jenkins pipeline持续集成
Posted xiao987334176
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了jenkins pipeline持续集成相关的知识,希望对你有一定的参考价值。
一、概述
简介
Jenkins 2.x的精髓是Pipeline as Code,那为什么要用Pipeline呢?jenkins1.0也能实现自动化构建,但Pipeline能够将以前project中的配置信息以steps的方式放在一个脚本里,将原本独立运行于单个或者多个节点的任务连接起来,实现单个任务难以完成的复杂流程,形成流水式发布,构建步骤视图化。简单来说,Pipeline适用的场景更广泛,能胜任更复杂的发布流程。举个例子,job构建工作在master节点,自动化测试脚本在slave节点,这时候jenkins1.0就无法同时运行两个节点,而Pipeline可以。
基本概念
Stage: 阶段,一个Pipeline可以划分为若干个Stage,每个Stage代表一组操作。注意,Stage是一个逻辑分组的概念,可以跨多个Node。
Node: 节点,一个Node就是一个Jenkins节点,或者是Master,或者是slave,是执行Step的具体运行期环境。
Step: 步骤,Step是最基本的操作单元,小到创建一个目录,大到构建一个Docker镜像,由各类Jenkins Plugin提供。
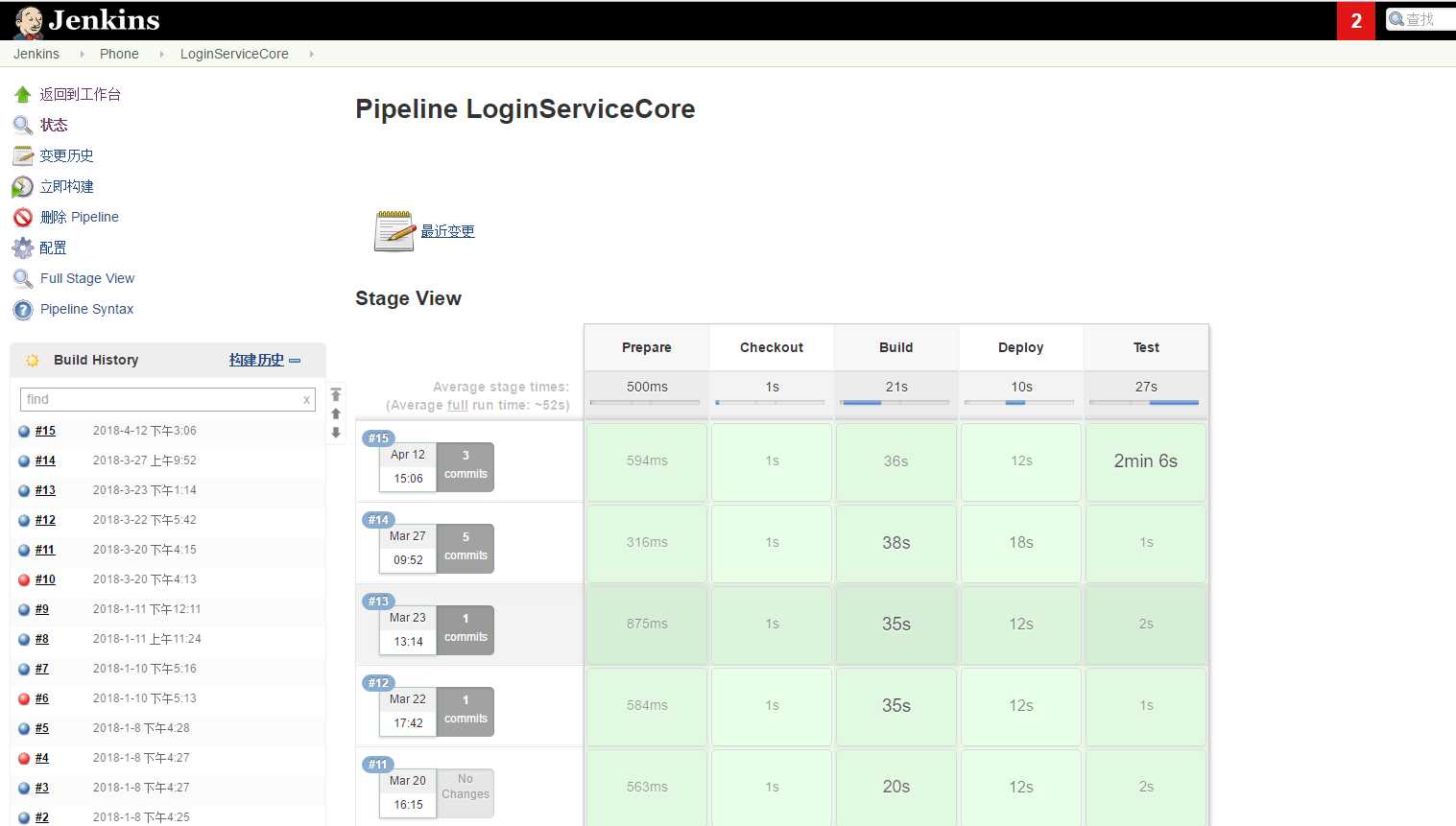
语法
Pipeline支持两种语法:Declarative Pipeline(在Pipeline 2.5中引入,结构化方式)和Scripted Pipeline,两者都支持建立连续输送的Pipeline。
共同点:
两者都是pipeline代码的持久实现,都能够使用pipeline内置的插件或者插件提供的steps,两者都可以利用共享库扩展。
区别:
两者不同之处在于语法和灵活性。Declarative pipeline对用户来说,语法更严格,有固定的组织结构,更容易生成代码段,使其成为用户更理想的选择。但是Scripted pipeline更加灵活,因为Groovy本身只能对结构和语法进行限制,对于更复杂的pipeline来说,用户可以根据自己的业务进行灵活的实现和扩展。
本文主要采取Scripted Pipeline语法
二、项目实战
环境介绍
环境参考链接:
https://www.cnblogs.com/xiao987334176/p/12344871.html
这里面,主要是通过jenkins将Spring Cloud项目发布到一台服务器。
利用了参数化构建,一个jenkins job同时支持发布和回滚。
另外还设置了回滚时,跳过构建,参考链接:
https://www.cnblogs.com/xiao987334176/p/12357007.html
pipeline方式
如果要改成pipeline方式,需要新建一个jenkins job,名字为:test_pipeline_eureka-server
基本设置
参数化构建

