全文检索Lucene框架---查询索引
Posted zzzzn
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了全文检索Lucene框架---查询索引相关的知识,希望对你有一定的参考价值。
一、 Lucene索引库查询
对要搜索的信息创建Query查询对象,Lucene会根据Query查询对象生成最终的查询语法,类似关系数据库Sql语法一样Lucene也有自己的查询语法,比如:“name:lucene”表示查询Field的name为“lucene”的文档信息。
可通过两种方法创建查询对象:
1)使用Lucene提供Query子类
2)使用QueryParse解析查询表达式
二、 TermQuery
TermQuery,通过项查询,TermQuery不使用分析器所以建议匹配不分词的Field域查询,比如订单号、分类ID号等。
指定要查询的域和要查询的关键词。
1、代码实现
package com.zn; import org.apache.lucene.document.Document; import org.apache.lucene.index.DirectoryReader; import org.apache.lucene.index.IndexReader; import org.apache.lucene.index.Term; import org.apache.lucene.search.*; import org.apache.lucene.store.Directory; import org.apache.lucene.store.FSDirectory; import org.junit.jupiter.api.Test; import java.io.File; import java.io.IOException; /** * 查询索引 */ public class QueryTest { /** * 根据域或关键词进行搜索 */ @Test public void termQuery() throws IOException { Directory directory= FSDirectory.open(new File("E:accpY2进阶内容LuceneLuceneIndex").toPath()); IndexReader indexReader= DirectoryReader.open(directory); IndexSearcher indexSearcher=new IndexSearcher(indexReader); //创建查询条件 Query query=new TermQuery(new Term("fieldName","spring")); //执行查询 TopDocs topDocs=indexSearcher.search(query,10); System.out.println("返回的文档个数:"+topDocs.totalHits); //获取到文档集合 ScoreDoc [] scoreDocs=topDocs.scoreDocs; for (ScoreDoc doc:scoreDocs) { //获取到文档 Document document = indexSearcher.doc(doc.doc); //获取到文档域中数据 System.out.println("fieldName:"+document.get("fieldName")); System.out.println("fieldPath:"+document.get("fieldPath")); System.out.println("fieldSize:"+document.get("fieldSize")); System.out.println("fieldContent:"+document.get("fieldContent")); System.out.println("=============================================================="); } //关闭 indexReader.close(); } }
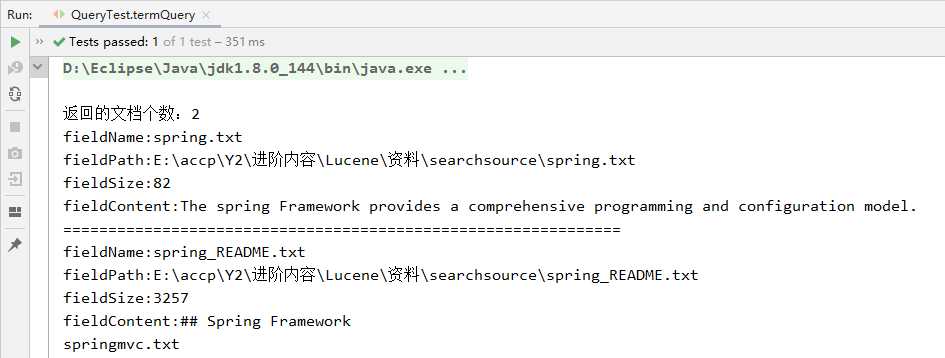
2、查询效果
三、 RangeQuery数值查询
1、代码实现
package com.zn; import org.apache.lucene.document.Document; import org.apache.lucene.document.LongPoint; import org.apache.lucene.index.DirectoryReader; import org.apache.lucene.index.IndexReader; import org.apache.lucene.index.Term; import org.apache.lucene.search.*; import org.apache.lucene.store.Directory; import org.apache.lucene.store.FSDirectory; import org.junit.jupiter.api.Test; import java.io.File; import java.io.IOException; /** * 查询索引 */ public class QueryTest { /** * RangeQuery:范围搜索 */ @Test public void rangeQuery() throws IOException { Directory directory= FSDirectory.open(new File("E:accpY2进阶内容LuceneLuceneIndex").toPath()); IndexReader indexReader= DirectoryReader.open(directory); IndexSearcher indexSearcher=new IndexSearcher(indexReader); //创建查询条件 //设置范围搜索的条件 参数一范围所在的域 Query query= LongPoint.newRangeQuery("fieldSize",0,50); //查询 TopDocs topDocs = indexSearcher.search(query, 