Django之ORM
Posted banbosuiyue
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了Django之ORM相关的知识,希望对你有一定的参考价值。
ORM对象关系映射,是Django中用于操作数据库的Python语句,并且每一条ORM语句,都可以翻译成一条sql语句,而且是符合sql语句优化原则的语句
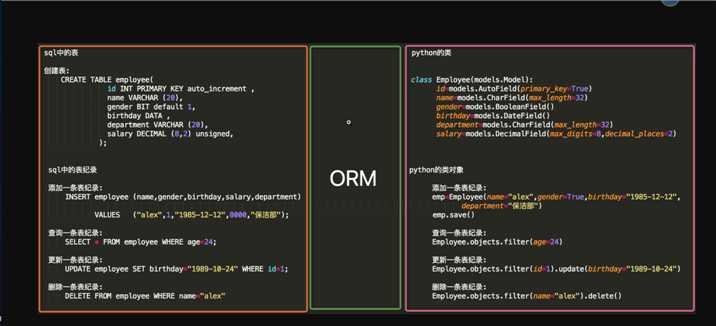
0 创建表之前的准备工作
(1) 先在终端下的mysql中创建一个数据库。
create database db_book charset=utf8mb4;
(2) 在pycharm界面中连接数据库
Database中的+号 -> Data Source -> MySQL -> 填写Name(@localhost), User(root), Password(xxx), Database(db_book) -> Test Connection -> 下面出现对勾,就代表连接成功
(3) 在主应用drfdemo中的__init__.py中设置使用pymysql作为数据库驱动,写下如下代码
import pymysql pymysql.install_as_MySQLdb()
(4) settings.py配置文件中设置mysql的账号密码
DATABASES = { # ‘default‘: { # ‘ENGINE‘: ‘django.db.backends.sqlite3‘, # ‘NAME‘: os.path.join(BASE_DIR, ‘db.sqlite3‘), # } ‘default‘: { ‘ENGINE‘: ‘django.db.backends.mysql‘, ‘NAME‘: "db_book", #db_book是我们用的数据库的库名 "HOST": "127.0.0.1", "PORT": 3306, "USER": "root", "PASSWORD": "xxx", }, }
下面进入正题
一 针对单表的创建,增删改查
1.1 在models.py中创建单表
class Publish(models.Model): name = models.CharField(max_length=32) email = models.CharField(max_length=32) addr = models.CharField(max_length=32)
1.2
Python终端Terminal中执行命令
迁移数据库
python manage.py makemigration
在数据库中创建表
python manage.py migrate
这个时候就可以在pycharm中的Database中看到models.py中我们要创建的表了
2 单表添加数据
(1) 手动在数据库里插入就不说了,实际项目中一般是前端提交过来的数据调用views.py中的方法执行增删改查操作
(2) 在view.py文件中写插入表的语句
# 添加记录方式一 (实例化对象) 一条记录就对应一个对象 此方法分两步,第一步对Book模型类进行实例化得到book_obj模型类对象,第二步执行book_obj对象.save()方法进行数据保存 book_obj=Book(title="java",pub_data="2012-12-12",prict=120,publish="西瓜出版社") book_obj.save() # 添加记录方式二 (objects.create方法) book=Book.objects.create(title="python",pub_data="2019-12-30",prict=666,publish="香蕉出版社") # 这里的book就对应着一条记录的模型类对象, book都能点出来表中字段的值 就是对象 . 属性
QuerySet数据类型的概念
QuerySet数据类型是针对Django创建的一种序列数据类型,是类似列表的数据类型,不过列表里面可以放任意数据类型(包括放对象,函数等等),QuerySet数据类型有两种形式
第一种 类似列表里面装模型类对象的形式
所以这种QuerySet序列可索引取值(取出的值就是一个个的模型类对象),可切片,可for i in遍历等等
(1)以下列出几种返回第一种QuerySet序列的查询方法
ret1=Book.objects.all()
print(ret1)
