zooKeeper集群搭建
Posted ssyfj
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了zooKeeper集群搭建相关的知识,希望对你有一定的参考价值。
一:什么是ZooKeeper
Zookeeper 是 Google 的 Chubby一个开源的实现,是 Hadoop 的分布式协调服务
它包含一个简单的原语集,分布式应用程序可以基于它实现同步服务,配置维护和命名服务等
(一)原始架构
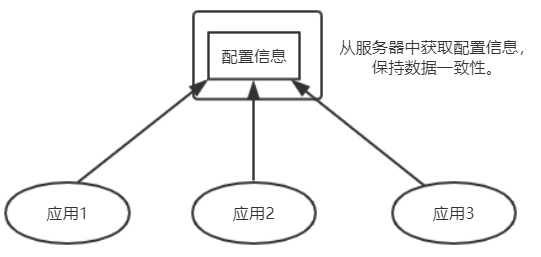
但是当服务器宕机,则应用全部瘫痪。无法做到高可用。应该使用集群实现数据同步和高可用功能
(二)ZooKeeper集群实现
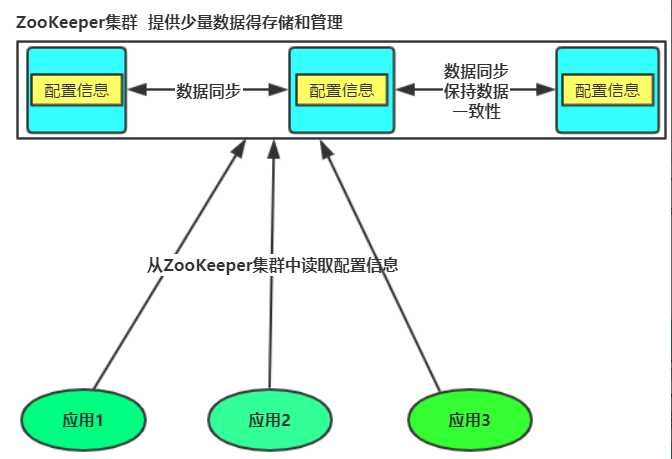
zookeeper集群中,只要有一半以上得节点存活,则该集群可以正常工作。
除了提供少量数据的存储和管理功能外,还提供对数据节点的监听器。只要是该数据在集群中发生了变化,对该数据注册了监听器的客户端,就可以得到通知。
(三)zookeeper节点角色划分
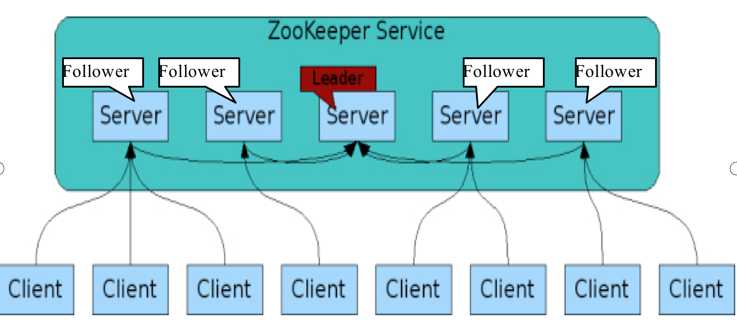
leader为主节点,当客户端向集群中写入数据时,由leader节点进行数据写入,并通知其他follower节点进行数据读取同步。只要当集群节点中有超过一般节点数据更新成功则leader节点认为更新任务成功。
角色的选取,在节点启动之后(或者leader挂了),由选举机制决策出哪一个是leader。其他则为follower
(三)Zookeeper使用场景
大部分分布式应用需要一个主控、协调器或控制器来管理物理分布的子进程(如资源、任务分配等)
目前,大部分应用需要开发私有的协调程序,缺乏一个通用的机制
协调程序的反复编写浪费,且难以形成通用、伸缩性好的协调器
ZooKeeper:提供通用的分布式锁服务,用以协调分布式应用
二:集群所用机器克隆---链接克隆
(一)进行系统克隆
步骤一:选择克隆状态
注意:当前状态防火墙已经是关闭了,所以后面不用管防火墙了
步骤二:选择克隆类型
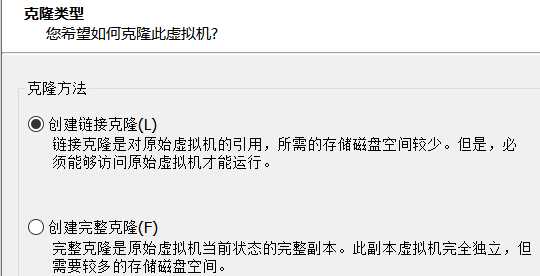
其中两者类型都可以,但是完整克隆占用大量空间,不推荐,使用链接克隆即可
(二)配置各个节点的ip和主机名
由于我们由原来主机中克隆而来(所以我们的ip都是同原来主机一样,主机名也是),都需要修改。值得一提:克隆出来的主机mac地址是不一样的,可以用ifconfig查看
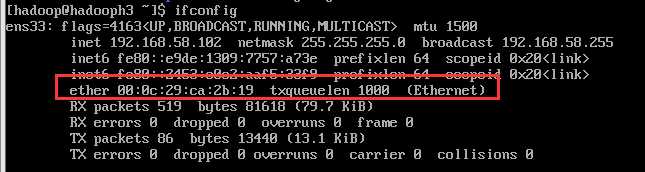
防火墙也是同样关闭的:

1.配置ip地址
ip addr 查看ip地址
vi /etc/sysconfig/network-scripts/ifcfg-ens33
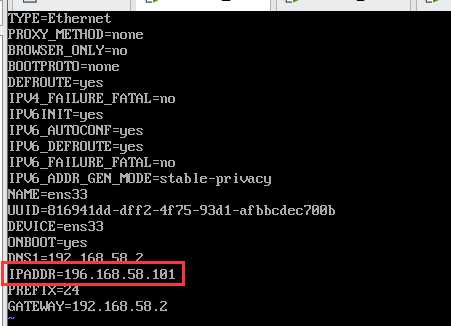
2.配置主机名
hostnamectl set-hostname hadoopH2 其他主机名设置为hadoopH3、hadoopH4
三:zookeeper集群搭建
(一)下载zookeeper
http://archive.apache.org/dist/zookeeper/
(二)zookeeper配置
1.进入配置目录
apache-zookeeper-3.5.6-bin/conf

2.将原有zoo_smaple.cfg改为zoo.cfg文件
