数据包发送
Posted mysky007
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了数据包发送相关的知识,希望对你有一定的参考价值。
解析 socket 函数
SYSCALL_DEFINE3(socket, int, family, int, type, int, protocol) { int retval; struct socket *sock; int flags; ...... if (SOCK_NONBLOCK != O_NONBLOCK && (flags & SOCK_NONBLOCK)) flags = (flags & ~SOCK_NONBLOCK) | O_NONBLOCK; retval = sock_create(family, type, protocol, &sock); ...... retval = sock_map_fd(sock, flags & (O_CLOEXEC | O_NONBLOCK)); ...... return retval; }
int __sock_create(struct net *net, int family, int type, int protocol, struct socket **res, int kern) { int err; struct socket *sock; const struct net_proto_family *pf; ...... sock = sock_alloc(); ...... sock->type = type; ...... pf = rcu_dereference(net_families[family]); ...... err = pf->create(net, sock, protocol, kern); ...... *res = sock; return 0; }
这里先是分配了一个 struct socket 结构。接下来我们要用到 family 参数。这里有一个 net_families 数组,我们可以以 family 参数为下标,找到对应的 struct net_proto_family。
/* Supported address families. */ #define AF_UNSPEC 0 #define AF_UNIX 1 /* Unix domain sockets */ #define AF_LOCAL 1 /* POSIX name for AF_UNIX */ #define AF_INET 2 /* Internet IP Protocol */ ...... #define AF_INET6 10 /* IP version 6 */ ...... #define AF_MPLS 28 /* MPLS */ ...... #define AF_MAX 44 /* For now.. */ #define NPROTO AF_MAX struct net_proto_family __rcu *net_families[NPROTO] __read_mostly;
//net/ipv4/af_inet.c static const struct net_proto_family inet_family_ops = { .family = PF_INET, .create = inet_create,//这个用于socket系统调用创建 ...... }
static int inet_create(struct net *net, struct socket *sock, int protocol, int kern) { struct sock *sk; struct inet_protosw *answer; struct inet_sock *inet; struct proto *answer_prot; unsigned char answer_flags; int try_loading_module = 0; int err; /* Look for the requested type/protocol pair. */ lookup_protocol: list_for_each_entry_rcu(answer, &inetsw[sock->type], list) { err = 0; /* Check the non-wild match. */ if (protocol == answer->protocol) { if (protocol != IPPROTO_IP) break; } else { /* Check for the two wild cases. */ if (IPPROTO_IP == protocol) { protocol = answer->protocol; break; } if (IPPROTO_IP == answer->protocol) break; } err = -EPROTONOSUPPORT; } ...... sock->ops = answer->ops; answer_prot = answer->prot; answer_flags = answer->flags; ...... sk = sk_alloc(net, PF_INET, GFP_KERNEL, answer_prot, kern); ...... inet = inet_sk(sk); inet->nodefrag = 0; if (SOCK_RAW == sock->type) { inet->inet_num = protocol; if (IPPROTO_RAW == protocol) inet->hdrincl = 1; } inet->inet_id = 0; sock_init_data(sock, sk); sk->sk_destruct = inet_sock_destruct; sk->sk_protocol = protocol; sk->sk_backlog_rcv = sk->sk_prot->backlog_rcv; inet->uc_ttl = -1; inet->mc_loop = 1; inet->mc_ttl = 1; inet->mc_all = 1; inet->mc_index = 0; inet->mc_list = NULL; inet->rcv_tos = 0; if (inet->inet_num) { inet->inet_sport = htons(inet->inet_num); /* Add to protocol hash chains. */ err = sk->sk_prot->hash(sk); } if (sk->sk_prot->init) { err = sk->sk_prot->init(sk); } ...... }
在 inet_create 中,我们先会看到一个循环 list_for_each_entry_rcu。在这里,第二个参数 type 开始起作用。因为循环查看的是 inetsw[sock->type]
