Spark RDD理解
Posted locea-article
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了Spark RDD理解相关的知识,希望对你有一定的参考价值。
目录
RDD简介
RDD是弹性分布式数据集(Resilient Distributed Dataset),能在并行计算阶段进行高效的数据共享;RDD还提供了一种粗粒度接口,该接口会将相同的操作应用到多个数据集上并记录创建数据集的‘血统’,从而在不需要存储真正的数据的情况下,达到高效的容错性。
RDD操作类别
RDD操作大致可分为四类:创建操作、转换操作、控制操作、行动操作;在这些大类的基础上还能划为些细类,下面是大部分的RDD操作,以及其细类划分情况。

RDD分区
分区的多少决定RDD的并行粒度;分区是逻辑概念,分区前后可能存储在同一内存;RDD分区之间存在依赖关系,分为宽依赖和窄依赖
宽依赖:多个子RDD分区依赖一个父RDD分区;如join,groupBy操作;
窄依赖:窄依赖:每个父RDD的分区都至多被被一个子RDD的分区使用;如map操作一对一关系
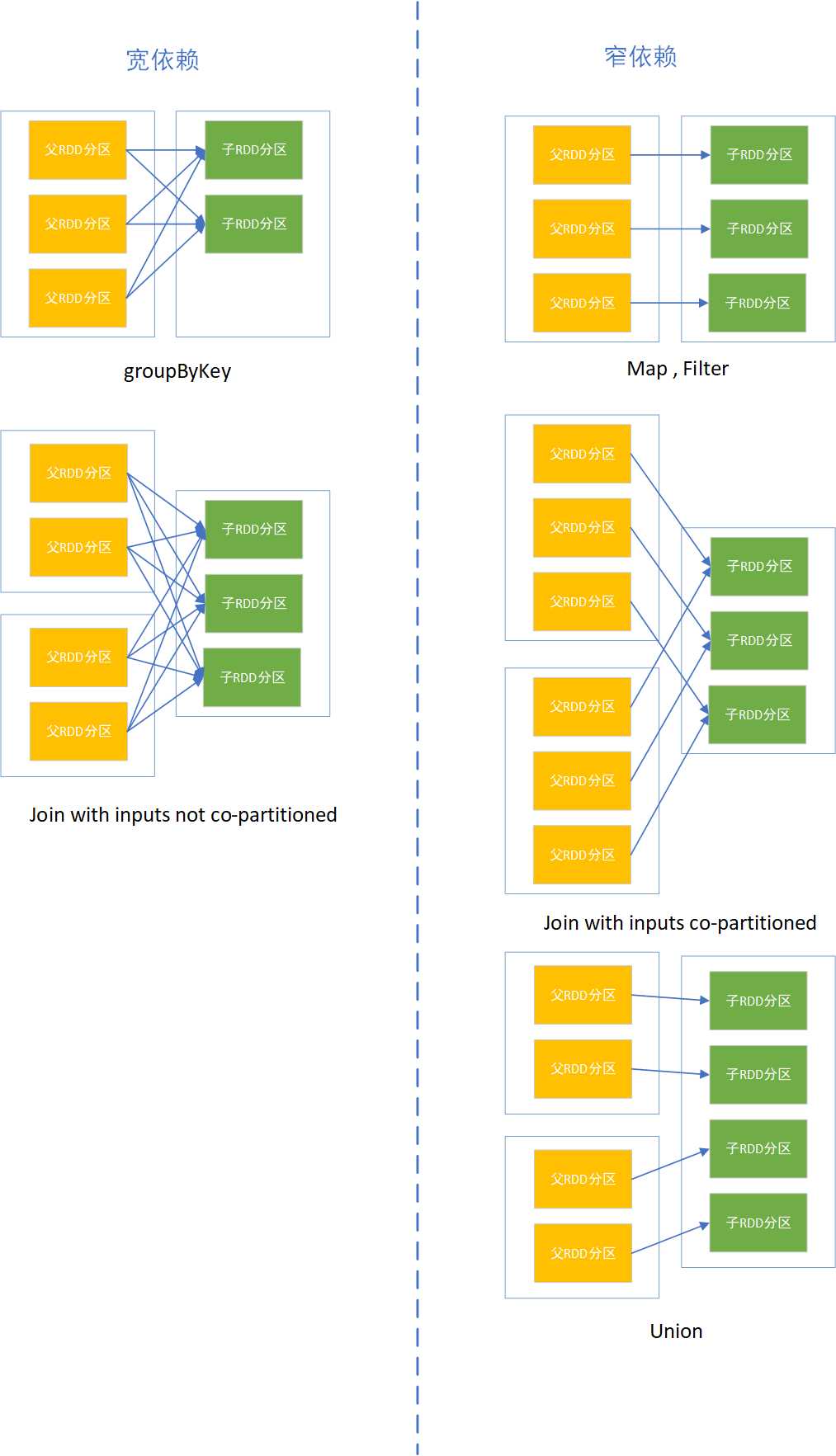
宽依赖和窄依赖作用
窄依赖允许在单个集群节点上流水线式执行,这个节点可以计算所有父级分区;而且,在窄依赖中,节点失败后的恢复更加高效
宽依赖的继承关系中,单个失败节点可能导致一个RDD的所有祖先RDD中的一些分区丢失,导致计算重新执行
RDD分区划分器
spark中RDD计算是以分区为单位的,而计算函数都是在迭代器中复合;分区计算一般使用mapPartitions等计算。
spark提供了两种默认的分区划分器,一种是HashPartitioner(哈希分区划分器),另一种是RangePartitioner(范围分区划分器)
RDD到调度
RDD转换操作属于lazy级别,会延迟执行,作业的提交是由行动操作触发。当执行RDD行动操作时触发作业的提交,然后会根据RDD之间的关系构建DAG(有向无环图),再提交给DAGScheduler进行解析;解析之后会得到调度阶段Stage,也就是taskSet;最后TashScheduler进一步解析得到task,task将会在Worker中Executor里面执行。
以上是关于Spark RDD理解的主要内容,如果未能解决你的问题,请参考以下文章