并发编程之J.U.C的第二篇
Posted haizai
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了并发编程之J.U.C的第二篇相关的知识,希望对你有一定的参考价值。
并发编程之J.U.C的第二篇
该类自JDK8加入,是为了进一步优化读性能,它的特点是使用读锁、写锁时都必须配合【戳】使用
加解读锁
加锁写锁
乐观锁,StampedLock 支持 tryOptimisticRead()方法(乐观读),读取完毕后需要做一次戳校验,如果校验通过,表示这期间确实没有写操作,数据可以安全使用,如果校验没通过,需要重新获取读锁,保证数据安全。
信号量,用来限制能同时访问共享资源的线程上限。
- 加锁解锁流程
Semaphore 有点像一个停车场,permits 就好像停车位数量,当线程获得了 permits就像是获得了停车位,然后停车场显示空余车位减一
刚开始,permits(state)为3,这时5个线程来获取资源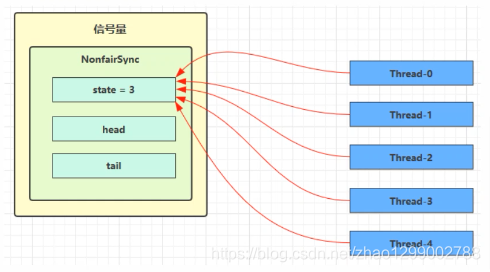
假设其中 Thread - 1,Thread - 2,Thread -4 cas 竞争成功,而Thread - 0和Thread - 3 竞争失败,进入AQS队列park阻塞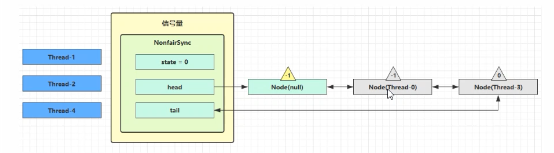
这时 Thread - 4 释放了 permits,状态如下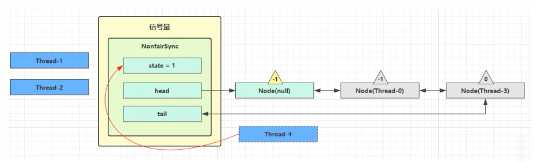
接下来Thread - 0 竞争成功,permits再次设置为0,设置自己为head节点,断开原来的head节点,unpark接下来的Thread - 3 节点,但由于 permits是0,因此Thread - 3 在尝试不成功后再次进入 park状态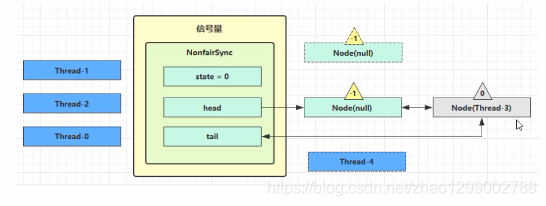
用来进行线程同步协作,等待所有线程完成倒计时。
其中构造参数用来初始化等待计数值,await()用来等待计数归零,countDown()用来让计数减一
循环栅栏,用来进行线程协作,等待线程满足某个计数。构造时设置【计数个数】,每个线程执行到某个需要“同步”的时刻调用await()方法进行等待,当等待的线程数满足【计数个数】时,继续执行
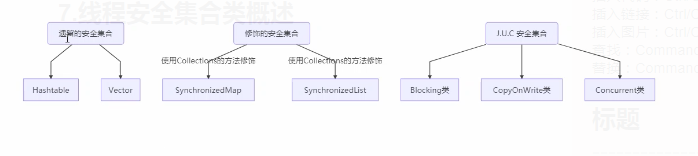
线程安全集合类可以分为三大类 :
- 遗留的线程安全集合如 Hashtable、Vector
- 使用Collections装饰的线程安全集合,如 :
- Collections.synchronizedCollection