static struct inet_protosw inetsw_array[] = { { .type = SOCK_STREAM, .protocol = IPPROTO_TCP, .prot = &tcp_prot, .ops = &inet_stream_ops, .flags = INET_PROTOSW_PERMANENT | INET_PROTOSW_ICSK, }, { .type = SOCK_DGRAM, .protocol = IPPROTO_UDP, .prot = &udp_prot, .ops = &inet_dgram_ops, .flags = INET_PROTOSW_PERMANENT, }, { .type = SOCK_DGRAM, .protocol = IPPROTO_ICMP, .prot = &ping_prot, .ops = &inet_sockraw_ops, .flags = INET_PROTOSW_REUSE, }, { .type = SOCK_RAW, .protocol = IPPROTO_IP, /* wild card */ .prot = &raw_prot, .ops = &inet_sockraw_ops, .flags = INET_PROTOSW_REUSE, } }
socket 是用于负责对上给用户提供接口,并且和文件系统关联。而 sock,负责向下对接内核网络协议栈
在 sk_alloc 函数中,struct inet_protosw *answer 结构的 tcp_prot 赋值给了 struct sock *sk 的 sk_prot 成员。
tcp_prot 的定义如下,里面定义了很多的函数,都是 sock 之下内核协议栈的动作
struct proto tcp_prot = { .name = "TCP", .owner = THIS_MODULE, .close = tcp_close, .connect = tcp_v4_connect, .disconnect = tcp_disconnect, .accept = inet_csk_accept, .ioctl = tcp_ioctl, .init = tcp_v4_init_sock, .destroy = tcp_v4_destroy_sock, .shutdown = tcp_shutdown, .setsockopt = tcp_setsockopt, .getsockopt = tcp_getsockopt, .keepalive = tcp_set_keepalive, .recvmsg = tcp_recvmsg, .sendmsg = tcp_sendmsg, .sendpage = tcp_sendpage, .backlog_rcv = tcp_v4_do_rcv, .release_cb = tcp_release_cb, .hash = inet_hash, .get_port = inet_csk_get_port, ...... }
bind 函数
SYSCALL_DEFINE3(bind, int, fd, struct sockaddr __user *, umyaddr, int, addrlen) { struct socket *sock; struct sockaddr_storage address; int err, fput_needed; sock = sockfd_lookup_light(fd, &err, &fput_needed); if (sock) { err = move_addr_to_kernel(umyaddr, addrlen, &address); if (err >= 0) { err = sock->ops->bind(sock, (struct sockaddr *) &address, addrlen); } fput_light(sock->file, fput_needed); } return err; }
1. sockfd_lookup_light 会根据 fd 文件描述符,找到 struct socket 结构。
2. 然后将 sockaddr 从用户态拷贝到内核态,然后调用 struct socket 结构里面 ops 的 bind 函数。
3. 根据前面创建 socket 的时候的设定,调用的是 inet_stream_ops 的 bind 函数,也即调用 inet_bind。
int inet_bind(struct socket *sock, struct sockaddr *uaddr, int addr_len) { struct sockaddr_in *addr = (struct sockaddr_in *)uaddr; struct sock *sk = sock->sk; struct inet_sock *inet = inet_sk(sk); struct net *net = sock_net(sk); unsigned short snum; ...... snum = ntohs(addr->sin_port); ...... inet->inet_rcv_saddr = inet->inet_saddr = addr->sin_addr.s_addr; /* Make sure we are allowed to bind here. */ if ((snum || !inet->bind_address_no_port) && sk->sk_prot->get_port(sk, snum)) { ...... } inet->inet_sport = htons(inet->inet_num); inet->inet_daddr = 0; inet->inet_dport = 0; sk_dst_reset(sk); }
bind 里面会调用 sk_prot 的 get_port 函数,也即 inet_csk_get_port 来检查端口是否冲突,是否可以绑定。
如果允许,则会设置 struct inet_sock 的本方的地址 inet_saddr 和本方的端口 inet_sport,对方的地址 inet_daddr 和对方的端口 inet_dport 都初始化为 0
listen 函数
SYSCALL_DEFINE2(listen, int, fd, int, backlog) { struct socket *sock; int err, fput_needed; int somaxconn; sock = sockfd_lookup_light(fd, &err, &fput_needed); if (sock) { somaxconn = sock_net(sock->sk)->core.sysctl_somaxconn; if ((unsigned int)backlog > somaxconn) backlog = somaxconn; err = sock->ops->listen(sock, backlog); fput_light(sock->file, fput_needed); } return err; }
1. 在 listen 中,我们还是通过 sockfd_lookup_light,根据 fd 文件描述符,找到 struct socket 结构。
2. 接着,我们调用 struct socket 结构里面 ops 的 listen 函数。
3. 根据前面创建 socket 的时候的设定,调用的是 inet_stream_ops 的 listen 函数,也即调用 inet_listen
int inet_listen(struct socket *sock, int backlog) { struct sock *sk = sock->sk; unsigned char old_state; int err; old_state = sk->sk_state; /* Really, if the socket is already in listen state * we can only allow the backlog to be adjusted. */ if (old_state != TCP_LISTEN) { err = inet_csk_listen_start(sk, backlog); } sk->sk_max_ack_backlog = backlog; }
