循环神经网络-语言模型
Posted siyuan-jin
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了循环神经网络-语言模型相关的知识,希望对你有一定的参考价值。
在构建语言模型中,我们需要理解n元模型以及网络架构。
一、 n元语法
n元语法通过马尔可夫假设简化模型,马尔科夫假设是指一个词的出现只与前面n个词相关,即n阶马尔可夫链(Markov chain of order n)。
来看以下几个例子,下面分别是1元,2元,3元语法模型的结果。
$Pleft(w_{1}, w_{2}, w_{3}, w_{4}
ight)=Pleft(w_{1}
ight) Pleft(w_{2}
ight) Pleft(w_{3}
ight) Pleft(w_{4}
ight)$
$Pleft(w_{1}, w_{2}, w_{3}, w_{4}
ight)=Pleft(w_{1}
ight) Pleft(w_{2} | w_{1}
ight) Pleft(w_{3} | w_{2}
ight) Pleft(w_{4} | w_{3}
ight)$
$Pleft(w_{1}, w_{2}, w_{3}, w_{4}
ight)=Pleft(w_{1}
ight) Pleft(w_{2} | w_{1}
ight) Pleft(w_{3} | w_{1}, w_{2}
ight) Pleft(w_{4} | w_{2}, w_{3}
ight)$
事实上,我们只需要了解n元语法的意义便可,并不需要做更加细致的探讨。
$Pleft(w_{1}, w_{2}, dots, w_{T} ight)=prod_{t=1}^{T} Pleft(w_{t} | w_{t-(n-1)}, dots, w_{t-1} ight)$
对于语言模型,我们所用的则是n-1元语法,意味着当我们预测第n的字的时候,我们是基于前n-1个词进行判断的。
二、 网络架构
以下便是语言模型的网络架构,可以看到我们这里只是输入了一个字符x<1>,后续的输入均是上一步的输出y得出的。
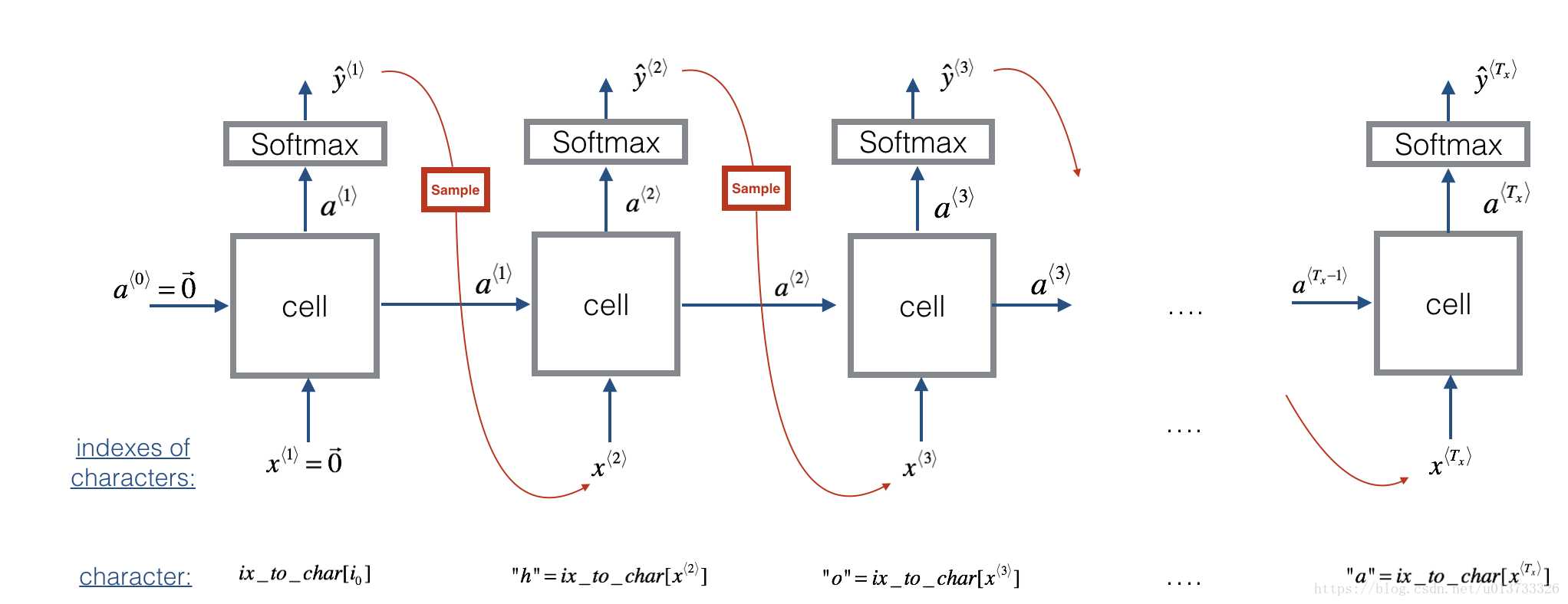
根据这个模型,我们可以让模型自动生成文本,这也就是之前网络中流行的傻瓜论文,歌词谱写等的模型原型。
三、 梯度裁剪
由于循环神经网络的深度非常大,因此我们需要考虑解决梯度爆炸的问题。常用的方法则是梯度裁剪。梯度裁剪是一种常用解决梯度爆炸的方法,即当梯度超过一定大小时,梯度自动取该阈值。
模型在梯度下降的过程中,始终不会超过该阈值。
以上是关于循环神经网络-语言模型的主要内容,如果未能解决你的问题,请参考以下文章