Scrapy库
Posted motoharu
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了Scrapy库相关的知识,希望对你有一定的参考价值。
一、Scrapy爬虫框架
1、‘5+2’结构:5个模块+2个中间键
5个模块
1) Spider【用户配置】:
- 框架入口,获取初始爬取请求
- 提供要爬取的url链接,同时解析页面上的内容
- 解析Downloader返回的响应(Response)
- 产生爬取项(Scraped Item)
- 产生额外的爬取请求(Request)
2) Engine【已有实现】
- 控制各模块数据流,不断从Scheduler获得爬取请求,直到请求为空
- 根据条件触发事件
3) Scheduler【已有实现】
- 对所有爬取请求进行调度管理
4) Downloader【已有实现】
- 根据请求下载网页
5) Item Pipeline【用户配置】:
- 框架出口,输出爬取项
- 对提取的信息进行后处理
- 以流水线方式处理Spider产生的爬取项(Scraped Item)
- 由一组操作顺序组成,每个操作是一个Item Pipeline类型
- 清理、检验、查重爬取项中的HTML数据、将数据存储到数据库
2个中间键:Engine和Spider、Downloader之间存在中间键:
1) Downloader Middleware【用户配置】
- 实施Engine、Scheduler、Downloader之间进行用户可配置的控制
- 修改、丢弃、新增请求或响应
2) Spider Middleware【用户配置】
- 对请求和爬取项的再处理
- 修改、丢弃、新增请求或爬取项
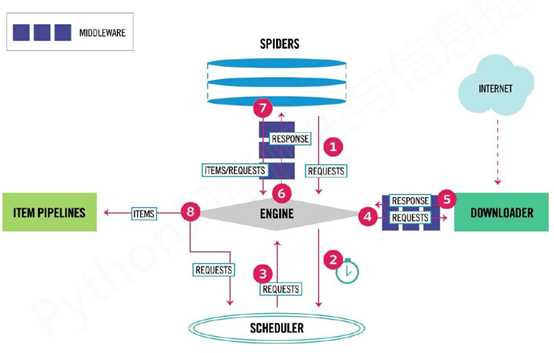
2、3条数据流
1) Engine从Spider获得爬取请求(Request-url)
2) Engine再将爬取请求(Request)转发给Scheduler,用于调度
3) Engine从Scheduler获得爬取请求(Request)
4) Engine再将爬取请求(Request)通过中间键发送给Downloader
5) Downloader链接Internet爬取网页之后,Downloader形成响应(Response)通过中间键发送给Engine
6) Engine将响应(Response)通过中间键发送给Spider
7) Spider处理响应之后,产生爬取项(Scraped Item)和新的爬取请求(Request)发给Engine
8) Engine将爬取项(Scraped Item)发送给Item Pipeliner
9) Engine将爬取请求(Request) 转发给Scheduler
二、Requests vs. Scrapy
同:
优点:都可以进行页面请求和爬取,可用性好、文档丰富、入门简单
缺点:没有处理JS、提交表单、应对验证码
异:
Requests:
页面级爬虫
功能库
并发性差、性能较差
重点在页面下载
定制灵活,上手简单
Scrapy:
网站级爬虫
爬虫框架
并发性好、性能较高
重点在爬虫结构
一般定制灵活,深度定制困难,上手较难
适用:
Requests:非常小的需求
Scrapy:不太小的需求
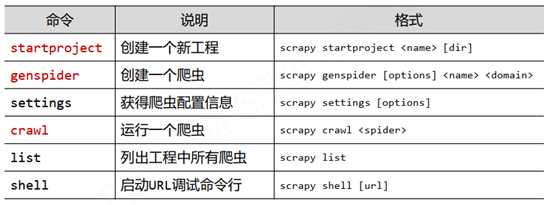
三、Scrapy命令行
>scrapy <command> [options] [args]
四、使用Scrapy库【小例子】
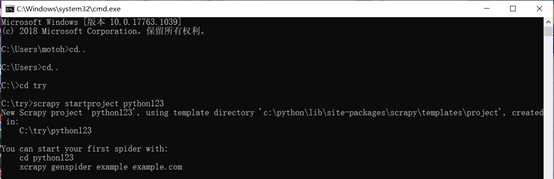
步骤1、 建立一个Scrapy爬虫工程
打开命令行
在C盘的try目录下新建一个工程:python123
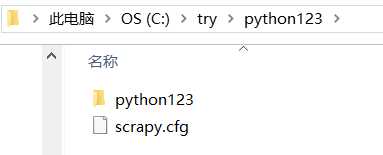
1) python123/ — Scrapy框架的用户自定义python代码
2) scrapy.cfg — 部署Scrapy爬虫的配置文件
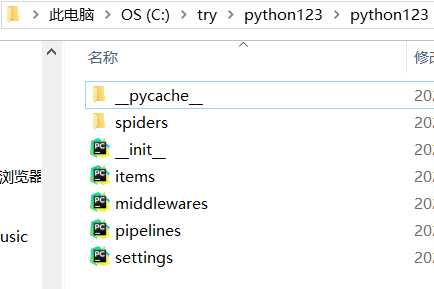
1) __init__.py — 初始化脚本,不需要用户编写
2) items.py — Items代码模板(继承类)
3) middlewares.py — Middleware代码模板(继承类),如需扩展Middleware功能,可以进行修改
4) middlewares.py — Middleware代码模板(继承类)
5) pipelines.py — Pipelines代码模板(继承类)
6) settings.py — Scrapy爬虫的配置文件,优化爬虫功能
7) spiders/ — Spiders代码模板(继承类)
8) __pycache__/ — 缓存目录,无需修改
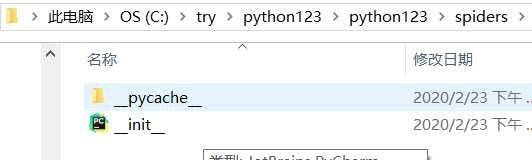
1) __pycache__/ — 缓存目录,无需修改
2) __init__.py — 初始化脚本,不需要用户编写