- Collections.synchronizedList
- Collections.synchronizedMap
- Collections.synchronizedSet
- Collections.synchronizedNavigableMap
- Collections.synchronizedNavigableSet
- Collections.synchronizedMap
- Collections.synchronizedSet
- java.util.concurrent.*
重点介绍java.util.concurrent.*下的线程安全集合类,里面包含三类关键词 :Blocking、CopyOnWrite、Concurrent - Blocking大部分实现基于锁,并提供用来阻塞的方法
- CopyOnWrite 之类容器修改稍相对较重
- Concurrent类型的容器
- 内部很多操作使用cas优化,一般可以提供高吞吐量
- 弱一致性
- 遍历时弱一致性,例如,当利用迭代器遍历时,如果容器发生修改,迭代器任然可以进行进行遍历,这时内存是旧的
- 求大小弱一致性,size操作未必是100%准确
- 读取弱一致性
- 遍历时如果发生了修改,对于非安全容器来讲,使用fail-fast机制也就是让遍历立刻失败,抛出ConcurrentModificationExecption,不再继续遍历
单词计数问题 :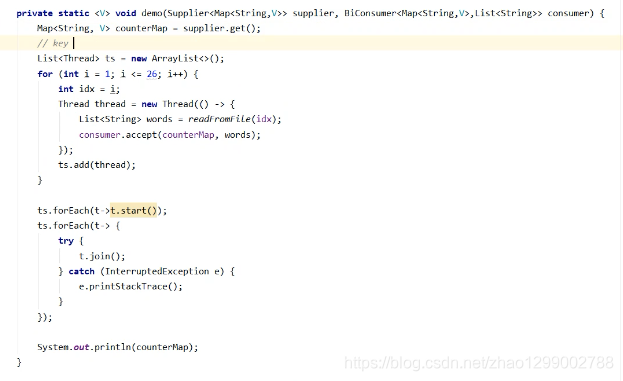
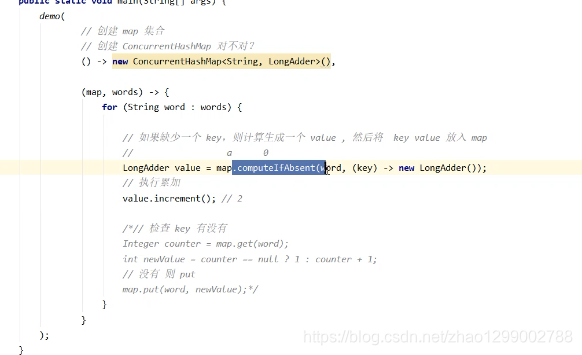
重要属性和内部类
构造器分析
可以看到实现了懒惰初始化,在构造方法中仅仅计算了table的大小,以后在第一次使用时才会真正的创建
get流程分析
put流程
以下数组简称(table),链表简称(bin)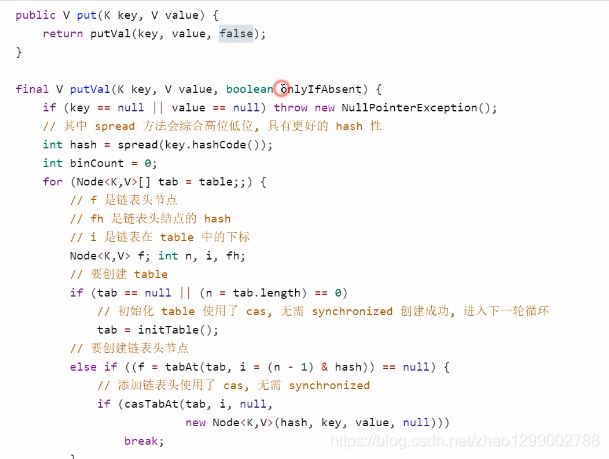








size计算流程
size计算实际发生在put、remove改变集合元素的操作之中
- 没有竞争发生,向baseCount累加计数
- 有竞争发生,新建counterCells,向其中的一个cell累加计数
- counterCells初始有两个cell
- 如果计数竞争比较激烈,会创建新的cell来累加计数
它维护了一个segment数组,每个segment对应一把锁
- 优点 : 如果多个线程访问不同的segment,实际是没有冲突的,这与jdk8中是类似的
- 缺点 :Segments数组默认大小为16,这个容量初始化指定后就不能改变了,并且不是懒得初始化
构造器分析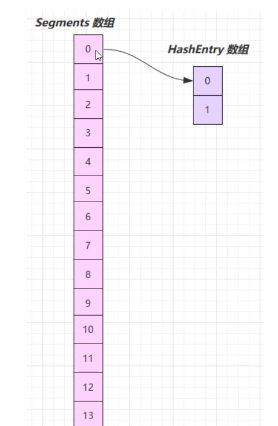