# 打印结果 <QuerySet [<Book: Book object (16)>, <Book: Book object (17)>,...
ret2=Book.objects.filter(title="小黄书")
print(ret2) # 注意就算filter过滤出的数据只有一条,这一条也是装在QuerySet序列里的
# 打印结果 <QuerySet [<Book: Book object (19)>, <Book: Book object (20)>]>
(2)下列几种返回模型类对象的查询方法
book_obj=Book.objects.get(title="红楼梦")
print(book_obj) # 打印结果Book object (22)
ret2=Book.objects.filter(title="小黄书").first()
# 上面一句话等同于Book.objects.filter(title="小黄书")[0]
print(ret2) # 打印结果Book object (19)
可以看出,查询多条数据的查询方式一般就返回的是QuerySet序列,而查询一条数据的查询方式,返回的就是模型类对象.
模型类就是models.py中建表的类,比如Book类中有title属性,对应的就是book表中有title字段,并且由模型类查询得到的模型类对象,都可以点出其中的属性,比如book_obj=Book.objects.get(id=16)
print(book_obj.title) # 打印出书名,异形
print(book_obj.price) # 打印出价格,32
...
第二种 类似列表里面套字典的形式
这种QuerySet序列是通过.values()方法查询出来的返回的数据类型,能够使用字典的相关操作方法
只有QuerySet序列才有.values()方法,用于取到自己想要的字段,模型类对象没有.values()方法
使用.values()方法,你需要传参字段,返回一个特殊的QuerySet序列,这个序列中装着的是字典,字典中的键值对是 字段:字段值的形式,比如说values(“name”,”age”)中的参数相当于sql语句select name,age from table1 中的name和age,所以这个QuerySet序列通过遍历之后,能通过键取出name和age值,例如:
ret=Book.objects.filter(title="小黄书").values("pub_date","price")
print(ret)
# <QuerySet [{‘pub_date‘: datetime.date(2019, 12, 7), ‘price‘: Decimal(‘666.00‘)}, {‘pub_date‘: datetime.date(2019, 12, 28), ‘price‘: Decimal(‘666.00‘)}]>
for i in ret:
print(“%s,%s”%(i["price"],i[“pub_date”]) )
# 666.00, 2019-12-07
# 666.00, 2019-12-28
3 单表查询
除了添加表记录,删和改都得通过查询到这条表记录,再执行对应的删或改方法就行
3.1 直接查询
Book.objects.可以.出来以下一些方法(Book就是models.py中的模型类)
<1> all(): 查询所有结果
<2> filter(**kwargs): 它包含了与所给筛选条件相匹配的对象(其中**kwargs代表关键字形参,比如说有个字段名叫name,那么查询name是xiaoming的参数就传name=”xiaoming”),可以传多个关键字形参,代表同时满足多个条件,用逗号隔开,返回QuerySet序列
<3> get(**kwargs): 返回与所给筛选条件相匹配的模型类对象,返回结果有且只有一个,如果符合筛选条件的对象超过一个或者没有都会抛出错误。
<4> exclude(**kwargs): 它包含了与所给筛选条件不匹配的对象
<5> order_by(*field): 对查询结果排序
<6> reverse(): 对查询结果反向排序
<8> count(): 返回数据库中匹配查询(QuerySet)的对象数量。
<9> first(): 返回第一条记录
<10> last(): 返回最后一条记录
<11> exists(): 如果QuerySet包含数据,就返回True,否则返回False
<12> values(*field): 返回一个特殊的QuerySet序列,详情见QuerySet数据类型的介绍
<13> values_list(*field): 它与values()非常相似,它返回的是一个元组序列,values返回的是一个字典序列