如果这个 socket 还不在 TCP_LISTEN 状态,会调用 inet_csk_listen_start 进入监听状态。
int inet_csk_listen_start(struct sock *sk, int backlog) { struct inet_connection_sock *icsk = inet_csk(sk); struct inet_sock *inet = inet_sk(sk); int err = -EADDRINUSE; reqsk_queue_alloc(&icsk->icsk_accept_queue); sk->sk_max_ack_backlog = backlog; sk->sk_ack_backlog = 0; inet_csk_delack_init(sk); sk_state_store(sk, TCP_LISTEN); if (!sk->sk_prot->get_port(sk, inet->inet_num)) { ...... } ...... }
这里面建立了一个新的结构 inet_connection_sock,这个结构一开始是 struct inet_sock,inet_csk 其实做了一次强制类型转换,扩大了结构
struct inet_connection_sock 结构比较复杂各种状态的队列,各种超时时间、拥塞控制等字眼。我们说 TCP 是面向连接的,就是客户端和服务端都是有一个结构维护连接的状态,就是指这个结构。
accept 函数
SYSCALL_DEFINE3(accept, int, fd, struct sockaddr __user *, upeer_sockaddr, int __user *, upeer_addrlen) { return sys_accept4(fd, upeer_sockaddr, upeer_addrlen, 0); } SYSCALL_DEFINE4(accept4, int, fd, struct sockaddr __user *, upeer_sockaddr, int __user *, upeer_addrlen, int, flags) { struct socket *sock, *newsock; struct file *newfile; int err, len, newfd, fput_needed; struct sockaddr_storage address; ...... sock = sockfd_lookup_light(fd, &err, &fput_needed); newsock = sock_alloc(); newsock->type = sock->type; newsock->ops = sock->ops; newfd = get_unused_fd_flags(flags); newfile = sock_alloc_file(newsock, flags, sock->sk->sk_prot_creator->name); err = sock->ops->accept(sock, newsock, sock->file->f_flags, false); if (upeer_sockaddr) { if (newsock->ops->getname(newsock, (struct sockaddr *)&address, &len, 2) < 0) { } err = move_addr_to_user(&address, len, upeer_sockaddr, upeer_addrlen); } fd_install(newfd, newfile); ...... }
accept 函数的实现,印证了 socket 的原理中说的那样,原来的 socket 是监听 socket,这里我们会找到原来的 struct socket,并基于它去创建一个新的 newsock。这才是连接 socket。除此之外,我们还会创建一个新的 struct file 和 fd,并关联到 socket。
调用 struct socket 的 sock->ops->accept,也即会调用 inet_stream_ops 的 accept 函数,也即 inet_accept
int inet_accept(struct socket *sock, struct socket *newsock, int flags, bool kern) { struct sock *sk1 = sock->sk; int err = -EINVAL; struct sock *sk2 = sk1->sk_prot->accept(sk1, flags, &err, kern); sock_rps_record_flow(sk2); sock_graft(sk2, newsock); newsock->state = SS_CONNECTED; }
inet_accept 会调用 struct sock 的 sk1->sk_prot->accept,也即 tcp_prot 的 accept 函数,inet_csk_accept 函数
/* * This will accept the next outstanding connection. */ struct sock *inet_csk_accept(struct sock *sk, int flags, int *err, bool kern) { struct inet_connection_sock *icsk = inet_csk(sk); struct request_sock_queue *queue = &icsk->icsk_accept_queue; struct request_sock *req; struct sock *newsk; int error; if (sk->sk_state != TCP_LISTEN) goto out_err; /* Find already established connection */ if (reqsk_queue_empty(queue)) { long timeo = sock_rcvtimeo(sk, flags & O_NONBLOCK); error = inet_csk_wait_for_connect(sk, timeo); } req = reqsk_queue_remove(queue, sk); newsk = req->sk; ...... } /* * Wait for an incoming connection, avoid race conditions. This must be called * with the socket locked. */ static int inet_csk_wait_for_connect(struct sock *sk, long timeo) { struct inet_connection_sock *icsk = inet_csk(sk); DEFINE_WAIT(wait); int err; for (;;) { prepare_to_wait_exclusive(sk_sleep(sk), &wait, TASK_INTERRUPTIBLE); release_sock(sk); if (reqsk_queue_empty(&icsk->icsk_accept_queue)) timeo = schedule_timeout(timeo); sched_annotate_sleep(); lock_sock(sk); err = 0; if (!reqsk_queue_empty(&icsk->icsk_accept_queue)) break; err = -EINVAL; if (sk->sk_state != TCP_LISTEN) break; err = sock_intr_errno(timeo); if (signal_pending(current)) break; err = -EAGAIN; if (!timeo) break; } finish_wait(sk_sleep(sk), &wait); return err; }
