分布式爬虫架构设计与实现
Posted
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了分布式爬虫架构设计与实现相关的知识,希望对你有一定的参考价值。
由于scrapy框架需要更多的学习成本,还有分布式爬虫也需要redis来实现,调度方式也不是很符合业务要求,于是就自己设计了个分布式爬虫架构。架构图如下:
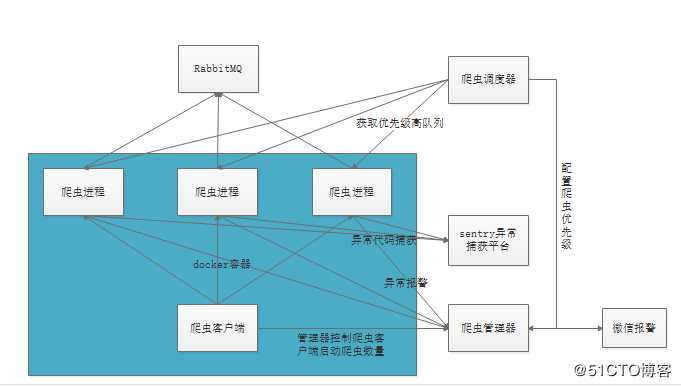
爬虫的客户端为tornado编写的服务,爬虫管理器也是tornado编写的后台管理服务,主要功能:获取客户端的状态信息,爬虫进程数量,启动指定数量的爬虫进程,中断、重启爬虫,爬虫异常通知等。
爬虫进程与调度器间的请求非常频繁,所以使用socket长连,获取优先级高的队列,调度器的优先级算法,根据业务需求来编写。
消息队列使用rabbitmq,而不用redis,因为rabbitmq的消息确认机制,能够保证每个要爬的url都能被成功请求,不会因为某些异常而导致数据漏爬。
爬回的数据看业务需求,可以直接入库,或者放入Kafka。建议先不进行数据清洗,避免偶尔数据清洗错误时,又要重新爬取。
求offer:python后端,或者爬虫
欢迎一起交流学习
以上是关于分布式爬虫架构设计与实现的主要内容,如果未能解决你的问题,请参考以下文章