<14> distinct(): 从返回结果中剔除重复纪录
3.2 基于双下划线的模糊查询
Book.objects.filter(price__in=[100,200,300])
Book.objects.filter(price__gt=100)
Book.objects.filter(price__lt=100)
Book.objects.filter(price__range=[100,200])
Book.objects.filter(title__contains="python")
Book.objects.filter(title__icontains="python")
Book.objects.filter(title__startswith="py")
Book.objects.filter(pub_date__year=2012)
4 单表删除数据
book=Book.objects.get(pk=1)
book.delete()
合起来写就是Book.objects.get(pk=1).delete()
delete() 方法是 QuerySet 上的方法,但并不适用于 Manager 本身。这是一种保护机制,是为了避免意外地调用 Entry.objects.delete() 方法导致 所有的 记录被误删除。如果你确认要删除所有的对象,那么你必须显式地调用:
Entry.objects.all().delete()
如果不想级联删除,可以设置为:
pubHouse = models.ForeignKey(to=‘Publisher‘, on_delete=models.SET_NULL, blank=True, null=True)
5 单表修改数据
Book.objects.filter(title__startswith="py").update(price=120)
此外,update()方法对于任何结果集(QuerySet)均有效,这意味着你可以同时更新多条记录,update()方法会返回一个整型数值,表示受影响的记录条数。
二 针对多表的创建,增删改查
1.1 在models.py文件中写建表语句 也就是写一个Book类 使用命令迁移后就是一个book表,代码如下
from django.db import models # Create your models here. class Book(models.Model): id = models.AutoField(primary_key=True) title = models.CharField(max_length=32) pub_date = models.DateField() price = models.DecimalField(max_digits=8, decimal_places=2) publisher = models.ForeignKey(to="Publish",to_field="pid", on_delete=models.CASCADE) authors=models.ManyToManyField("Author") def __str__(self): return self.title class Publish(models.Model): pid=models.AutoField(primary_key=True) name = models.CharField(max_length=32) email = models.CharField(max_length=32) addr = models.CharField(max_length=32) def __str__(self): return self.name class Author(models.Model): name=models.CharField(max_length=32) age=models.IntegerField() ad=models.OneToOneField("AuthorDetail",on_delete=models.CASCADE) class AuthorDetail(models.Model): tel=models.CharField(max_length=32) email=models.CharField(max_length=32) class User(models.Model): name=models.CharField(max_length=32) pwd=models.CharField(max_length=32)
其中
to_field="pid" 表示这个外键关联另一张表的pid,对应的,另一张表建表时需要将pid作为主键;如果不加这句话,表示这个外键将自动关联另一张表的主键id,默认自动创建,建表时不用写这个id字段