10); System.out.println("返回的文档个数:"+topDocs.totalHits); //获取到文档集合 ScoreDoc [] scoreDocs=topDocs.scoreDocs; for (ScoreDoc doc:scoreDocs) { //获取到文档 Document document = indexSearcher.doc(doc.doc); //获取到文档域中数据 System.out.println("fieldName:"+document.get("fieldName")); System.out.println("fieldPath:"+document.get("fieldPath")); System.out.println("fieldSize:"+document.get("fieldSize")); System.out.println("fieldContent:"+document.get("fieldContent")); System.out.println("=============================================================="); } //关闭 indexReader.close(); } }
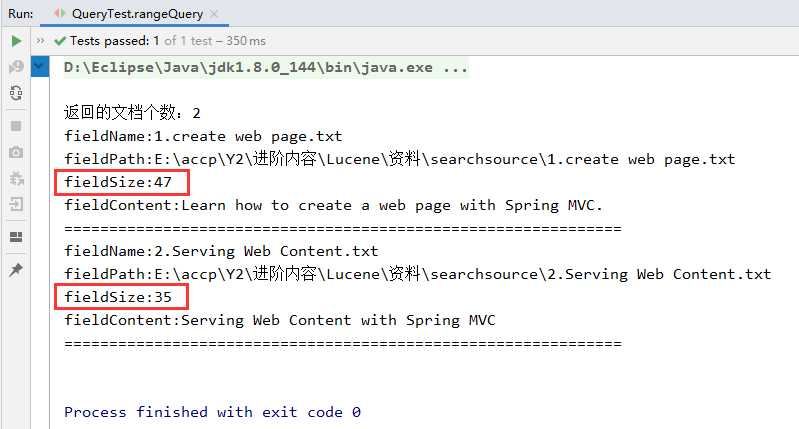
2、查询效果
四、 QueryParser
通过QueryParser也可以创建Query,QueryParser提供一个Parse方法,此方法可以直接根据查询语法来查询。Query对象执行的查询语法可通过System.out.println(query);查询。
需要使用到分析器。建议创建索引时使用的分析器和查询索引时使用的分析器要一致。
需要加入queryParser依赖的jar包。
1、导入依赖
<!-- https://mvnrepository.com/artifact/org.apache.lucene/lucene-queryparser --> <dependency> <groupId>org.apache.lucene</groupId> <artifactId>lucene-queryparser</artifactId> <version>7.4.0</version> </dependency>
2、代码实现
package com.zn; import org.apache.lucene.document.Document; import org.apache.lucene.document.LongPoint; import org.apache.lucene.index.DirectoryReader; import org.apache.lucene.index.IndexReader; import org.apache.lucene.index.Term; import org.apache.lucene.queryparser.classic.ParseException; import org.apache.lucene.queryparser.classic.QueryParser; import org.apache.lucene.search.*; import org.apache.lucene.store.Directory; import org.apache.lucene.store.FSDirectory; import org.junit.jupiter.api.Test; import org.wltea.analyzer.lucene.IKAnalyzer; import java.io.File; import java.io.IOException; /** * 查询索引 */ public class QueryTest { /** * QueryParser:将搜索条件分词 */ @Test public void queryParser() throws IOException, ParseException { Directory directory= FSDirectory.open(new File("E:accpY2进阶内容LuceneLuceneIndex").toPath()); IndexReader indexReader= DirectoryReader.open(directory); IndexSearcher indexSearcher=new IndexSearcher(indexReader); //创建QueryParser对象 参数一范围所在的域 参数二:使用哪种分析器 QueryParser parser=new QueryParser("fieldContent",new IKAnalyzer()); //设置匹配的数据条件 Query query = parser.parse("新添加的文档的内容"); //查询 TopDocs topDocs = indexSearcher.search(query, 10); System.out.println("返回的文档个数:"+topDocs.totalHits); //获取到文档集合 ScoreDoc [] scoreDocs=topDocs.scoreDocs; for (ScoreDoc doc:scoreDocs) { //获取到文档 Document document = indexSearcher.doc(doc.doc); //获取到文档域中数据 System.out.println("fieldName:"+document.get("fieldName")); System.out.println("fieldPath:"+document.get("fieldPath")); System.out.println("fieldSize:"+document.get("fieldSize")); System.out.println("fieldContent:"+document.get("fieldContent")); System.out.println("=============================================================="); } //关闭 indexReader.close(); } }
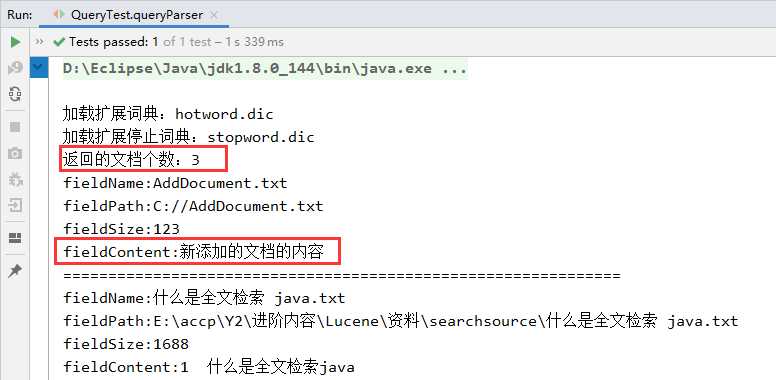
3、效果展示
以上是关于全文检索Lucene框架---查询索引的主要内容,如果未能解决你的问题,请参考以下文章