mv zoo_sample.cfg ./zoo.cfg
3.配置文件修改
# The number of milliseconds of each tick tickTime=2000 //心跳间隔(用于集群各节点之间状态检测) 2秒 # The number of ticks that the initial # synchronization phase can take initLimit=10 //启动集群最大时间(开始和结束时间)最大间隔心跳数,若是超过则任务后面的节点启动失败 # The number of ticks that can pass between # sending a request and getting an acknowledgement syncLimit=5 //请求和响应之间最大心跳 # the directory where the snapshot is stored. # do not use /tmp for storage, /tmp here is just # example sakes. dataDir=/tmp/zookeeper //zookeeper用于保存数据的本地目录,建用修改,不要使用默认这个目录(用因为系统重启,tmp目录会清空),可以修改为应用根目录下data子目录 # the port at which the clients will connect clientPort=2181 //提供连接端口给客户端使用 # the maximum number of client connections. # increase this if you need to handle more clients #maxClientCnxns=60 # # Be sure to read the maintenance section of the # administrator guide before turning on autopurge. # # http://zookeeper.apache.org/doc/current/zookeeperAdmin.html#sc_maintenance # # The number of snapshots to retain in dataDir #autopurge.snapRetainCount=3 # Purge task interval in hours # Set to "0" to disable auto purge feature #autopurge.purgeInterval=1
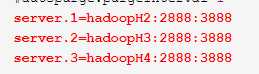
server.1=hadoopH2:2888:3888
server.2=hadoopH3:2888:3888
server.3=hadoopH4:2888:3888
重点:集群中机器信息需要在配置文件中配置出来
server.id=主机名:端口<leader和follower节点通信端口>:端口<用于节点选举>
其中id必须唯一
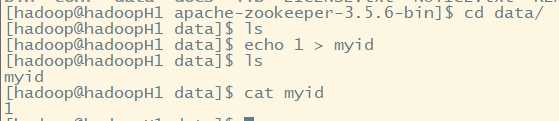
4.创建datadir目录


5.在datadir目录下创建myid信息文件
注意:对于不同机器设置不同内容在myid文件
按照主机名配置,在hadoopH2主机写入myid内容为1,hadoopH3写入2....