on_delete=models.CASCADE 联级删除
ManyToManyField 多对多关系,一个字段主动关联多对多关系后,Django自动生成一张多对多关系表.比如上述book表和author表为多对多关联,Django默认创建一张book_author表,用来关联两张表的主键,形成多对多关系
OneToOneField 一对一关系
ForeignKey 一对多直接使用外键
AutoField 自动设置主键
booleanField 布尔型
DecimalField 浮点型
# 表格详情图(进行数据查询时看着图写比较清晰)
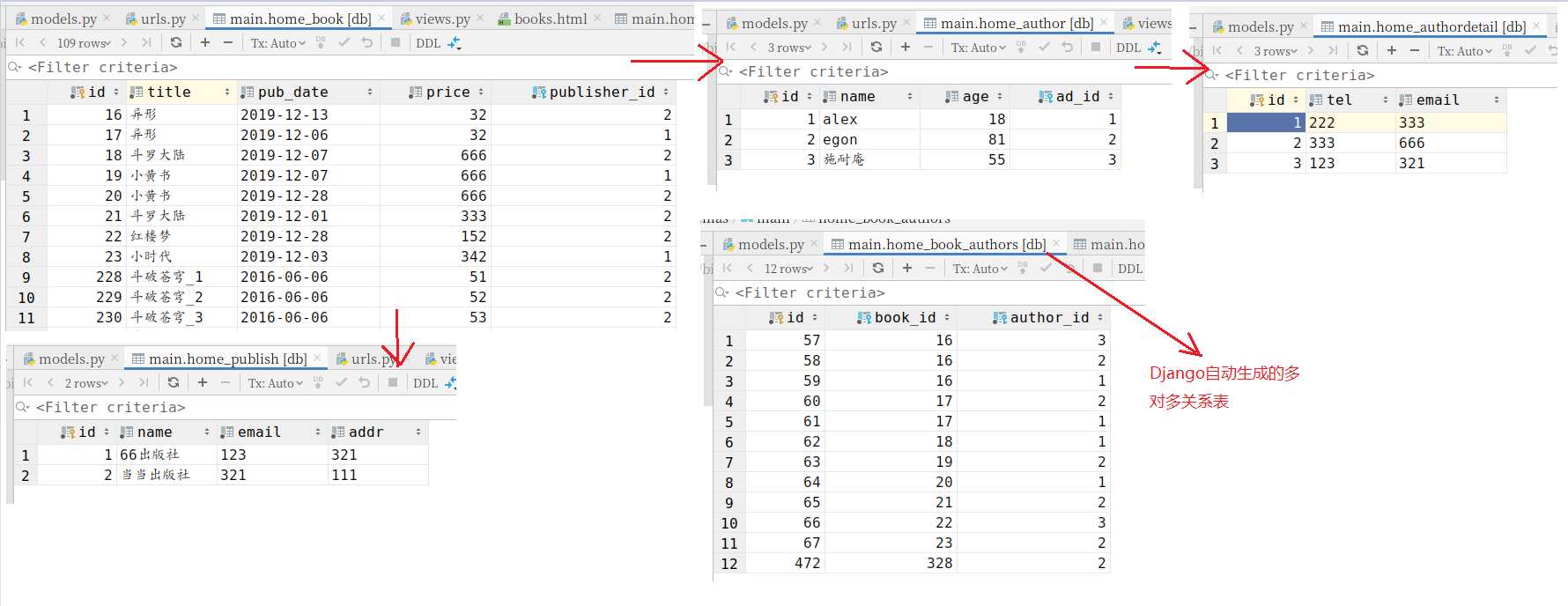
1.2 创建3类关联表
pycharm中每创建一张表都会有一个主键,如果你不加,他会默认加一个id字段作为主键
models中创建多张关系表
1) 多对一:(在多的那张表中设置外键进行多对一关联)
publisher=models.ForeignKey(to="Publish", on_delete=models.CASCADE)
#在多的那个表中的字段publisher,设置为外键关联Publish表(也就是Publish类)
# 级联删除:models.CASCADE 当关联表中的数据删除时,该外键也删除
# 置空:models.SET_NULL 当关联表中的数据删除时,该外键置空,当然,你的这个外键字段得允许为空,null=True
# 设置默认值:models.SET_DEFAULT 删除的时候,外键字段设置为默认值,所以定义外键的时候注意加上一个默认值。
2) 一对一:(OneToOneField)
models中创建一对一外键关系表,就是在多对一的基础上,在原来多的那个表添加一个unique唯一约束,就是一对一了.models中简化了操作,OneToOneField方法
class Author(models.Model): ... ad=models.OneToOneField("AuthorDetail",on_delete=models.CASCADE)
使用OneToOneField之后,会将此表中的ad字段自动设置成unique唯一约束,并作为外键(并改名为ad_id作为数据库中的字段)关联AuthorDetail这张表的主键,这样形成一对一关联
3) 多对多:(ManyToManyField)
在两张表里分别设置两个外键,然后分别关联(新创建的)第三张表的两个字段,ORM中自动创建第三张关系表,第三张表的表名是 子应用名_这个类名_这个字段名,也就是home_book_authors,这张表中的两个字段book_id和author_id多对多一一对应
class Book(models.Model): ... authors=models.ManyToManyField("Author")
# Author是多对多的另一张表
2 多表添加记录
2.1 一对多添加
方式1:
# 先在publish表里利用出版社id获取出版社对象 publish_obj=Publish.objects.get(nid=1) # 再在book表中添加一条数据,book_obj.publishr正向查询按字段,按照book表中的publishr字段,也就是给publish表添加了一个模型类对象publish_obj,即添加了一条数据(因为book_obj.publishr可以点出来publish表中的各个字段) book_obj=Book.objects.create(title="西游记,price=100, publishDate="2012-12-12",publishr=publish_obj) # 多个book对应一个publish(出版社)
方式2:(更简便)
book_obj=Book.objects.create(title="西游记",publishDate="2012-12-12" ,price=100,publishr_id=1) # 直接给主动关联多对一的那个字段赋值,完成添加操作
2.2 一对一添加
同上一对多,一模一样
2.3 多对多添加