net_csk_accept 的实现,印证了上面我们讲的两个队列的逻辑。如果 icsk_accept_queue 为空,则调用 inet_csk_wait_for_connect 进行等待;等待的时候,调用 schedule_timeout,让出 CPU,并且将进程状态设置为 TASK_INTERRUPTIBLE。
如果再次 CPU 醒来,我们会接着判断 icsk_accept_queue 是否为空,同时也会调用 signal_pending 看有没有信号可以处理。一旦 icsk_accept_queue 不为空,就从 inet_csk_wait_for_connect 中返回,在队列中取出一个 struct sock 对象赋值给 newsk
connect 函数
什么情况下,icsk_accept_queue 才不为空呢?当然是三次握手结束才可以。接下来我们来分析三次握手的过程
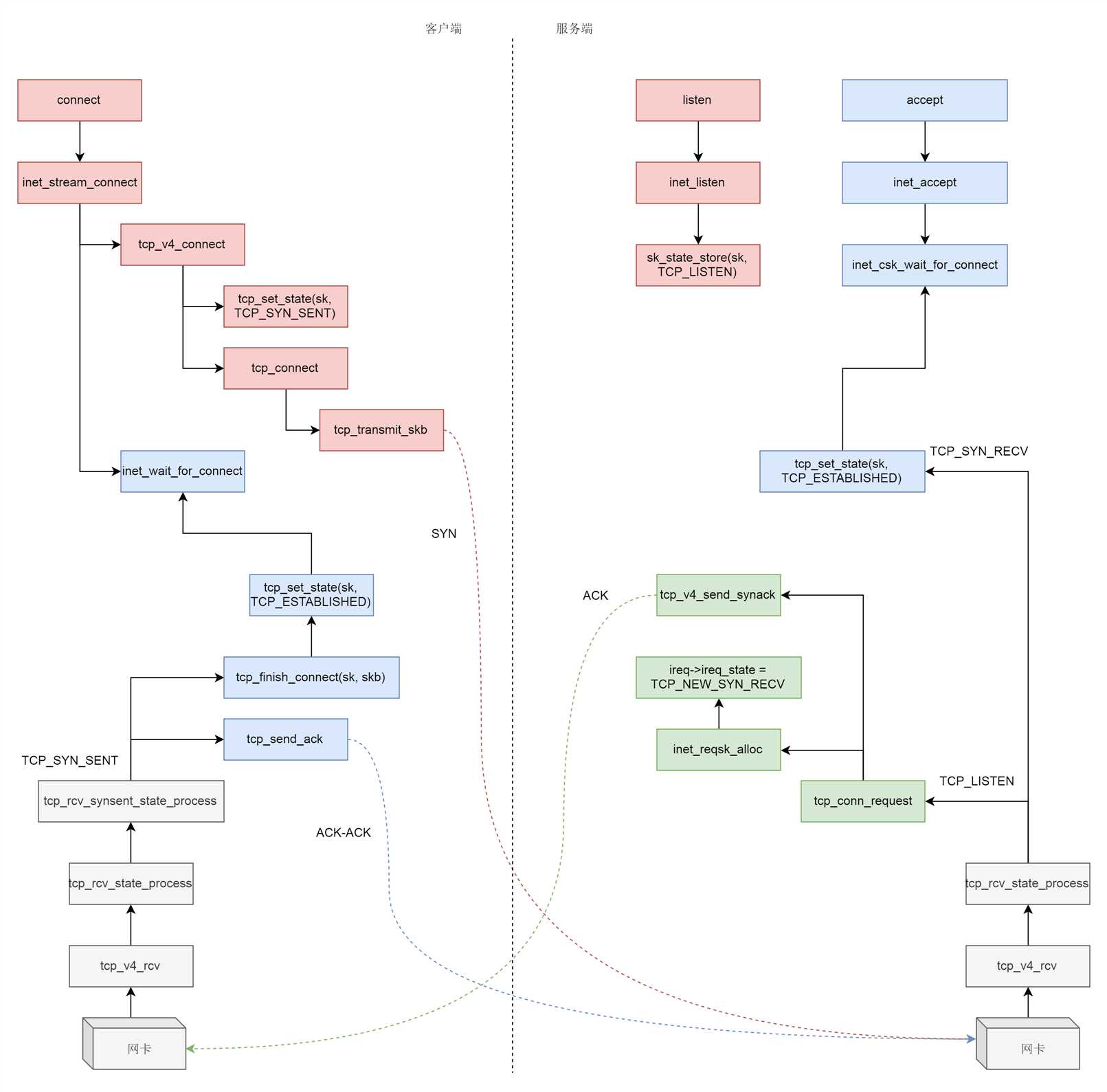
三次握手一般是由客户端调用 connect 发起
SYSCALL_DEFINE3(connect, int, fd, struct sockaddr __user *, uservaddr, int, addrlen) { struct socket *sock; struct sockaddr_storage address; int err, fput_needed; sock = sockfd_lookup_light(fd, &err, &fput_needed); err = move_addr_to_kernel(uservaddr, addrlen, &address); err = sock->ops->connect(sock, (struct sockaddr *)&address, addrlen, sock->file->f_flags); }
connect 函数的实现一开始你应该很眼熟,还是通过 sockfd_lookup_light,根据 fd 文件描述符,找到 struct socket 结构。
接着,我们会调用 struct socket 结构里面 ops 的 connect 函数,根据前面创建 socket 的时候的设定,调用 inet_stream_ops 的 connect 函数,也即调用 inet_stream_connect
/* * Connect to a remote host. There is regrettably still a little * TCP ‘magic‘ in here. */ int __inet_stream_connect(struct socket *sock, struct sockaddr *uaddr, int addr_len, int flags, int is_sendmsg) { struct sock *sk = sock->sk; int err; long timeo; switch (sock->state) { ...... case SS_UNCONNECTED: err = -EISCONN; if (sk->sk_state != TCP_CLOSE) goto out; err = sk->sk_prot->connect(sk, uaddr, addr_len); sock->state = SS_CONNECTING; break; } timeo = sock_sndtimeo(sk, flags & O_NONBLOCK); if ((1 << sk->sk_state) & (TCPF_SYN_SENT | TCPF_SYN_RECV)) { ...... if (!timeo || !inet_wait_for_connect(sk, timeo, writebias)) goto out; err = sock_intr_errno(timeo); if (signal_pending(current)) goto out; } sock->state = SS_CONNECTED; }
connect 函数的实现一开始你应该很眼熟,还是通过 sockfd_lookup_light,根据 fd 文件描述符,找到 struct socket 结构。
接着,我们会调用 struct socket 结构里面 ops 的 connect 函数,根据前面创建 socket 的时候的设定,调用 inet_stream_ops 的 connect 函数,也即调用 inet_stream_connect
/* * Connect to a remote host. There is regrettably still a little * TCP ‘magic‘ in here. */ int __inet_stream_connect(struct socket *sock, struct sockaddr *uaddr, int addr_len, int flags, int is_sendmsg) { struct sock *sk = sock->sk; int err; long timeo; switch (sock->state) { ...... case SS_UNCONNECTED: err = -EISCONN; if (sk->sk_state != TCP_CLOSE) goto out; err = sk->sk_prot->connect(sk, uaddr, addr_len); sock->state = SS_CONNECTING; break; } timeo = sock_sndtimeo(sk, flags & O_NONBLOCK); if ((1 << sk->sk_state) & (TCPF_SYN_SENT | TCPF_SYN_RECV)) { ...... if (!timeo || !inet_wait_for_connect(sk, timeo, writebias)) goto out; err = sock_intr_errno(timeo); if (signal_pending(current)) goto out; } sock->state = SS_CONNECTED; }
如果 socket 处于 SS_UNCONNECTED 状态,那就调用 struct sock 的 sk->sk_prot->connect,也即 tcp_prot 的 connect 函数——tcp_v4_connect 函数
在 tcp_v4_connect 函数中,ip_route_connect 其实是做一个路由的选择。为什么呢?