可以看到ConcurrentHashMap 没有实现懒惰初始化,空间占用不友好
其中 this.segmentShift 和 this.segmentMask的作用是决定将key的hash结果匹配到那个 segment
例如 :根据某一hash值求segment位置,先将高位向低位移动 this.segmentShift位
结果再与this.segmentMask 做位于运算,最终得到1010即下标为10的segment
put流程
segment继承了可重入锁(ReentrantLock),它的put方法为

get流程
get时并未加锁,用了UNSAFE方法保证了可见性,扩容过程中,get先发生就从旧表取内容,get后发生就从新表取内容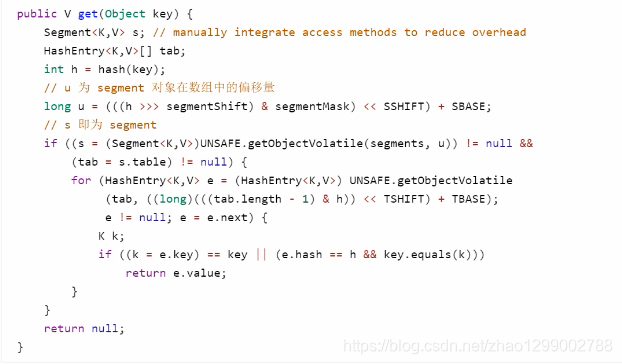
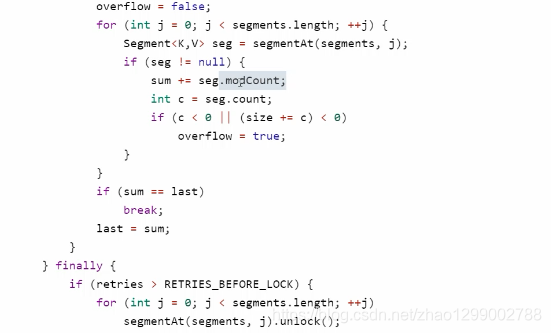
size计算流程 - 计算元素个数前,先不加锁计算两次,如果前后两次结果如一样,认为个数正确返回
- 如果不一样,进行重试,重试次数超过3,将所有segment锁住,重新计算个数返回


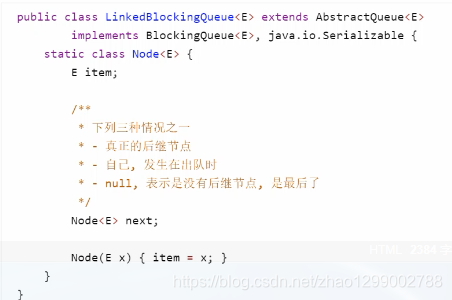
LinkedBlockingQueue 原理
- 基本的入队出队
初始化链表 last = head = new Node(null);Dummy节点用来占位,item为null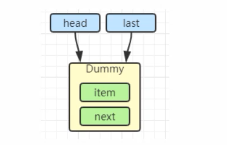
当一个节点入队 last = last.next = node;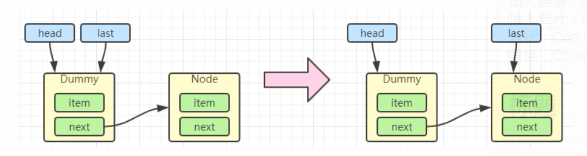
再来一个节点入队 last = last.next = node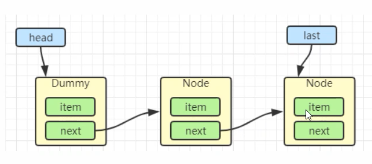
出队
h = head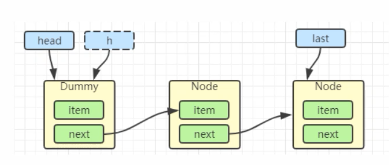
first = h.next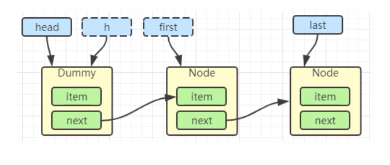
h.next = h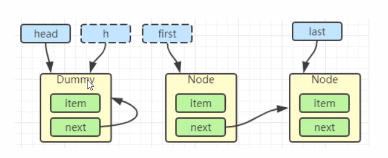
head = first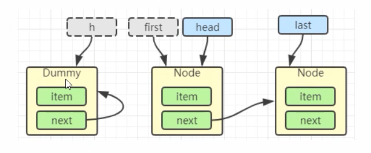
E x = first.item;
first.item = null;
return x;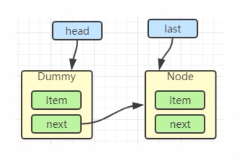
- 加锁分析
高明之处在于用了两把锁和dummy节点
- 用一把锁,同一时刻,最多只允许有一个线程(生产者或消费者,二选一)执行
