardner@, 2013-05-27 04:30:21
m:res cs ro ds p mounted fstype
0:drbd StandAlone Primary/Unknown UpToDate/DUnknown r----- ext4
[root@nod2 ~]# service drbd status
drbd driver loaded OK; device status:
version: 8.4.3 (api:1/proto:86-101)
GIT-hash: 89a294209144b68adb3ee85a73221f964d3ee515 build by gardner@, 2013-05-27 04:30:21
m:res cs ro ds p mounted fstype
0:drbd WFConnection Primary/Unknown UpToDate/DUnknown C /mnt ext48. 在NOD1备用节点处理办法
[root@nod1 ~]# umount /mnt/
[root@nod1 ~]# drbdadm disconnect drbd
drbd: Failure: (162) Invalid configuration request
additional info from kernel:
unknown connection
Command 'drbdsetup disconnect ipv4:192.168.137.225:7789 ipv4:192.168.137.222:7789' terminated with exit code 10
[root@nod1 ~]# drbdadm secondary drbd
[root@nod1 ~]# drbd-overview
0:drbd/0 StandAlone Secondary/Unknown UpToDate/DUnknown r-----
[root@nod1 ~]# drbdadm connect --discard-my-data drbd
######执行完以上三步后,你查看会发现还是不可用
[root@nod1 ~]# drbd-overview
0:drbd/0 WFConnection Secondary/Unknown UpToDate/DUnknown C r-----9. 需要在NOD2节点上重新建立连接资源
[root@nod2 ~]# drbdadm connect drbd
######查看节点连接状态
[root@nod2 ~]# drbd-overview
0:drbd/0 Connected Primary/Secondary UpToDate/UpToDate C r----- /mnt ext4 2.0G 68M 1.9G 4%
[root@nod1 ~]# drbd-overview
0:drbd/0 Connected Secondary/Primary UpToDate/UpToDate C r-----
######由上可见已经恢复到正常运行状态注意:特别提醒,如果是单主模式,资源只能在主(Primary)节点上挂载使用,而且不建议手动切换主备节点
到此DRBD的安装配置及故障修复已结束,DRBD的双主模式一般情况不会用到,这里也不再介绍双主模式的配置;这篇博客写于中秋节当天,在这里祝大家中秋节愉快!!!
以上是关于DRBD 安装配置工作原理及故障恢复的主要内容,如果未能解决你的问题,请参考以下文章