因为三次握手马上就要发送一个 SYN 包了,这就要凑齐源地址、源端口、目标地址、目标端口。
目标地址和目标端口是服务端的,已经知道源端口是客户端随机分配的,源地址应该用哪一个呢?这时候要选择一条路由,看从哪个网卡出去,就应该填写哪个网卡的 IP 地址
接下来,在发送 SYN 之前,我们先将客户端 socket 的状态设置为 TCP_SYN_SENT。
然后初始化 TCP 的 seq num,也即 write_seq,然后调用 tcp_connect 进行发送
/* Build a SYN and send it off. */ int tcp_connect(struct sock *sk) { struct tcp_sock *tp = tcp_sk(sk); struct sk_buff *buff; int err; ...... tcp_connect_init(sk); ...... buff = sk_stream_alloc_skb(sk, 0, sk->sk_allocation, true); ...... tcp_init_nondata_skb(buff, tp->write_seq++, TCPHDR_SYN); tcp_mstamp_refresh(tp); tp->retrans_stamp = tcp_time_stamp(tp); tcp_connect_queue_skb(sk, buff); tcp_ecn_send_syn(sk, buff); /* Send off SYN; include data in Fast Open. */ err = tp->fastopen_req ? tcp_send_syn_data(sk, buff) : tcp_transmit_skb(sk, buff, 1, sk->sk_allocation); ...... tp->snd_nxt = tp->write_seq; tp->pushed_seq = tp->write_seq; buff = tcp_send_head(sk); if (unlikely(buff)) { tp->snd_nxt = TCP_SKB_CB(buff)->seq; tp->pushed_seq = TCP_SKB_CB(buff)->seq; } ...... /* Timer for repeating the SYN until an answer. */ inet_csk_reset_xmit_timer(sk, ICSK_TIME_RETRANS, inet_csk(sk)->icsk_rto, TCP_RTO_MAX); return 0; }
在 tcp_connect 中,有一个新的结构 struct tcp_sock,如果打开他,你会发现他是 struct inet_connection_sock 的一个扩展,struct inet_connection_sock 在 struct tcp_sock 开头的位置,通过强制类型转换访问,故伎重演又一次
struct tcp_sock 里面维护了更多的 TCP 的状态,咱们同样是遇到了再分析
接下来 tcp_init_nondata_skb 初始化一个 SYN 包,tcp_transmit_skb 将 SYN 包发送出去,inet_csk_reset_xmit_timer 设置了一个 timer,如果 SYN 发送不成功,则再次发送
TCP 层处理
static struct net_protocol tcp_protocol = { .early_demux = tcp_v4_early_demux, .early_demux_handler = tcp_v4_early_demux, .handler = tcp_v4_rcv, .err_handler = tcp_v4_err, .no_policy = 1, .netns_ok = 1, .icmp_strict_tag_validation = 1, }
通过 struct net_protocol 结构中的 handler 进行接收,调用的函数是 tcp_v4_rcv。
接下来的调用链为 tcp_v4_rcv->tcp_v4_do_rcv->tcp_rcv_state_process。
tcp_rcv_state_process,顾名思义,是用来处理接收一个网络包后引起状态变化的
int tcp_rcv_state_process(struct sock *sk, struct sk_buff *skb) { struct tcp_sock *tp = tcp_sk(sk); struct inet_connection_sock *icsk = inet_csk(sk); const struct tcphdr *th = tcp_hdr(skb); struct request_sock *req; int queued = 0; bool acceptable; switch (sk->sk_state) { ...... case TCP_LISTEN: ...... if (th->syn) { acceptable = icsk->icsk_af_ops->conn_request(sk, skb) >= 0; if (!acceptable) return 1; consume_skb(skb); return 0; } ...... }
目前服务端是处于 TCP_LISTEN 状态的,而且发过来的包是 SYN,因而就有了上面的代码,调用 icsk->icsk_af_ops->conn_request 函数。
struct inet_connection_sock 对应的操作是 inet_connection_sock_af_ops,按照下面的定义,其实调用的是 tcp_v4_conn_request
const struct inet_connection_sock_af_ops ipv4_specific = { .queue_xmit = ip_queue_xmit, .send_check = tcp_v4_send_check, .rebuild_header = inet_sk_rebuild_header, .sk_rx_dst_set = inet_sk_rx_dst_set, .conn_request = tcp_v4_conn_request, .syn_recv_sock = tcp_v4_syn_recv_sock, .net_header_len = sizeof(struct iphdr), .setsockopt = ip_setsockopt, .getsockopt = ip_getsockopt, .addr2sockaddr = inet_csk_addr2sockaddr, .sockaddr_len = sizeof(struct sockaddr_in), .mtu_reduced = tcp_v4_mtu_reduced, };