补充:注意配置hosts文件 vi /etc/hosts

补充:可以使用scp命令传递文件在各机器中
scp -r ./apache-zookeeper-3.5.6-bin hadoopH2:/home/hadoop/App/
传递文件夹到hadoopH2主机中
(三)启动zookeeper集群
1.对每台机器启动zookeeper服务(进入bin目录)
./zkServer.sh start

2.查看zookeeper集群状态
./zkServer.sh status

只有当启动的机器数目大于集群设置数量的一半时,集群才可以正常启动。此时启动一个机器,所以集群无法启动
补充:Zookeeper启动成功,zkServer.sh status 报错
3.查看集群状态及角色



4.本地(使用集群内部节点)测试客户端
./zkCli.sh
四:zookeeper客户端命令查看
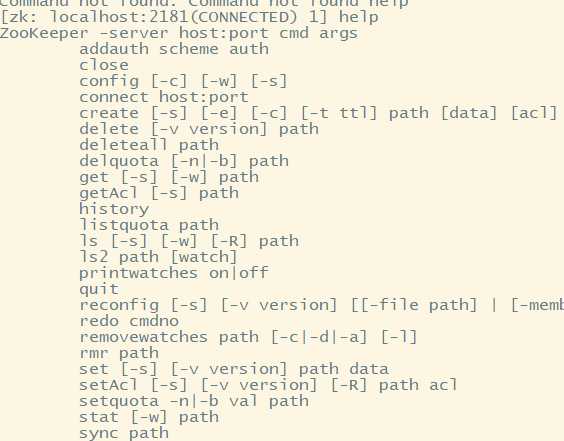
(一)查看全部命令
(二)ls查看节点信息
(三)建立节点,写入数据
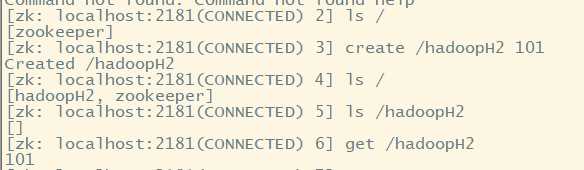
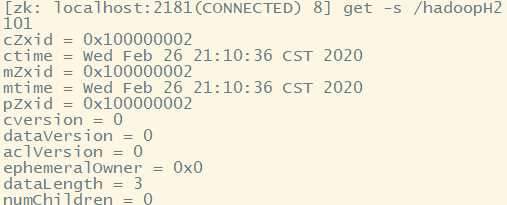
可以查看状态信息
五:zookeeper文件存储结构
(一)数据存储结构
zookeeper管理客户所存放的数据采用的是类似与文件树的结构
层次化的目录结构,命名符合常规文件系统规范
每个节点在zookeeper中叫做znode,并且其有一个唯一的路径标识
节点Znode可以包含数据和子节点,但是EPHEMERAL类型的节点不能有子节点
Znode中的数据可以有多个版本,比如某一个路径下存有多个数据版本,那么查询这个路径下的数据就需要带上版本
客户端应用可以在节点上设置监视器
节点不支持部分读写,而是一次性完整读写
每个数据存放大小最好小于1M
补充:集群节点之间数据同步需要时间极短(可用于分布式系统实时性操作),节点之间状态检测需要按照配置文件设置的2秒