步骤2、在工程中产生一个爬虫
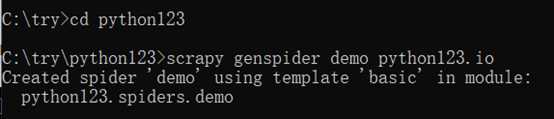
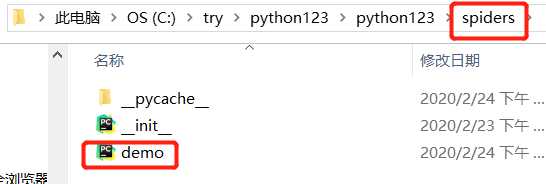
在spiders目录下增加代码文件 demo.py
# -*- coding: utf-8 -*-
import scrapy
#面向对象编写的一个 DemoSpider 类,该类继承于scrapy.Spider面向对象编写的一个 DemoSpider 类,该类继承于scrapy.Spider
class DemoSpider(scrapy.Spider):
name = ‘demo‘
allowed_domains = [‘python123.io‘] ## 只能爬取‘python123.io‘域名下的相关url,生成爬虫时提交
start_urls = [‘http://python123.io/‘] ## 爬取的起始页面
## 解析页面的方法,用于处理响应,解析内容形成字典,发现新的url爬取请求
def parse(self, response):
pass
步骤3、配置产生的spider爬虫,即修改demo.py
# -*- coding: utf-8 -*-
import scrapy
class DemoSpider(scrapy.Spider):
name = ‘demo‘
# allowed_domains = [‘python123.io‘] ## 可选
start_urls = [‘http://python123.io/ws/demo.html‘]
## 解析页面的方法
def parse(self, response): ## 将response内容写入html文件中
fname = response.url.split(‘/‘)[-1]
with open(fname, ‘wb‘) as f:
f.write(response.body)
self.log(‘Saved file %s.‘ % fname)
步骤4、运行爬虫,获取页面,捕获页面存储在demo.html中

五、yeild关键字
包含yeild语句的函数是一个生成器
生成器是一个不断产生值的函数
生成器每次产生一个值(yeild语句),函数被冻结,被唤醒后再产生一个值
于循环结合使用
## yeild 的使用
def gen(n):
for i in range(n):
yield i**2
for i in gen(5):
print(i, ‘‘, end=‘‘)
## 普通写法,将所有值计算出来存在列表中,一次进行返回
def square(n):
ls = [i**2 for i in range(n)]
return ls
for i in square(5):
print(i, ‘‘, end=‘‘)
生成器相比一次列出所有结果的优势【特别对于大规模程序】:
节省存储空间、响应更加迅速、使用灵活
# -*- coding: utf-8 -*-
import scrapy
class DemoSpider(scrapy.Spider):
name = ‘demo‘
# allowed_domains = [‘python123.io‘] ## 可选
def start_requests(self):
urls = [‘http://python123.io/ws/demo.html‘]
for url in urls:
yield scrapy.Request(url=url, callback=self.parse)
## 解析页面的方法
def parse(self, response): ## 将response内容写入html文件中
fname = response.url.split(‘/‘)[-1]
with open(fname, ‘wb‘) as f:
f.write(response.body)
self.log(‘Saved file %s.‘ % fname)
六、Scrapy爬虫的使用
1、创建一个工程和Spider模板
2、编写Spider
3、编写Item Pipeliner
4、优化配置策略
七、Scrapy爬虫的数据类型
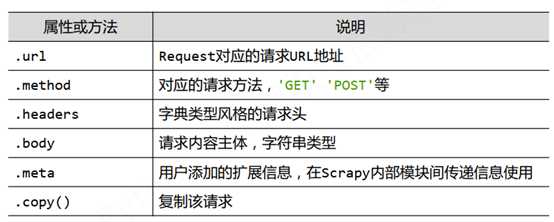
1、Request类:向网络提交HTTP请求
由Spider生成,Download执行
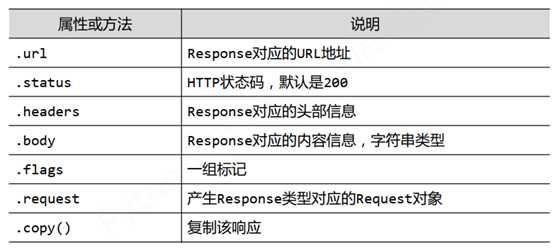
2、Response类:爬取内容的封装类,HTTP响应
由Download生成,Spider处理
3、Item类:充HTML页面中提取的信息
由Spider生成,Item Pipeliner处理
类似字典类型
八、 Scrapy爬虫信息提取方法【Spider模块使用】
Beautiful Soup
Re
lxlm
Xpath Selector
CSS Selector
以上是关于Scrapy库的主要内容,如果未能解决你的问题,请参考以下文章