pipeline脚本
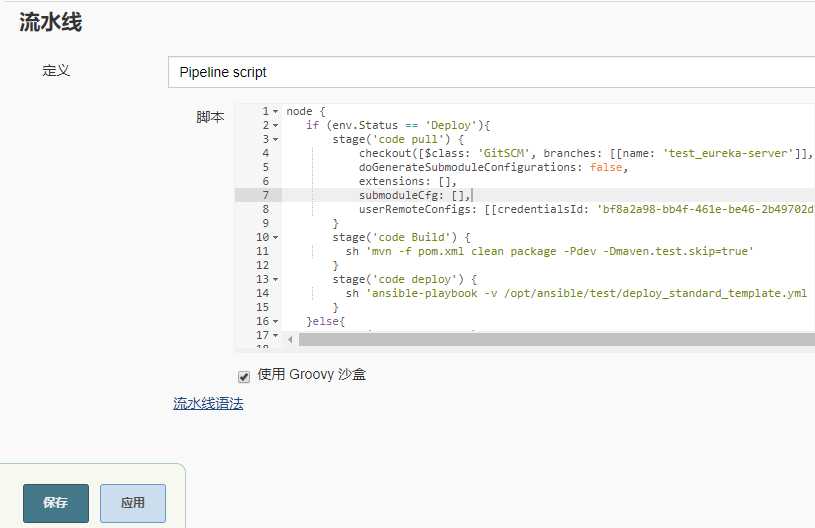
完整代码如下:
node { if (env.Status == ‘Deploy‘){ stage(‘code pull‘) { checkout([$class: ‘GitSCM‘, branches: [[name: ‘test_eureka-server‘]], doGenerateSubmoduleConfigurations: false, extensions: [], submoduleCfg: [], userRemoteConfigs: [[credentialsId: ‘bf8a2a98-bb4f-461e-be46-2b49702d19b0‘, url: ‘ssh://git@gitlab.baidu.com:22/eureka-server.git‘]]]) } stage(‘code Build‘) { sh ‘mvn -f pom.xml clean package -Pdev -Dmaven.test.skip=true‘ } stage(‘code deploy‘) { sh ‘ansible-playbook -v /opt/ansible/test/deploy_standard_template.yml -e "HOSTS=test_java JOB_NAME=${JOB_NAME} BUILD_NUMBER=${BUILD_NUMBER} ENV=test PROJECT_NAME=eureka-server PREFIX=eureka-server PORT=8761"‘ } }else{ stage(‘code rollback‘) { sh ‘ansible-playbook -v /opt/ansible/test/rollback_standard_template.yml -e "HOSTS=test_java ENV=test PROJECT_NAME=eureka-server PORT=8761 BUILD_ID=${BUILD_ID}"‘ } } }
代码解释:
node {} 这里面,是Scripted Pipeline语法的主要构成部分。
if (env.Status == ‘Deploy‘){} 这里做了判断,判断是否发布?Status 就是上面我们参数化构建制定的变量。必须通过env.变量名来获取。
stage(‘code pull‘) {} 表示code pull阶段
checkout() 表示拉取代码
$class: ‘GitSCM‘ 表示使用git方式拉取代码。SCM,分git,svn等等。SCM英文全称是:供应链管理。这里我们指代码仓库管理
branches: [[name: ‘test_eureka-server‘]] 表示指定分支为:test_eureka-server
doGenerateSubmoduleConfigurations: false 不生成子模块设置
extensions 扩展设置
submoduleCfg 子模块设置
userRemoteConfigs 用户远程设置,主要设置gitlab相关配置
credentialsId 凭证id,点击jenkins-->凭证,就可看到。通过这个用户,就有权限从gitlab上面拉取代码了。