六:zookeeper节点
(一)Znode有两种类型,短暂的(ephemeral)和持久的(persistent)
短暂znode的客户端会话结束时,zookeeper会将该短暂znode删除,短暂znode不可以有子节点
持久znode不依赖于客户端会话,只有当客户端明确要删除该持久znode时才会被删除
(二)Znode的类型在创建时确定并且之后不能再修改
(三)Znode有四种形式的目录节点
PERSISTENT、PERSISTENT_SEQUENTIAL、EPHEMERAL、EPHEMERAL_SEQUENTIAL
七:zookeeper的全部角色
(一)领导者(leader)
负责进行投票的发起和决议,更新系统状态
(二)学习者(learner)
包括跟随者(follower)和观察者(observer)
1.follower跟随者
follower用于接受客户端请求并想客户端返回结果,在选主过程中参与投票
2.observer观察者
Observer可以接受客户端连接,将写请求转发给leader,但observer不参加投票过程,只同步leader的状态,observer的目的是为了扩展系统,提高读取速度
(三)客户端
请求发起方
八:监听器实现---观察(watcher)
(一)概念
Watcher 在 ZooKeeper 是一个核心功能,Watcher 可以监控目录节点的数据变化以及子目录的变化,一旦这些状态发生变化,服务器就会通知所有设置在这个目录节点上的 Watcher,从而每个客户端都很快知道它所关注的目录节点的状态发生变化,而做出相应的反应
可以设置观察的操作:exists,getChildren,getData
可以触发观察的操作:create,delete,setData
(二)事件对应

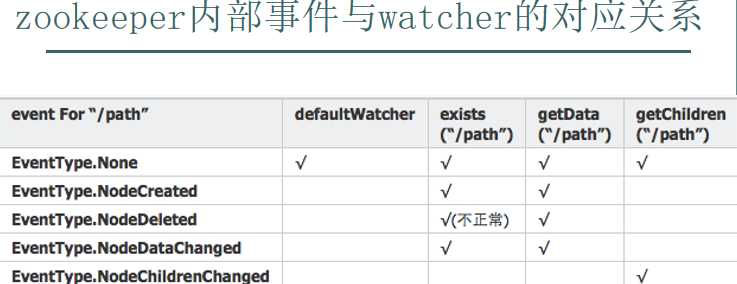
以上可以知道:
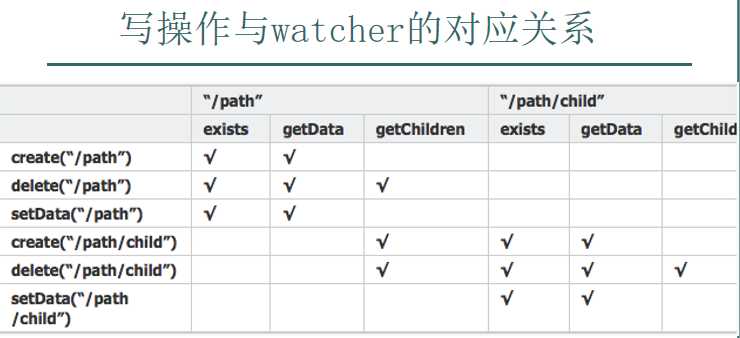
九:应用场景
(一)命名服务