tcp_v4_conn_request 会调用 tcp_conn_request,这个函数也比较长,里面调用了 send_synack,但实际调用的是 tcp_v4_send_synack。
具体发送的过程我们不去管它,看注释我们能知道,这是收到了 SYN 后,回复一个 SYN-ACK,回复完毕后,服务端处于 TCP_SYN_RECV
int tcp_conn_request(struct request_sock_ops *rsk_ops, const struct tcp_request_sock_ops *af_ops, struct sock *sk, struct sk_buff *skb) { ...... af_ops->send_synack(sk, dst, &fl, req, &foc, !want_cookie ? TCP_SYNACK_NORMAL : TCP_SYNACK_COOKIE); ...... } /* * Send a SYN-ACK after having received a SYN. */ static int tcp_v4_send_synack(const struct sock *sk, struct dst_entry *dst, struct flowi *fl, struct request_sock *req, struct tcp_fastopen_cookie *foc, enum tcp_synack_type synack_type) {......}
都是 TCP 协议栈,所以过程和服务端没有太多区别,还是会走到 tcp_rcv_state_process 函数的,只不过由于客户端目前处于 TCP_SYN_SENT 状态,就进入了下面的代码分支
int tcp_rcv_state_process(struct sock *sk, struct sk_buff *skb) { struct tcp_sock *tp = tcp_sk(sk); struct inet_connection_sock *icsk = inet_csk(sk); const struct tcphdr *th = tcp_hdr(skb); struct request_sock *req; int queued = 0; bool acceptable; switch (sk->sk_state) { ...... case TCP_SYN_SENT: tp->rx_opt.saw_tstamp = 0; tcp_mstamp_refresh(tp); queued = tcp_rcv_synsent_state_process(sk, skb, th); if (queued >= 0) return queued; /* Do step6 onward by hand. */ tcp_urg(sk, skb, th); __kfree_skb(skb); tcp_data_snd_check(sk); return 0; } ...... }
tcp_rcv_synsent_state_process 会调用 tcp_send_ack,发送一个 ACK-ACK,发送后客户端处于 TCP_ESTABLISHED 状态
又轮到服务端接收网络包了,我们还是归 tcp_rcv_state_process 函数处理。由于服务端目前处于状态 TCP_SYN_RECV 状态,因而又走了另外的分支。当收到这个网络包的时候,服务端也处于 TCP_ESTABLISHED 状态,三次握手结束
int tcp_rcv_state_process(struct sock *sk, struct sk_buff *skb) { struct tcp_sock *tp = tcp_sk(sk); struct inet_connection_sock *icsk = inet_csk(sk); const struct tcphdr *th = tcp_hdr(skb); struct request_sock *req; int queued = 0; bool acceptable; ...... switch (sk->sk_state) { case TCP_SYN_RECV: if (req) { inet_csk(sk)->icsk_retransmits = 0; reqsk_fastopen_remove(sk, req, false); } else { /* Make sure socket is routed, for correct metrics. */ icsk->icsk_af_ops->rebuild_header(sk); tcp_call_bpf(sk, BPF_SOCK_OPS_PASSIVE_ESTABLISHED_CB); tcp_init_congestion_control(sk); tcp_mtup_init(sk); tp->copied_seq = tp->rcv_nxt; tcp_init_buffer_space(sk); } smp_mb(); tcp_set_state(sk, TCP_ESTABLISHED); sk->sk_state_change(sk); if (sk->sk_socket) sk_wake_async(sk, SOCK_WAKE_IO, POLL_OUT); tp->snd_una = TCP_SKB_CB(skb)->ack_seq; tp->snd_wnd = ntohs(th->window) << tp->rx_opt.snd_wscale; tcp_init_wl(tp, TCP_SKB_CB(skb)->seq); break; ...... }
总结
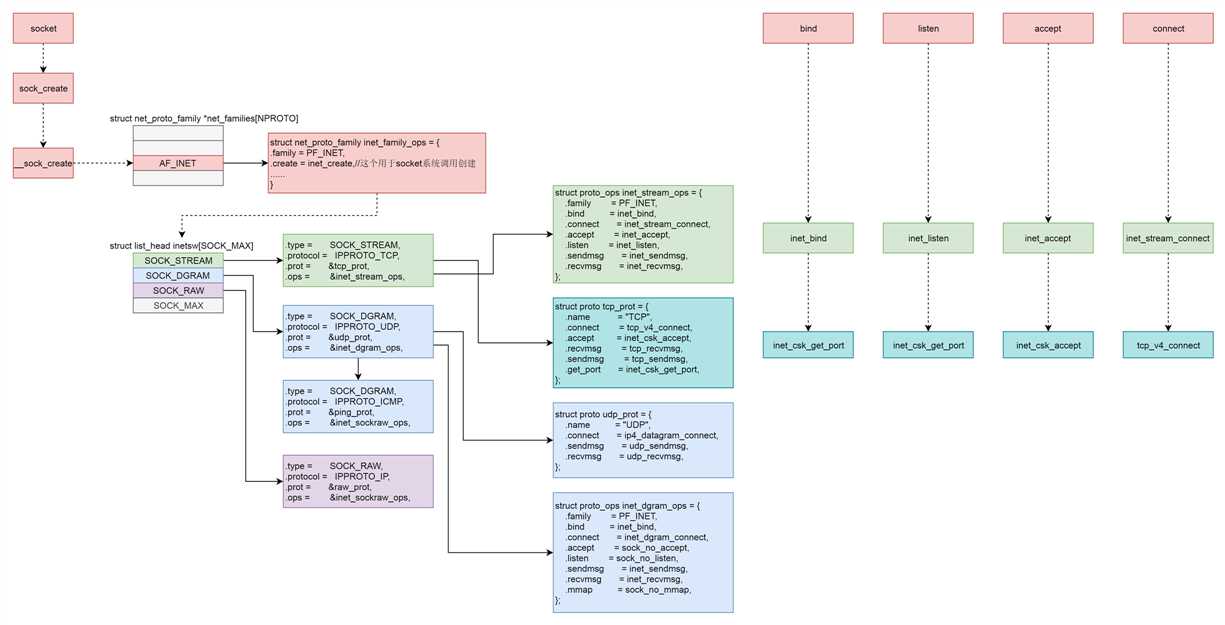
首先,Socket 系统调用会有三级参数 family、type、protocal,通过这三级参数,分别在 net_proto_family 表中找到 type 链表,在 type 链表中找到 protocal 对应的操作。
这个操作分为两层,对于 TCP 协议来讲,第一层是 inet_stream_ops 层,第二层是 tcp_prot 层
于是,接下来的系统调用规律就都一样了:
- bind 第一层调用 inet_stream_ops 的 inet_bind 函数,第二层调用 tcp_prot 的 inet_csk_get_port 函数;
- listen 第一层调用 inet_stream_ops 的 inet_listen 函数,第二层调用 tcp_prot 的 inet_csk_get_port 函数;
