常见神经网络
Posted h694879357
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了常见神经网络相关的知识,希望对你有一定的参考价值。
1、感知野:
在卷积神经网络中,感受野(Receptive Field)的定义是卷积神经网络每一层输出的特征图(feature map)
上的像素点在输入图片上映射的区域大小。再通俗点的解释是,特征图上的一个点对应输入图上的区域,如图1所示。
感受野(Receptive Field),指的是神经网络中神经元“看到的”输入区域,在卷积神经网络中,feature map上某个元素的计算受输入图像上某个区域的影响,这个区域即该元素的感受野。
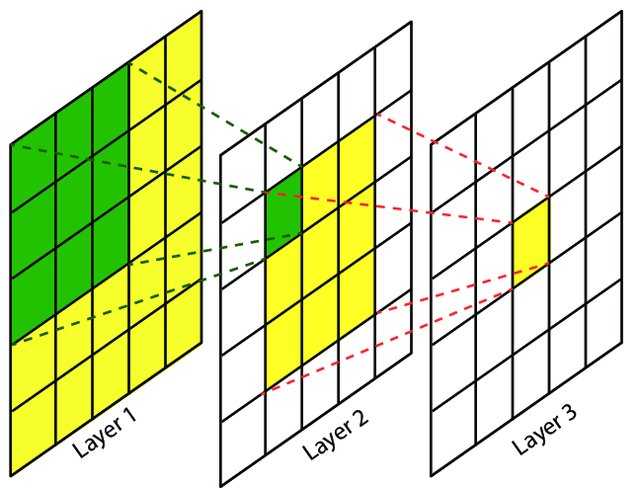
卷积神经网络中,越深层的神经元看到的输入区域越大,如下图所示,kernel size 均为3×33×3,stride均为1,绿色标记的是Layer2Layer2 每个神经元看到的区域,黄色标记的是Layer3Layer3 看到的区域,
具体地,Layer2Layer2每个神经元可看到Layer1Layer1 上 3×33×3 大小的区域,Layer3Layer3 每个神经元看到Layer2Layer2 上 3×33×3 大小的区域,该区域可以又看到Layer1Layer1上 5×55×5 大小的区域。
2、VGG
该网络是在ILSVRC 2014上的相关工作,主要工作是证明了增加网络的深度能够在一定程度上影响网络最终的性能。
VGG有两种结构,分别是VGG16和VGG19,两者并没有本质上的区别,只是网络深度不一样。
对于给定的感受野(与输出有关的输入图片的局部大小),采用堆积的小卷积核是优于采用大的卷积核,因为多层非线性层可以增加网络深度来保证学习更复杂的模式,而且代价还比较小(参数更少)。
简单来说,在VGG中,使用了3个3x3卷积核来代替7x7卷积核,使用了2个3x3卷积核来代替5*5卷积核,这样做的主要目的是在保证具有相同感知野的条件下,提升了网络的深度,在一定程度上提升了神经网络的效果。
VGG缺点:
1.VGG耗费更多计算资源,并且使用了更多的参数(这里不是3x3卷积的锅),导致更多的内存占用(140M)。
其中绝大多数的参数都是来自于第一个全连接层。VGG可是有3个全连接层!
AlexNet 总体结构和 LeNet 相似,但是有极大改进:
- 由五层卷积和三层全连接组成,输入图像为三通道 224x224 大小,网络规模远大于 LeNet
- 使用了 ReLU 激活函数
- 使用了 Dropout,可以作为正则项防止过拟合,提升模型鲁棒性
- 一些很好的训练技巧,包括数据增广、学习率策略、weight decay 等
5、ImageNet项目是一个用于视觉对象识别软件研究的大型可视化数据库。
ImageNet、CIFAR、MNIST 或 IMDB 都是数据集
以上是关于常见神经网络的主要内容,如果未能解决你的问题,请参考以下文章