Name Service 是 Zookeeper 内置的功能,只要调用 Zookeeper 的 API 就能实现
分布式应用中,通常需要有一套完整的命名规则,既能够产生唯一的名称又便于人识别和记住,通常情况下用树形的名称结构是一个理想的选择,树形的名称结构是一个有层次的目录结构,既对人友好又不会重复。
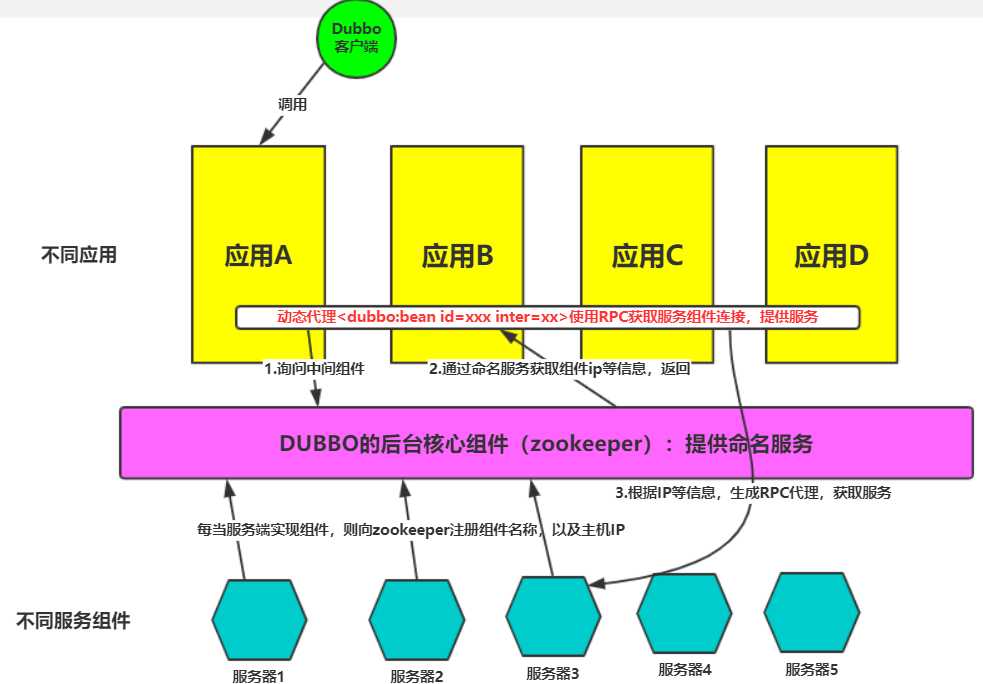
同样,可以利用该框架实现负载均衡
(二)配置管理---利用监听器实现
1.背景
配置的管理在分布式应用环境中很常见,例如同一个应用系统需要多台 PC Server 运行,但是它们运行的应用系统的某些配置项是相同的,如果要修改这些相同的配置项,那么就必须同时修改每台运行这个应用系统的 PC Server,这样非常麻烦而且容易出错。
2.解决方案
将配置信息保存在 Zookeeper 的某个目录节点中,然后将所有需要修改的应用机器监控配置信息的状态,一旦配置信息发生变化,每台应用机器就会收到 Zookeeper 的通知,然后从 Zookeeper 获取新的配置信息应用到系统中。
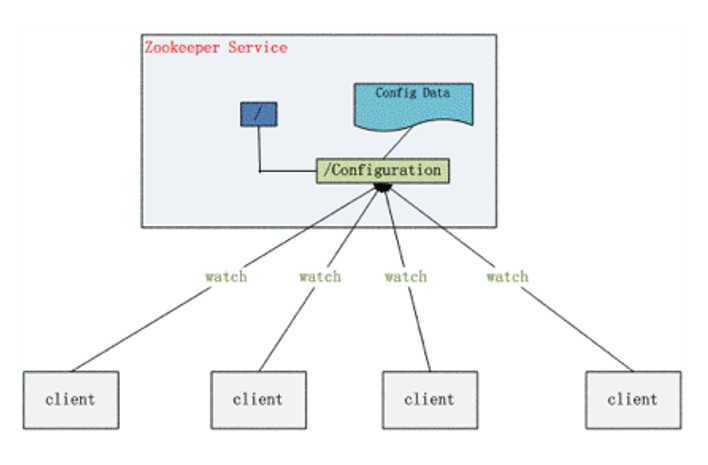
(三)集群管理
Zookeeper 能够很容易的实现集群管理的功能,
如有多台 Server 组成一个服务集群,那么必须要一个“总管”知道当前集群中每台机器的服务状态,
一旦有机器不能提供服务,集群中其它集群必须知道,从而做出调整重新分配服务策略。
同样当增加集群的服务能力时,就会增加一台或多台 Server,同样也必须让“总管”知道。
Zookeeper 不仅能够维护当前的集群中机器的服务状态,而且能够选出一个“总管”,让这个总管来管理集群,这就是 Zookeeper 的另一个功能 Leader Election。
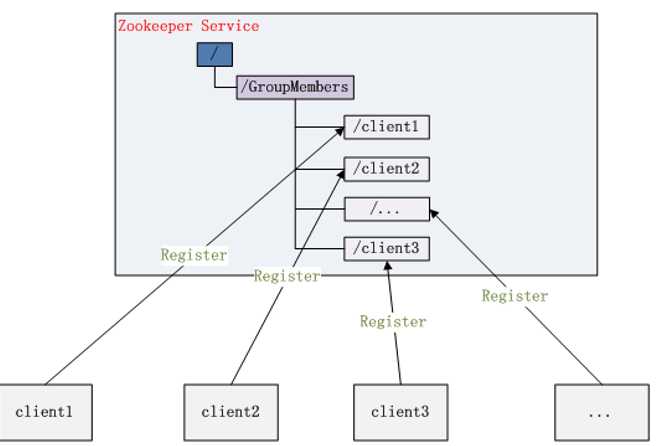