- accept 第一层调用 inet_stream_ops 的 inet_accept 函数,第二层调用 tcp_prot 的 inet_csk_accept 函数;
- connect 第一层调用 inet_stream_ops 的 inet_stream_connect 函数,第二层调用 tcp_prot 的 tcp_v4_connect 函数
socket 的 Write 操作
对于网络包的发送,我们可以使用对于 socket 文件的写入系统调用,也就是 write 系统调用
对于 socket 来讲,它的 file_operations 定义如下:
static const struct file_operations socket_file_ops = { .owner = THIS_MODULE, .llseek = no_llseek, .read_iter = sock_read_iter, .write_iter = sock_write_iter, .poll = sock_poll, .unlocked_ioctl = sock_ioctl, .mmap = sock_mmap, .release = sock_close, .fasync = sock_fasync, .sendpage = sock_sendpage, .splice_write = generic_splice_sendpage, .splice_read = sock_splice_read, };
按照文件系统的写入流程,调用的是 sock_write_iter:
static ssize_t sock_write_iter(struct kiocb *iocb, struct iov_iter *from) { struct file *file = iocb->ki_filp; struct socket *sock = file->private_data; struct msghdr msg = {.msg_iter = *from, .msg_iocb = iocb}; ssize_t res; ...... res = sock_sendmsg(sock, &msg); *from = msg.msg_iter; return res; }
在 sock_write_iter 中,我们通过 VFS 中的 struct file,将创建好的 socket 结构拿出来,然后调用 sock_sendmsg。
而 sock_sendmsg 会调用 sock_sendmsg_nosec
static inline int sock_sendmsg_nosec(struct socket *sock, struct msghdr *msg) { int ret = sock->ops->sendmsg(sock, msg, msg_data_left(msg)); ...... }
tcp_sendmsg 函数
int tcp_sendmsg(struct sock *sk, struct msghdr *msg, size_t size) { struct tcp_sock *tp = tcp_sk(sk); struct sk_buff *skb; int flags, err, copied = 0; int mss_now = 0, size_goal, copied_syn = 0; long timeo; ...... /* Ok commence sending. */ copied = 0; restart: mss_now = tcp_send_mss(sk, &size_goal, flags); while (msg_data_left(msg)) { int copy = 0; int max = size_goal; skb = tcp_write_queue_tail(sk); if (tcp_send_head(sk)) { if (skb->ip_summed == CHECKSUM_NONE) max = mss_now; copy = max - skb->len; } if (copy <= 0 || !tcp_skb_can_collapse_to(skb)) { bool first_skb; new_segment: /* Allocate new segment. If the interface is SG, * allocate skb fitting to single page. */ if (!sk_stream_memory_free(sk)) goto wait_for_sndbuf; ...... first_skb = skb_queue_empty(&sk->sk_write_queue); skb = sk_stream_alloc_skb(sk, select_size(sk, sg, first_skb), sk->sk_allocation, first_skb); ...... skb_entail(sk, skb); copy = size_goal; max = size_goal; ...... } /* Try to append data to the end of skb. */ if (copy > msg_data_left(msg)) copy = msg_data_left(msg); /* Where to copy to? */ if (skb_availroom(skb) > 0) { /* We have some space in skb head. Superb! */ copy = min_t(int, copy, skb_availroom(skb)); err = skb_add_data_nocache(sk, skb, &msg->msg_iter, copy); ...... } else { bool merge = true; int i = skb_shinfo(skb)->nr_frags; struct page_frag *pfrag = sk_page_frag(sk); ...... copy = min_t(int, copy, pfrag->size - pfrag->offset); ...... err = skb_copy_to_page_nocache(sk, &msg->msg_iter, skb, pfrag->page, pfrag->offset, copy); ...... pfrag->offset += copy; } ...... tp->write_seq += copy; TCP_SKB_CB(skb)->end_seq += copy; tcp_skb_pcount_set(skb, 0); copied += copy; if (!msg_data_left(msg)) { if (unlikely(flags & MSG_EOR)) TCP_SKB_CB(skb)->eor = 1; goto out; } if (skb->len < max || (flags & MSG_OOB) || unlikely(tp->repair)) continue; if (forced_push(tp)) { tcp_mark_push(tp, skb); __tcp_push_pending_frames(sk, mss_now, TCP_NAGLE_PUSH); } else if (skb == tcp_send_head(sk)) tcp_push_one(sk, mss_now); continue; ...... } ...... }