- 用两把锁,同一时刻,可以允许两个线程同时(一个生产者与一个消费者)执行
- 消费者与消费者线程任然串行
- 生产者与生产者线程任然串行
线程安全分析
- 当节点总数大于2时(包括dummy节点),putLock保证的是last节点的线程安全,takeLock保证的是head节点的线程安全。两把锁保证了入队和出队没有竞争
- 当节点总数等于2时(即一个dummy节点,一个正常节点)这时候,仍然是两把锁锁两个对象,不会竞争
- 当节点总数等于1时(就一个dummy节点)这时take线程会被notEmpty条件阻塞,有竞争,会阻塞

put操作
take操作
主要列举 LinkedBlockingQueue与ArrayBlockingQueue的性能比较
- Linked支持有界,Array强制有界
- Linked实现是链表,Array实现是数组
- Linked是懒惰的,而Array需要提前初始化Node数组
- Linked每次入队会生成新Node,而Array的Node是提前创建好的
- Linked两把锁,Array一把锁
ConcurrentLinkedQueue的设计与LinkedBlockingQueue 非常像,也是
- 两把【锁】,同一时刻,可以允许两个线程同时(一个生产者与一个消费者)执行
- dummy节点的引入让两把【锁】将来锁住的是不同对象,避免竞争
- 只是这【锁】使用了cas来实现
事实上,ConcurrentLinkedQueue应用还是非常广泛的
例如之前讲的Tomcat的Connector结构时,Acceptor作为生产者向Poller消费者传递事件信息时,正是采用了ConcurrentLinkedQueue将SocketChannel给Poller使用
CopyOnWriteArraySet 是它的马甲
底层实现采用了写入时拷贝的思想,增删改操作会将底层数组拷贝一份,更改操作在新数组上执行,这时不影响其他线程的并发读、读写分离。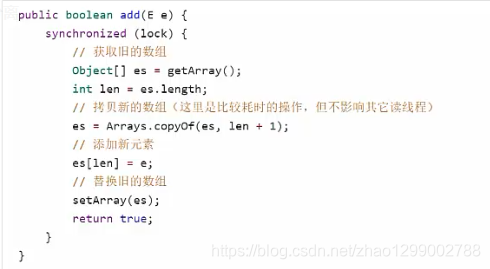
这里的源码版本是Java11,在Java1.8中使用的是可重入锁而不是synchronized,其它读操作并未加锁,例如 :
适合【读多写少】的应用场景
get弱一致性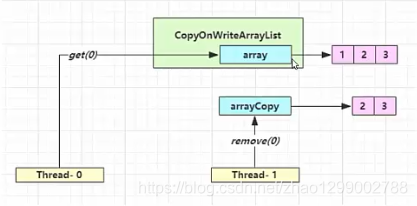
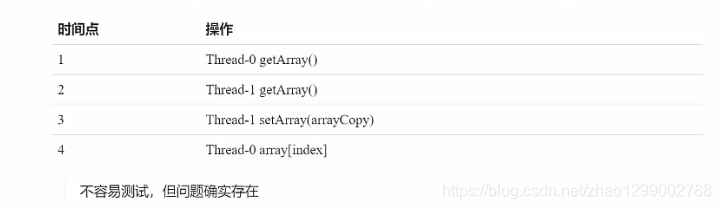
迭代器弱一致性
不要觉得弱一致性就不好
- 数据库的MVCC都是弱一致性的表现
- 并发高和一致性是矛盾的,需要权衡
以上是关于并发编程之J.U.C的第二篇的主要内容,如果未能解决你的问题,请参考以下文章