# 当前生成的书籍对象 book_obj=Book.objects.create(title="追风筝的人",price=200, publishDate="2012-11-12",publishr_id=1) # 为书籍绑定的做作者对象 listvar1=[“yuan”,”alex”] #前端传过来的两个作者 listvar2=[] for i in listvar1: j=Author.objects.filter(name=i).first() # 在Author表中作者叫yuan的纪录 listvar2.append(j) # 绑定多对多关系,即向关系表book_authors中添加纪录 book_obj.authors.add(*listvar2) # 将某些特定的 model 对象添加到被关联对象集合中 book_obj.authors.add(*[]) 这里好像也可以这样写 listvar2=Author.objects.filter(name_in=listvar1) book_obj.authors.add(*listvar2) (当然现在前端提交过来的是名字,如果你让前端提交过来的直接是作者对应的author_id),这样简单的操作就添加完成了) authors_id = request.POST.getlist("authors") #前端传过来作者id列表 book=Book.objects.create(title=title, price=price, pub_date=pub_date, publisher_id=publish_id) book.authors.add(*authors_id) # *author_id解包多个普通形参列表,相当于传入多个普通形参
3 多表修改记录
# 先添加其他字段 Book.objects.filter(id=pk).update(title=title, price=price, pub_date=pub_date, publisher_id=publish_id) # 再添加多对多字段 book_obj=Book.objects.filter(id=pk).first() book_obj.authors.clear() book_obj.authors.add(*authors_id) # 上面两行相当于 book_obj.authors.set(authors_id) #set后面需要传参列表
4 多表查询
参考博客园:
cnblogs.com/yuanchenqi/articles/8963244.html
口诀: 正向查询按字段,反向查询按表名(的小写)
正反向查询都是在两张表是关联表的基础上应用的,从models.py中可以看出,比如说A表和B表关联,A表为主动关联的一方(从建表语句就可以看出),则由A表查B表为正向查询,B查A则为反向查询
图示:
正向查询
Book(多) ----------------------------> Publish(一)
<----------------------------
反向查询
正向查询
Author(一) ---------------------------> AuthorDetail(一)
<---------------------------
反向查询
正向查询
Book(多) -----------------------------> Author(多)
<-----------------------------
反向查询
3.1 基于对象的跨表查询(子查询) 模型类对象.字段/表名.属性值
正向查询按字段 (publishr)
例1 查询主键为1的书籍所对应的出版社名字
book_obj=Book.objects.filter(pk=1).first() print(book_obj.publishr.name) # book_obj.publishr 是主键为1的书籍对象关联的出版社对象,然后获取到publish表中的name字段对应的值
例2 查出红楼梦的所有作者的名字和年龄
# 正向查询按字段,那应该是book表的哪个字段呢,看book表的建表语句authors=models.ManyToManyField("Author") # 这个就是Book类中主动多对多关联的字段,用的就是这个字段 book=Book.objects.filter(title="红楼梦").first() print(book.authors.all().values("name","age")) # <QuerySet [{‘name‘: ‘alex‘, ‘age‘: 345}, {‘name‘: ‘egon‘, ‘age‘: 324}]>
反向查询按表名 (book):
例1 查询苹果出版社出版的所有书籍的名称
publish=Publish.objects.get(name="苹果出版社") # publish.book.all() 与苹果出版社关联的所有书籍对象集合 book_list=publish.book.all() for book_obj in book_list: print(book_obj.title)
例2 查询人民出版社出版社所有书籍的名称和价格