msg 是用户要写入的数据,这个数据要拷贝到内核协议栈里面去发送;
在内核协议栈里面,网络包的数据都是由 struct sk_buff 维护的,因而第一件事情就是找到一个空闲的内存空间,将用户要写入的数据,拷贝到 struct sk_buff 的管辖范围内。
而第二件事情就是发送 struct sk_buff。
while (msg_data_left(msg)):
- 第一步,tcp_write_queue_tail 从 TCP 写入队列 sk_write_queue 中拿出最后一个 struct sk_buff,在这个写入队列中排满了要发送的 struct sk_buff,为什么要拿最后一个呢?这里面只有最后一个,可能会因为上次用户给的数据太少,而没有填满
- 第二步,tcp_send_mss 会计算 MSS,也即 Max Segment Size。这是什么呢?这个意思是说,我们在网络上传输的网络包的大小是有限制的,而这个限制在最底层开始
MTU(Maximum Transmission Unit,最大传输单元)是二层的一个定义。以以太网为例,MTU 为 1500 个 Byte,前面有 6 个 Byte 的目标 MAC 地址,6 个 Byte 的源 MAC 地址,2 个 Byte 的类型,后面有 4 个 Byte 的 CRC 校验,共 1518 个 Byte。
在 IP 层,一个 IP 数据报在以太网中传输,如果它的长度大于该 MTU 值,就要进行分片传输。在 TCP 层有个 MSS(Maximum Segment Size,最大分段大小),等于 MTU 减去 IP 头,再减去 TCP 头。也就是,在不分片的情况下,TCP 里面放的最大内容。
3. 第三步,如果 copy 小于 0,说明最后一个 struct sk_buff 已经没地方存放了,需要调用 sk_stream_alloc_skb,重新分配 struct sk_buff,然后调用 skb_entail,将新分配的 sk_buff 放到队列尾部
为了减少内存拷贝的代价,有的网络设备支持分散聚合(Scatter/Gather)I/O,顾名思义,就是 IP 层没必要通过内存拷贝进行聚合,让散的数据零散的放在原处,在设备层进行聚合。如果使用这种模式,网络包的数据就不会放在连续的数据区域,而是放在 struct skb_shared_info 结构里面指向的离散数据,skb_shared_info 的成员变量 skb_frag_t frags[MAX_SKB_FRAGS],会指向一个数组的页面,就不能保证连续了
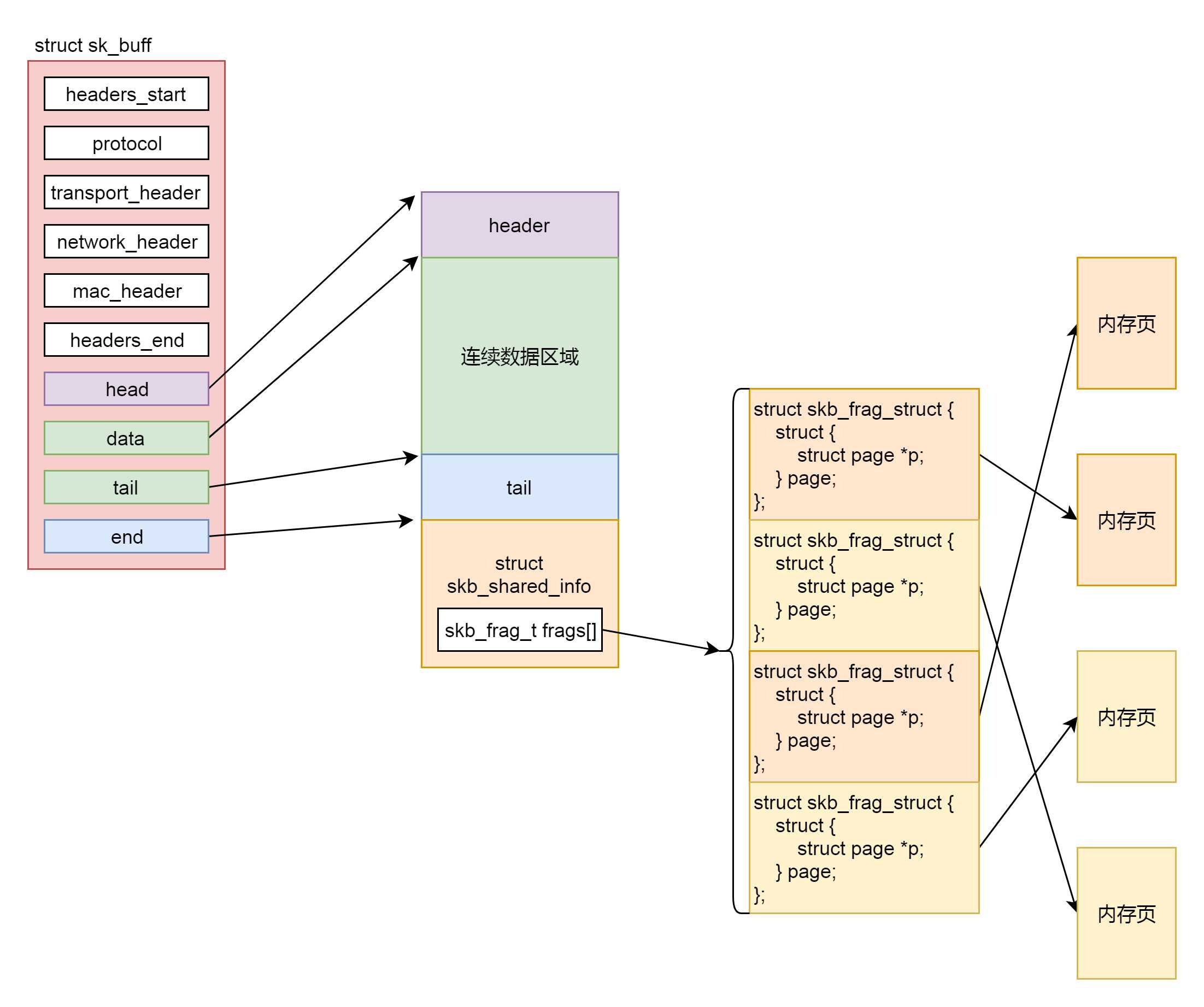
4. 在注释 /* Where to copy to? */ 后面有个 if-else 分支。if 分支就是 skb_add_data_nocache 将数据拷贝到连续的数据区域。else 分支就是 skb_copy_to_page_nocache 将数据拷贝到 struct skb_shared_info 结构指向的不需要连续的页面区域。
5. 第五步,就是要发生网络包了。第一种情况是积累的数据报数目太多了,因而我们需要通过调用 __tcp_push_pending_frames 发送网络包。第二种情况是,这是第一个网络包,需要马上发送,调用 tcp_push_one。无论 __tcp_push_pending_frames 还是 tcp_push_one,都会调用 tcp_write_xmit 发送网络包。
tcp_write_xmit 函数
static bool tcp_write_xmit(struct sock *sk, unsigned int mss_now, int nonagle, int push_one, gfp_t gfp) { struct tcp_sock *tp = tcp_sk(sk); struct sk_buff *skb; unsigned int tso_segs, sent_pkts; int cwnd_quota; ...... max_segs = tcp_tso_segs(sk, mss_now); while ((skb = tcp_send_head(sk))) { unsigned int limit; ...... tso_segs = tcp_init_tso_segs(skb, mss_now); ...... cwnd_quota = tcp_cwnd_test(tp, skb); ...... if (unlikely(!tcp_snd_wnd_test(tp, skb, mss_now))) { is_rwnd_limited = true; break; } ...... limit = mss_now; if (tso_segs > 1 && !tcp_urg_mode(tp)) limit = tcp_mss_split_point(sk, skb, mss_now, min_t(unsigned int, cwnd_quota, max_segs), nonagle); if (skb->len > limit && unlikely(tso_fragment(sk, skb, limit, mss_now, gfp))) break; ...... if (unlikely(tcp_transmit_skb(sk, skb, 1, gfp))) break; repair: /* Advance the send_head. This one is sent out. * This call will increment packets_out. */ tcp_event_new_data_sent(sk, skb); tcp_minshall_update(tp, mss_now, skb); sent_pkts += tcp_skb_pcount(skb); if (push_one) break; } ...... }
以上是关于数据包发送的主要内容,如果未能解决你的问题,请参考以下文章