规定编号最小的为master,所以当我们对SERVERS节点做监控的时候,得到服务器列表,只要所有集群机器逻辑认为最小编号节点为master,那么master就被选出,而这个master宕机的时候,相应的znode会消失(短暂连接),然后新的服务器列表就被推送到客户端,然后每个节点逻辑认为最小编号节点为master,这样就做到动态master选举。
(四)共享锁
共享锁在同一个进程中很容易实现,但是在跨进程或者在不同 Server 之间就不好实现了。Zookeeper 却很容易实现这个功能,实现方式也是需要获得锁的 Server 创建一个 EPHEMERAL_SEQUENTIAL 目录节点,然后调用 getChildren方法获取当前的目录节点列表中最小的目录节点是不是就是自己创建的目录节点,如果正是自己创建的,那么它就获得了这个锁,如果不是那么它就调用 exists(String path, boolean watch) 方法并监控 Zookeeper 上目录节点列表的变化,一直到自己创建的节点是列表中最小编号的目录节点,从而获得锁,释放锁很简单,只要删除前面它自己所创建的目录节点就行了
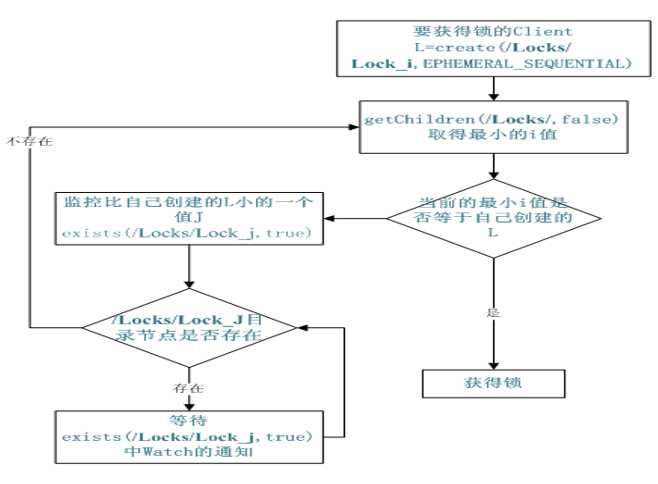
(五)队列管理
Zookeeper 可以处理两种类型的队列:
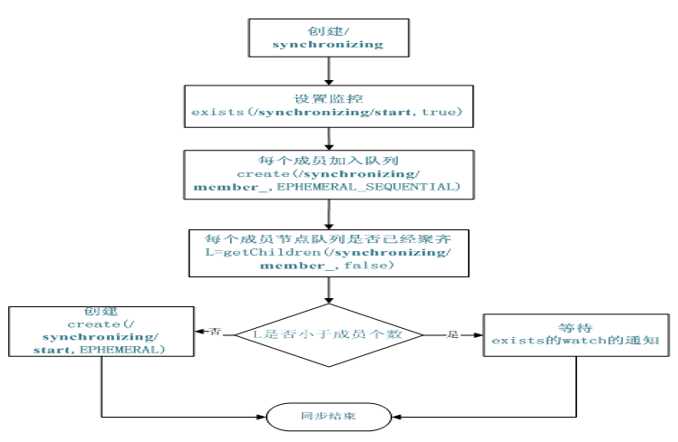
当一个队列的成员都聚齐时,这个队列才可用,否则一直等待所有成员到达,这种是同步队列;
队列按照 FIFO 方式进行入队和出队操作,例如实现生产者和消费者模型
创建一个父目录 /synchronizing,每个成员都监控目录 /synchronizing/start 是否存在,然后每个成员都加入这个队列(创建 /synchronizing/member_i 的临时目录节点),然后每个成员获取 / synchronizing 目录的所有目录节点,判断 i 的值是否已经是成员的个数,如果小于成员个数等待 /synchronizing/start 的出现,如果已经相等就创建 /synchronizing/start
以上是关于zooKeeper集群搭建的主要内容,如果未能解决你的问题,请参考以下文章