pub_obj=Publish.objects.filter(name="人民出版社").first() print(pub_obj.book_set.all().values("title","price")) # <QuerySet [{‘title‘: ‘红楼梦‘, ‘price‘: Decimal(‘122.00‘)}, {‘title‘: ‘水浒传‘, ‘price‘: Decimal(‘333.00‘)}]> # 反向查询应该按表名Book的小写也就是book,那为什么要用book_set,因为这里一个出版社对应多本书,所以由出版社查书,查询的时候会出现多个book对象符合条件,所以这里规定要用book_set,而不是book,当你这里非要写book的时候会报错 AttributeError: ‘Author‘ object has no attribute ‘book‘ 所以,当你通过一对一关系查询的时候,直接用表名/字段名;当你通过一对多或者多对多,查多的这个表时,要用表名/字段名加上”_set”
例3 alex出版过得所有书籍的名称和价格
alex_obj=Author.objects.filter(name="alex").first() print(alex_obj.book_set.all().values("title","price"))
3.2 基于双下划线的跨表查询 (jion联表查询),联表之后随便写,遵循规则就行
同样遵循正向查询按字段,反向查询按表名
例一 三国演义这本书籍的出版社的邮箱
方法一 # 查的是Book,然后正向查询按字段publisher,然后publish__email跨到publish表拿到email ret=Book.objects.filter(title="三国演义").values("publisher__email") print(ret) # <QuerySet [{‘publisher__email‘: ‘234‘}]> 方法二 # 查的是Publish,然后反向查询按表名book,然后book__title跨到book表拿title,将book__title="三国演义"作为筛选条件获取到email # 实际就是查的时候,查自己表的字段,直接写字段,查别的表的字段,就要按正/反向查询写 字段/表名__字段,注意:作为values()的参数,必须要用引号包起来,也就是”字段/表名__字段”,当然这两张表不能是没关系的两张表,必须是关联的表,否则也谈不上正反向查询 ret=Publish.objects.filter(book__title="三国演义").values("email") print(ret) # <QuerySet [{‘email‘: ‘234‘}]> 方法三(基于对象的查询,有点麻烦) # 正向查询按字段,利用.publisher得到publish表记录(模型类对象),然后对象.email取到邮箱 ret = Book.objects.filter(title=‘三国演义‘).first().publisher.email print(ret) # 直接打印出邮箱 234
例二 查询人民出版社出版社所有书籍的名称和价格
# 方法一 ret=Publish.objects.filter(name="人民出版社") .values("book__title","book__price") # 方法二 ret=Book.objects.filter(publisher__name="人民出版社") .values("title","price")
例三 查询alex的手机号
ret=Author.objects.filter(name="alex").values("ad__tel") ret=AuthorDetail.objects.filter(author__name="alex").values("tel") 例四 红楼梦的所有作者的名字和年龄 Book.objects.filter(title="红楼梦").values("authors__name", "authors__age") Author.objects.filter(book__title="红楼梦").values("name","age")
例五 连续跨表: 手机号以123开头的作者出版过的所有书籍名称以及出版社名称
# 连续跨表一般挑选关系表中最中间的表作为起点,跨表更容易 # 方法一,以Book表为起点 Book.objects.filter(authors__ad__tel__startswith="123").values("title", "publisher__name") # 方法二,以Author表为起点 Author.objects.filter(ad__tel__startswith="123").values("book__title", "book__publisher__name"))
以上是关于Django之ORM的主要内容,如果未能解决你的问题,请参考以下文章