url gitlab项目地址,可以是ssh方式,也可以是http方式。
stage(‘code Build‘) {} 代码构建,这里面,主要是指定pom.xml文件,编译出jar包。
stage(‘code deploy‘) {} 代码发布,执行shell命令。
stage(‘code rollback‘) {} 代码回滚,执行shell命令。
点击页面的构建

点击构建
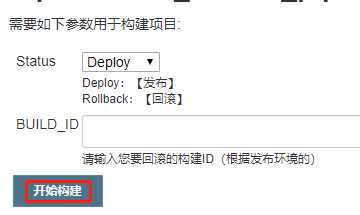
效果如下:
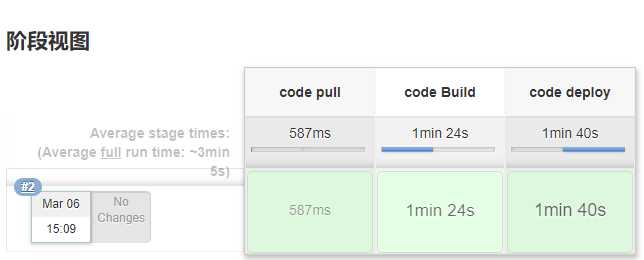
如果安装了Blue Ocean插件,点击左侧的Blue Ocean

效果如下:

如果不考虑回滚, pipeline可以精简一些,比如:


node { stage(‘code pull‘) { checkout([$class: ‘GitSCM‘, branches: [[name: ‘test_eureka-server‘]], doGenerateSubmoduleConfigurations: false, extensions: [], submoduleCfg: [], userRemoteConfigs: [[credentialsId: ‘bf8a2a98-bb4f-461e-be46-2b49702d19b0‘, url: ‘ssh://git@gitlab.baidu.com:22/eureka-server.git‘]]]) } stage(‘code Build‘) { sh ‘mvn -f pom.xml clean package -Pdev -Dmaven.test.skip=true‘ } stage(‘code deploy‘) { sh ‘ansible-playbook -v /opt/ansible/test/deploy_standard_template.yml -e "HOSTS=test_java JOB_NAME=${JOB_NAME} BUILD_NUMBER=${BUILD_NUMBER} ENV=test PROJECT_NAME=eureka-server PREFIX=eureka-server PORT=8761"‘ } }
本文参考链接:
https://www.cnblogs.com/shenh/p/8963688.html
https://blog.csdn.net/diantun00/article/details/81075007
https://www.cnblogs.com/woshimrf/p/gitlab-with-jenkins.html
以上是关于jenkins pipeline持续集成的主要内容,如果未能解决你的问题,请参考以下文章